 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseFusion: Robust Object-in-Hand Pose Estimation with SelectLSTM
Apr 10, 2023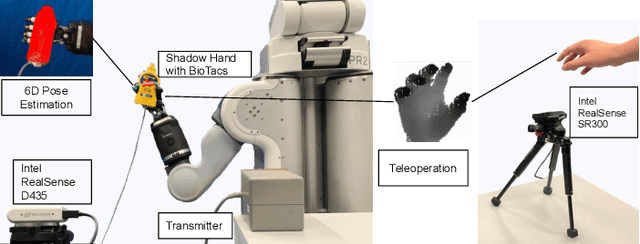
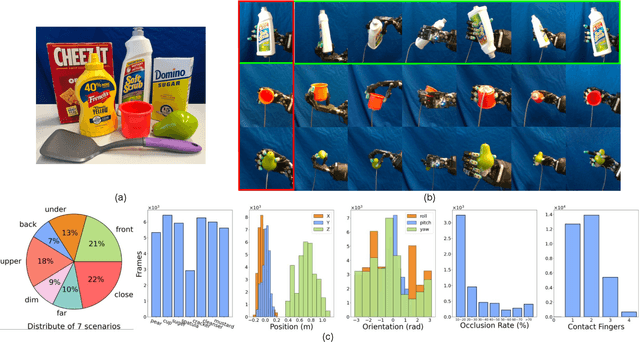

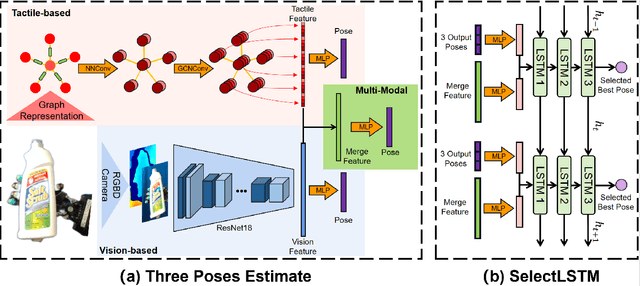
Accurate estimation of the relative pose between an object and a robot hand is critical for many manipulation tasks. However, most of the existing object-in-hand pose datasets use two-finger grippers and also assume that the object remains fixed in the hand without any relative movements, which is not representative of real-world scenarios. To address this issue, a 6D object-in-hand pose dataset is proposed using a teleoperation method with an anthropomorphic Shadow Dexterous hand. Our dataset comprises RGB-D images, proprioception and tactile data, covering diverse grasping poses, finger contact states, and object occlusions. To overcome the significant hand occlusion and limited tactile sensor contact in real-world scenarios, we propose PoseFusion, a hybrid multi-modal fusion approach that integrates the information from visual and tactile perception channels. PoseFusion generates three candidate object poses from three estimators (tactile only, visual only, and visuo-tactile fusion), which are then filtered by a SelectLSTM network to select the optimal pose, avoiding inferior fusion poses resulting from modality collapse. Extensive experiments demonstrate the robustness and advantages of our framework. All data and codes are available on the project website: https://elevenjiang1.github.io/ObjectInHand-Dataset/
Nearest Neighborhood-Based Deep Clustering for Source Data-absent Unsupervised Domain Adaptation
Aug 03, 2021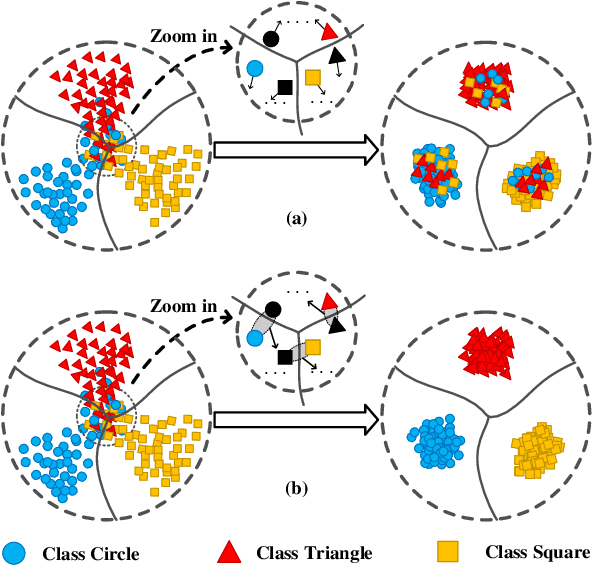
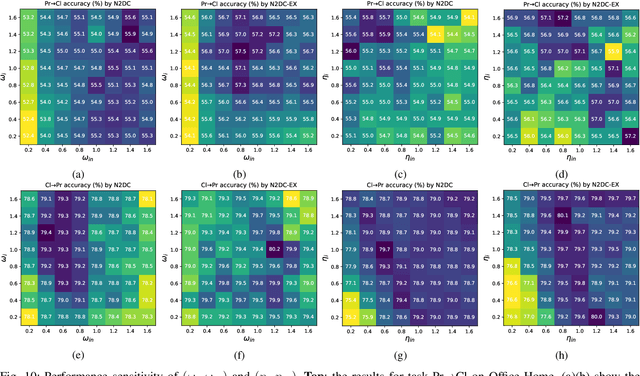
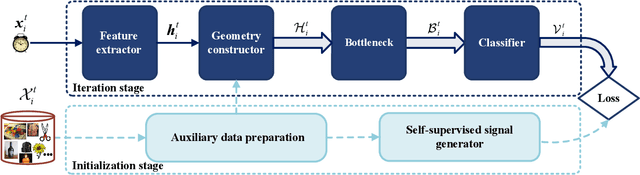
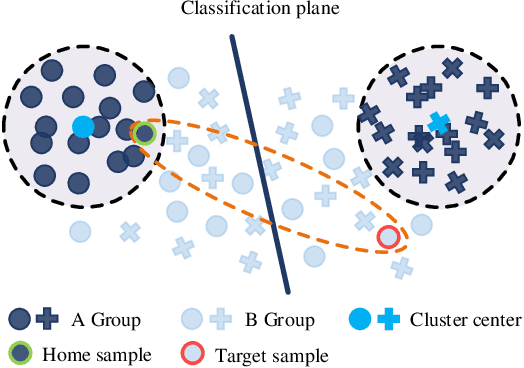
In the classic setting of unsupervised domain adaptation (UDA), the labeled source data are available in the training phase. However, in many real-world scenarios, owing to some reasons such as privacy protection and information security, the source data is inaccessible, and only a model trained on the source domain is available. This paper proposes a novel deep clustering method for this challenging task. Aiming at the dynamical clustering at feature-level, we introduce extra constraints hidden in the geometric structure between data to assist the process. Concretely, we propose a geometry-based constraint, named semantic consistency on the nearest neighborhood (SCNNH), and use it to encourage robust clustering. To reach this goal, we construct the nearest neighborhood for every target data and take it as the fundamental clustering unit by building our objective on the geometry. Also, we develop a more SCNNH-compliant structure with an additional semantic credibility constraint, named semantic hyper-nearest neighborhood (SHNNH). After that, we extend our method to this new geometry. Extensive experiments on three challenging UDA datasets indicate that our method achieves state-of-the-art results. The proposed method has significant improvement on all datasets (as we adopt SHNNH, the average accuracy increases by over 3.0% on the large-scaled dataset). Code is available at https://github.com/tntek/N2DCX.
Self-Adapting Recurrent Models for Object Pushing from Learning in Simulation
Jul 27, 2020
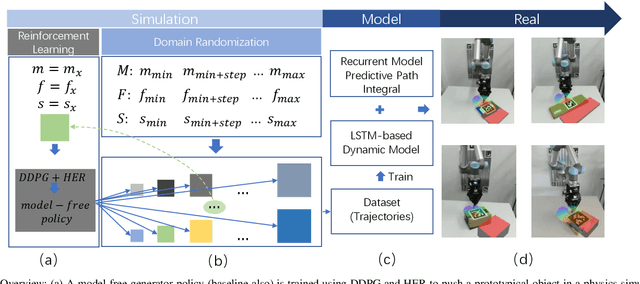
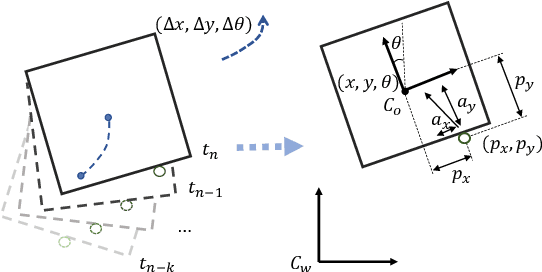
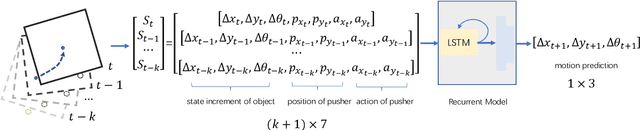
Planar pushing remains a challenging research topic, where building the dynamic model of the interaction is the core issue. Even an accurate analytical dynamic model is inherently unstable because physics parameters such as inertia and friction can only be approximated. Data-driven models usually rely on large amounts of training data, but data collection is time consuming when working with real robots. In this paper, we collect all training data in a physics simulator and build an LSTM-based model to fit the pushing dynamics. Domain Randomization is applied to capture the pushing trajectories of a generalized class of objects. When executed on the real robot, the trained recursive model adapts to the tracked object's real dynamics within a few steps. We propose the algorithm \emph{Recurrent} Model Predictive Path Integral (RMPPI) as a variation of the original MPPI approach, employing state-dependent recurrent models. As a comparison, we also train a Deep Deterministic Policy Gradient (DDPG) network as a model-free baseline, which is also used as the action generator in the data collection phase. During policy training, Hindsight Experience Replay is used to improve exploration efficiency. Pushing experiments on our UR5 platform demonstrate the model's adaptability and the effectiveness of the proposed framework.
A Mobile Robot Hand-Arm Teleoperation System by Vision and IMU
Mar 11, 2020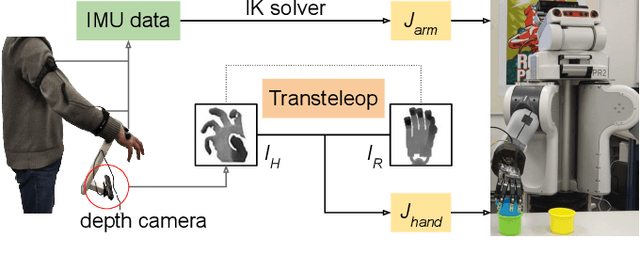
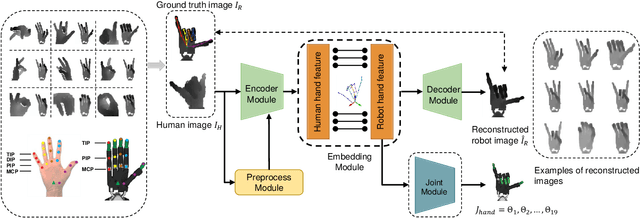


In this paper, we present a multimodal mobile teleoperation system that consists of a novel vision-based hand pose regression network (Transteleop) and an IMU-based arm tracking method. Transteleop observes the human hand through a low-cost depth camera and generates not only joint angles but also depth images of paired robot hand poses through an image-to-image translation process. A keypoint-based reconstruction loss explores the resemblance in appearance and anatomy between human and robotic hands and enriches the local features of reconstructed images. A wearable camera holder enables simultaneous hand-arm control and facilitates the mobility of the whole teleoperation system. Network evaluation results on a test dataset and a variety of complex manipulation tasks that go beyond simple pick-and-place operations show the efficiency and stability of our multimodal teleoperation system.
Robust Robotic Pouring using Audition and Haptics
Feb 29, 2020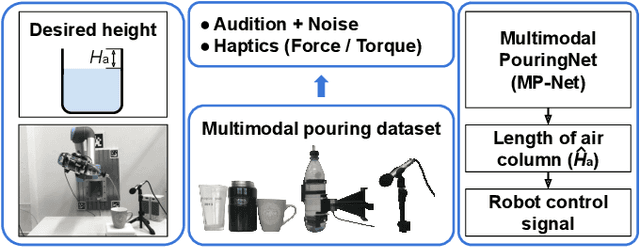
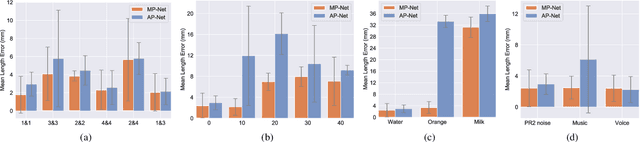
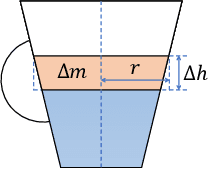
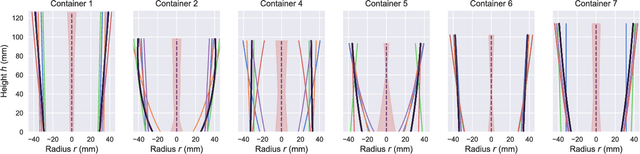
Robust and accurate estimation of liquid height lies as an essential part of pouring tasks for service robots. However, vision-based methods often fail in occluded conditions while audio-based methods cannot work well in a noisy environment. We instead propose a multimodal pouring network (MP-Net) that is able to robustly predict liquid height by conditioning on both audition and haptics input. MP-Net is trained on a self-collected multimodal pouring dataset. This dataset contains 300 robot pouring recordings with audio and force/torque measurements for three types of target containers. We also augment the audio data by inserting robot noise. We evaluated MP-Net on our collected dataset and a wide variety of robot experiments. Both network training results and robot experiments demonstrate that MP-Net is robust against noise and changes to the task and environment. Moreover, we further combine the predicted height and force data to estimate the shape of the target container.
Making Sense of Audio Vibration for Liquid Height Estimation in Robotic Pouring
Mar 02, 2019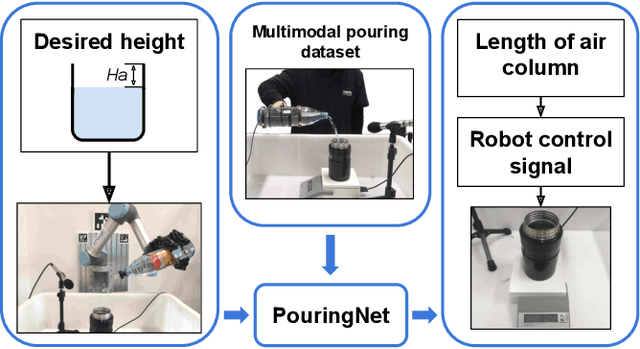
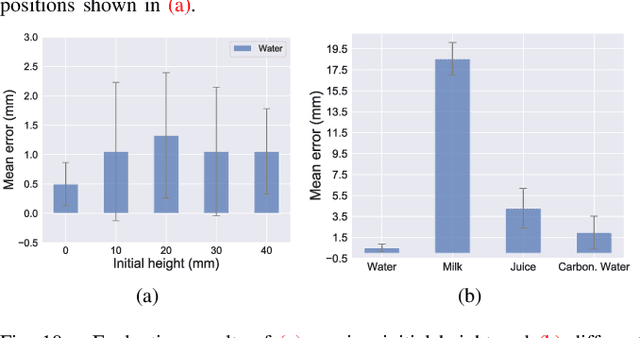
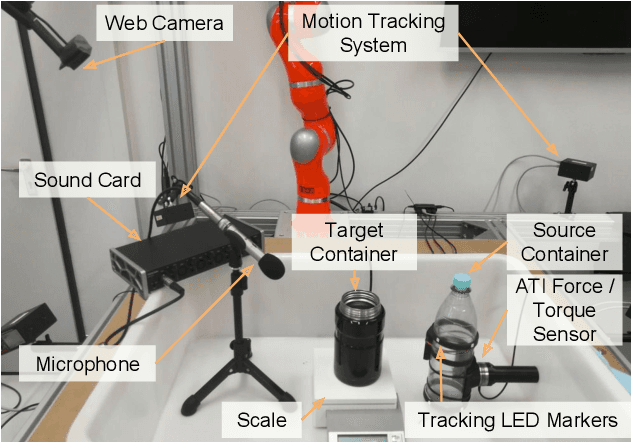
In this paper, we focus on the challenging perception problem in robotic pouring. Most of the existing approaches either leverage visual or haptic information. However, these techniques may suffer from poor generalization performances on opaque containers or concerning measuring precision. To tackle these drawbacks, we propose to make use of audio vibration sensing and design a deep neural network PouringNet to predict the liquid height from the audio fragment during the robotic pouring task. PouringNet is trained on our collected real-world pouring dataset with multimodal sensing data, which contains more than 3000 recordings of audio, force feedback, video and trajectory data of the human hand that performs the pouring task. Each record represents a complete pouring procedure. We conduct several evaluations on PouringNet with our dataset and robotic hardware. The results demonstrate that our PouringNet generalizes well across different liquid containers, positions of the audio receiver, initial liquid heights and types of liquid, and facilitates a more robust and accurate audio-based perception for robotic pouring.