 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Inertial Poser: Multi-Person Pose and Global Translation from Sparse Inertial Sensors and Ultra-Wideband Ranging
Oct 24, 2025Tracking human full-body motion using sparse wearable inertial measurement units (IMUs) overcomes the limitations of occlusion and instrumentation of the environment inherent in vision-based approaches. However, purely IMU-based tracking compromises translation estimates and accurate relative positioning between individuals, as inertial cues are inherently self-referential and provide no direct spatial reference for others. In this paper, we present a novel approach for robustly estimating body poses and global translation for multiple individuals by leveraging the distances between sparse wearable sensors - both on each individual and across multiple individuals. Our method Group Inertial Poser estimates these absolute distances between pairs of sensors from ultra-wideband ranging (UWB) and fuses them with inertial observations as input into structured state-space models to integrate temporal motion patterns for precise 3D pose estimation. Our novel two-step optimization further leverages the estimated distances for accurately tracking people's global trajectories through the world. We also introduce GIP-DB, the first IMU+UWB dataset for two-person tracking, which comprises 200 minutes of motion recordings from 14 participants. In our evaluation, Group Inertial Poser outperforms previous state-of-the-art methods in accuracy and robustness across synthetic and real-world data, showing the promise of IMU+UWB-based multi-human motion capture in the wild. Code, models, dataset: https://github.com/eth-siplab/GroupInertialPoser
Human Motion Capture from Loose and Sparse Inertial Sensors with Garment-aware Diffusion Models
Jun 18, 2025Motion capture using sparse inertial sensors has shown great promise due to its portability and lack of occlusion issues compared to camera-based tracking. Existing approaches typically assume that IMU sensors are tightly attached to the human body. However, this assumption often does not hold in real-world scenarios. In this paper, we present a new task of full-body human pose estimation using sparse, loosely attached IMU sensors. To solve this task, we simulate IMU recordings from an existing garment-aware human motion dataset. We developed transformer-based diffusion models to synthesize loose IMU data and estimate human poses based on this challenging loose IMU data. In addition, we show that incorporating garment-related parameters while training the model on simulated loose data effectively maintains expressiveness and enhances the ability to capture variations introduced by looser or tighter garments. Experiments show that our proposed diffusion methods trained on simulated and synthetic data outperformed the state-of-the-art methods quantitatively and qualitatively, opening up a promising direction for future research.
Evolution of Optimization Algorithms for Global Placement via Large Language Models
Apr 18, 2025Optimization algorithms are widely employed to tackle complex problems, but designing them manually is often labor-intensive and requires significant expertise. Global placement is a fundamental step in electronic design automation (EDA). While analytical approaches represent the state-of-the-art (SOTA) in global placement, their core optimization algorithms remain heavily dependent on heuristics and customized components, such as initialization strategies, preconditioning methods, and line search techniques. This paper presents an automated framework that leverages large language models (LLM) to evolve optimization algorithms for global placement. We first generate diverse candidate algorithms using LLM through carefully crafted prompts. Then we introduce an LLM-based genetic flow to evolve selected candidate algorithms. The discovered optimization algorithms exhibit substantial performance improvements across many benchmarks. Specifically, Our design-case-specific discovered algorithms achieve average HPWL improvements of \textbf{5.05\%}, \text{5.29\%} and \textbf{8.30\%} on MMS, ISPD2005 and ISPD2019 benchmarks, and up to \textbf{17\%} improvements on individual cases. Additionally, the discovered algorithms demonstrate good generalization ability and are complementary to existing parameter-tuning methods.
EgoSim: An Egocentric Multi-view Simulator and Real Dataset for Body-worn Cameras during Motion and Activity
Feb 25, 2025Research on egocentric tasks in computer vision has mostly focused on head-mounted cameras, such as fisheye cameras or embedded cameras inside immersive headsets. We argue that the increasing miniaturization of optical sensors will lead to the prolific integration of cameras into many more body-worn devices at various locations. This will bring fresh perspectives to established tasks in computer vision and benefit key areas such as human motion tracking, body pose estimation, or action recognition -- particularly for the lower body, which is typically occluded. In this paper, we introduce EgoSim, a novel simulator of body-worn cameras that generates realistic egocentric renderings from multiple perspectives across a wearer's body. A key feature of EgoSim is its use of real motion capture data to render motion artifacts, which are especially noticeable with arm- or leg-worn cameras. In addition, we introduce MultiEgoView, a dataset of egocentric footage from six body-worn cameras and ground-truth full-body 3D poses during several activities: 119 hours of data are derived from AMASS motion sequences in four high-fidelity virtual environments, which we augment with 5 hours of real-world motion data from 13 participants using six GoPro cameras and 3D body pose references from an Xsens motion capture suit. We demonstrate EgoSim's effectiveness by training an end-to-end video-only 3D pose estimation network. Analyzing its domain gap, we show that our dataset and simulator substantially aid training for inference on real-world data. EgoSim code & MultiEgoView dataset: https://siplab.org/projects/EgoSim
TapType: Ten-finger text entry on everyday surfaces via Bayesian inference
Oct 08, 2024



Despite the advent of touchscreens, typing on physical keyboards remains most efficient for entering text, because users can leverage all fingers across a full-size keyboard for convenient typing. As users increasingly type on the go, text input on mobile and wearable devices has had to compromise on full-size typing. In this paper, we present TapType, a mobile text entry system for full-size typing on passive surfaces--without an actual keyboard. From the inertial sensors inside a band on either wrist, TapType decodes and relates surface taps to a traditional QWERTY keyboard layout. The key novelty of our method is to predict the most likely character sequences by fusing the finger probabilities from our Bayesian neural network classifier with the characters' prior probabilities from an n-gram language model. In our online evaluation, participants on average typed 19 words per minute with a character error rate of 0.6% after 30 minutes of training. Expert typists thereby consistently achieved more than 25 WPM at a similar error rate. We demonstrate applications of TapType in mobile use around smartphones and tablets, as a complement to interaction in situated Mixed Reality outside visual control, and as an eyes-free mobile text input method using an audio feedback-only interface.
Ultra Inertial Poser: Scalable Motion Capture and Tracking from Sparse Inertial Sensors and Ultra-Wideband Ranging
Apr 30, 2024While camera-based capture systems remain the gold standard for recording human motion, learning-based tracking systems based on sparse wearable sensors are gaining popularity. Most commonly, they use inertial sensors, whose propensity for drift and jitter have so far limited tracking accuracy. In this paper, we propose Ultra Inertial Poser, a novel 3D full body pose estimation method that constrains drift and jitter in inertial tracking via inter-sensor distances. We estimate these distances across sparse sensor setups using a lightweight embedded tracker that augments inexpensive off-the-shelf 6D inertial measurement units with ultra-wideband radio-based ranging$-$dynamically and without the need for stationary reference anchors. Our method then fuses these inter-sensor distances with the 3D states estimated from each sensor Our graph-based machine learning model processes the 3D states and distances to estimate a person's 3D full body pose and translation. To train our model, we synthesize inertial measurements and distance estimates from the motion capture database AMASS. For evaluation, we contribute a novel motion dataset of 10 participants who performed 25 motion types, captured by 6 wearable IMU+UWB trackers and an optical motion capture system, totaling 200 minutes of synchronized sensor data (UIP-DB). Our extensive experiments show state-of-the-art performance for our method over PIP and TIP, reducing position error from $13.62$ to $10.65cm$ ($22\%$ better) and lowering jitter from $1.56$ to $0.055km/s^3$ (a reduction of $97\%$).
EgoPoser: Robust Real-Time Ego-Body Pose Estimation in Large Scenes
Aug 17, 2023Full-body ego-pose estimation from head and hand poses alone has become an active area of research to power articulate avatar representation on headset-based platforms. However, existing methods over-rely on the confines of the motion-capture spaces in which datasets were recorded, while simultaneously assuming continuous capture of joint motions and uniform body dimensions. In this paper, we propose EgoPoser, which overcomes these limitations by 1) rethinking the input representation for headset-based ego-pose estimation and introducing a novel motion decomposition method that predicts full-body pose independent of global positions, 2) robustly modeling body pose from intermittent hand position and orientation tracking only when inside a headset's field of view, and 3) generalizing across various body sizes for different users. Our experiments show that EgoPoser outperforms state-of-the-art methods both qualitatively and quantitatively, while maintaining a high inference speed of over 600 fps. EgoPoser establishes a robust baseline for future work, where full-body pose estimation needs no longer rely on outside-in capture and can scale to large-scene environments.
Restore Anything Pipeline: Segment Anything Meets Image Restoration
May 22, 2023
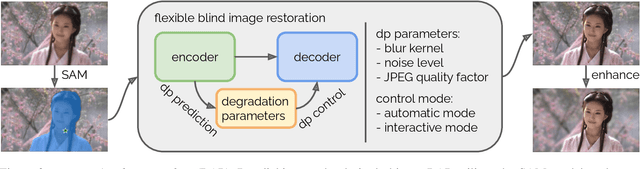


Recent image restoration methods have produced significant advancements using deep learning. However, existing methods tend to treat the whole image as a single entity, failing to account for the distinct objects in the image that exhibit individual texture properties. Existing methods also typically generate a single result, which may not suit the preferences of different users. In this paper, we introduce the Restore Anything Pipeline (RAP), a novel interactive and per-object level image restoration approach that incorporates a controllable model to generate different results that users may choose from. RAP incorporates image segmentation through the recent Segment Anything Model (SAM) into a controllable image restoration model to create a user-friendly pipeline for several image restoration tasks. We demonstrate the versatility of RAP by applying it to three common image restoration tasks: image deblurring, image denoising, and JPEG artifact removal. Our experiments show that RAP produces superior visual results compared to state-of-the-art methods. RAP represents a promising direction for image restoration, providing users with greater control, and enabling image restoration at an object level.
AvatarPoser: Articulated Full-Body Pose Tracking from Sparse Motion Sensing
Jul 27, 2022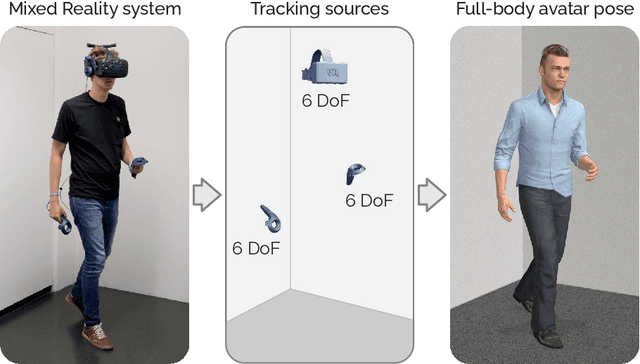
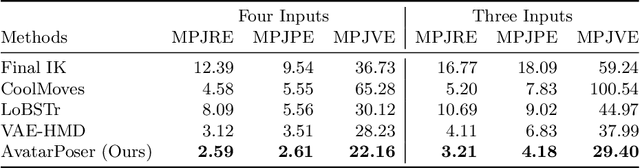
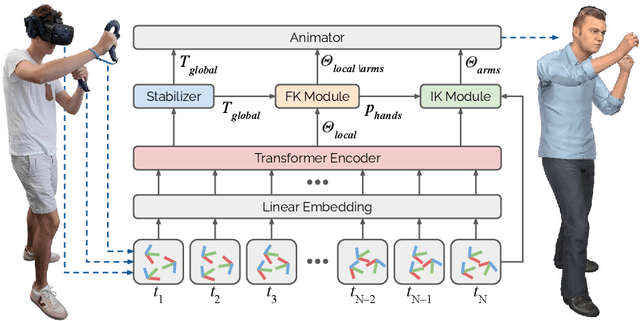
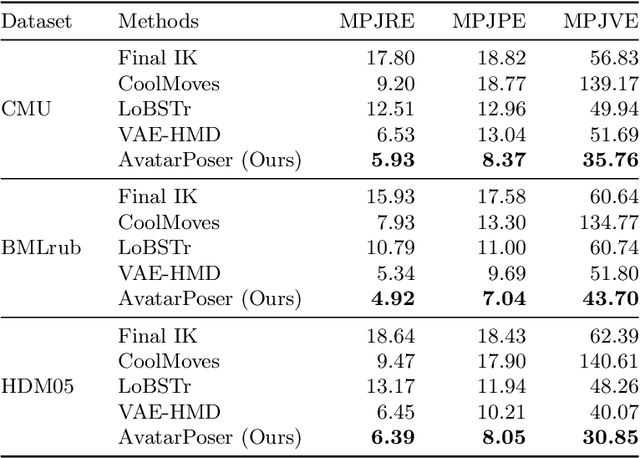
Today's Mixed Reality head-mounted displays track the user's head pose in world space as well as the user's hands for interaction in both Augmented Reality and Virtual Reality scenarios. While this is adequate to support user input, it unfortunately limits users' virtual representations to just their upper bodies. Current systems thus resort to floating avatars, whose limitation is particularly evident in collaborative settings. To estimate full-body poses from the sparse input sources, prior work has incorporated additional trackers and sensors at the pelvis or lower body, which increases setup complexity and limits practical application in mobile settings. In this paper, we present AvatarPoser, the first learning-based method that predicts full-body poses in world coordinates using only motion input from the user's head and hands. Our method builds on a Transformer encoder to extract deep features from the input signals and decouples global motion from the learned local joint orientations to guide pose estimation. To obtain accurate full-body motions that resemble motion capture animations, we refine the arm joints' positions using an optimization routine with inverse kinematics to match the original tracking input. In our evaluation, AvatarPoser achieved new state-of-the-art results in evaluations on large motion capture datasets (AMASS). At the same time, our method's inference speed supports real-time operation, providing a practical interface to support holistic avatar control and representation for Metaverse applications.
Unsupervised Learning of 3D Semantic Keypoints with Mutual Reconstruction
Mar 19, 2022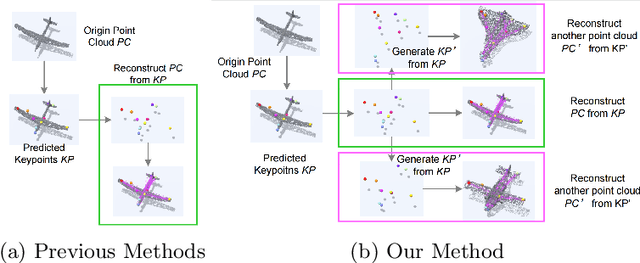
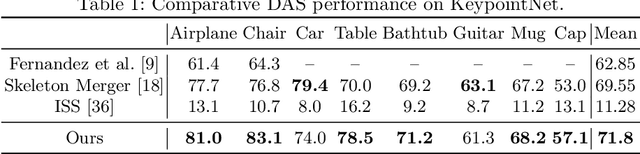
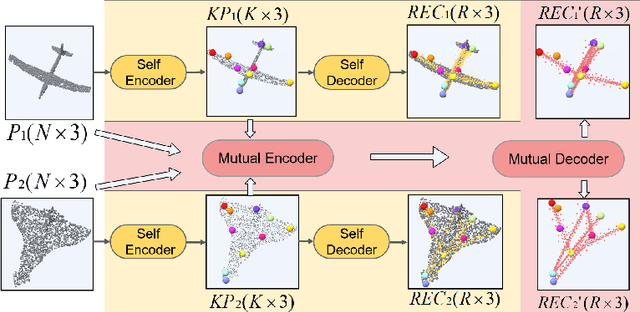
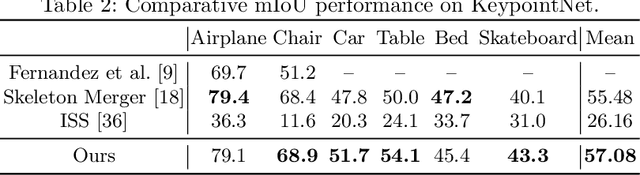
Semantic 3D keypoints are category-level semantic consistent points on 3D objects. Detecting 3D semantic keypoints is a foundation for a number of 3D vision tasks but remains challenging, due to the ambiguity of semantic information, especially when the objects are represented by unordered 3D point clouds. Existing unsupervised methods tend to generate category-level keypoints in implicit manners, making it difficult to extract high-level information, such as semantic labels and topology. From a novel mutual reconstruction perspective, we present an unsupervised method to generate consistent semantic keypoints from point clouds explicitly. To achieve this, the proposed model predicts keypoints that not only reconstruct the object itself but also reconstruct other instances in the same category. To the best of our knowledge, the proposed method is the first to mine 3D semantic consistent keypoints from a mutual reconstruction view. Experiments under various evaluation metrics as well as comparisons with the state-of-the-arts demonstrate the efficacy of our new solution to mining semantic consistent keypoints with mutual reconstruction.