 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint & Grasp: Flexible Selection of Out-of-Reach Objects Through Probabilistic Cue Integration
Apr 24, 2026Selecting out-of-reach objects is a fundamental task in mixed reality (MR). Existing methods rely on a single cue or deterministically fuse multiple cues, leading to performance degradation when the dominant cue becomes unreliable. In this work, we introduce a probabilistic cue integration framework that enables flexible combination of multiple user-generated cues for intent inference. Inspired by natural grasping behavior, we instantiate the framework with pointing direction and grasp gestures as a new interaction technique, Point&Grasp. To this end, we collect the Out-of-Reach Grasping (ORG) dataset to train a robust likelihood model of the gestural cue, which captures grasping patterns not present in existing in-reach datasets. User studies demonstrate that our selection method with cue integration not only improves accuracy and speed over single-cue baselines, but also remains practically effective compared to state-of-the-art methods across various sources of ambiguity. The dataset and code are available at https://github.com/drlxj/point-and-grasp.
Temporal Cardiovascular Dynamics for Improved PPG-Based Heart Rate Estimation
Oct 31, 2025The oscillations of the human heart rate are inherently complex and non-linear -- they are best described by mathematical chaos, and they present a challenge when applied to the practical domain of cardiovascular health monitoring in everyday life. In this work, we study the non-linear chaotic behavior of heart rate through mutual information and introduce a novel approach for enhancing heart rate estimation in real-life conditions. Our proposed approach not only explains and handles the non-linear temporal complexity from a mathematical perspective but also improves the deep learning solutions when combined with them. We validate our proposed method on four established datasets from real-life scenarios and compare its performance with existing algorithms thoroughly with extensive ablation experiments. Our results demonstrate a substantial improvement, up to 40\%, of the proposed approach in estimating heart rate compared to traditional methods and existing machine-learning techniques while reducing the reliance on multiple sensing modalities and eliminating the need for post-processing steps.
Learning Without Augmenting: Unsupervised Time Series Representation Learning via Frame Projections
Oct 26, 2025Self-supervised learning (SSL) has emerged as a powerful paradigm for learning representations without labeled data. Most SSL approaches rely on strong, well-established, handcrafted data augmentations to generate diverse views for representation learning. However, designing such augmentations requires domain-specific knowledge and implicitly imposes representational invariances on the model, which can limit generalization. In this work, we propose an unsupervised representation learning method that replaces augmentations by generating views using orthonormal bases and overcomplete frames. We show that embeddings learned from orthonormal and overcomplete spaces reside on distinct manifolds, shaped by the geometric biases introduced by representing samples in different spaces. By jointly leveraging the complementary geometry of these distinct manifolds, our approach achieves superior performance without artificially increasing data diversity through strong augmentations. We demonstrate the effectiveness of our method on nine datasets across five temporal sequence tasks, where signal-specific characteristics make data augmentations particularly challenging. Without relying on augmentation-induced diversity, our method achieves performance gains of up to 15--20\% over existing self-supervised approaches. Source code: https://github.com/eth-siplab/Learning-with-FrameProjections
Group Inertial Poser: Multi-Person Pose and Global Translation from Sparse Inertial Sensors and Ultra-Wideband Ranging
Oct 24, 2025Tracking human full-body motion using sparse wearable inertial measurement units (IMUs) overcomes the limitations of occlusion and instrumentation of the environment inherent in vision-based approaches. However, purely IMU-based tracking compromises translation estimates and accurate relative positioning between individuals, as inertial cues are inherently self-referential and provide no direct spatial reference for others. In this paper, we present a novel approach for robustly estimating body poses and global translation for multiple individuals by leveraging the distances between sparse wearable sensors - both on each individual and across multiple individuals. Our method Group Inertial Poser estimates these absolute distances between pairs of sensors from ultra-wideband ranging (UWB) and fuses them with inertial observations as input into structured state-space models to integrate temporal motion patterns for precise 3D pose estimation. Our novel two-step optimization further leverages the estimated distances for accurately tracking people's global trajectories through the world. We also introduce GIP-DB, the first IMU+UWB dataset for two-person tracking, which comprises 200 minutes of motion recordings from 14 participants. In our evaluation, Group Inertial Poser outperforms previous state-of-the-art methods in accuracy and robustness across synthetic and real-world data, showing the promise of IMU+UWB-based multi-human motion capture in the wild. Code, models, dataset: https://github.com/eth-siplab/GroupInertialPoser
Human Motion Capture from Loose and Sparse Inertial Sensors with Garment-aware Diffusion Models
Jun 18, 2025Motion capture using sparse inertial sensors has shown great promise due to its portability and lack of occlusion issues compared to camera-based tracking. Existing approaches typically assume that IMU sensors are tightly attached to the human body. However, this assumption often does not hold in real-world scenarios. In this paper, we present a new task of full-body human pose estimation using sparse, loosely attached IMU sensors. To solve this task, we simulate IMU recordings from an existing garment-aware human motion dataset. We developed transformer-based diffusion models to synthesize loose IMU data and estimate human poses based on this challenging loose IMU data. In addition, we show that incorporating garment-related parameters while training the model on simulated loose data effectively maintains expressiveness and enhances the ability to capture variations introduced by looser or tighter garments. Experiments show that our proposed diffusion methods trained on simulated and synthetic data outperformed the state-of-the-art methods quantitatively and qualitatively, opening up a promising direction for future research.
Beyond Subjectivity: Continuous Cybersickness Detection Using EEG-based Multitaper Spectrum Estimation
Mar 27, 2025Virtual reality (VR) presents immersive opportunities across many applications, yet the inherent risk of developing cybersickness during interaction can severely reduce enjoyment and platform adoption. Cybersickness is marked by symptoms such as dizziness and nausea, which previous work primarily assessed via subjective post-immersion questionnaires and motion-restricted controlled setups. In this paper, we investigate the \emph{dynamic nature} of cybersickness while users experience and freely interact in VR. We propose a novel method to \emph{continuously} identify and quantitatively gauge cybersickness levels from users' \emph{passively monitored} electroencephalography (EEG) and head motion signals. Our method estimates multitaper spectrums from EEG, integrating specialized EEG processing techniques to counter motion artifacts, and, thus, tracks cybersickness levels in real-time. Unlike previous approaches, our method requires no user-specific calibration or personalization for detecting cybersickness. Our work addresses the considerable challenge of reproducibility and subjectivity in cybersickness research.
Exploring LLM Agents for Cleaning Tabular Machine Learning Datasets
Mar 09, 2025High-quality, error-free datasets are a key ingredient in building reliable, accurate, and unbiased machine learning (ML) models. However, real world datasets often suffer from errors due to sensor malfunctions, data entry mistakes, or improper data integration across multiple sources that can severely degrade model performance. Detecting and correcting these issues typically require tailor-made solutions and demand extensive domain expertise. Consequently, automation is challenging, rendering the process labor-intensive and tedious. In this study, we investigate whether Large Language Models (LLMs) can help alleviate the burden of manual data cleaning. We set up an experiment in which an LLM, paired with Python, is tasked with cleaning the training dataset to improve the performance of a learning algorithm without having the ability to modify the training pipeline or perform any feature engineering. We run this experiment on multiple Kaggle datasets that have been intentionally corrupted with errors. Our results show that LLMs can identify and correct erroneous entries, such as illogical values or outlier, by leveraging contextual information from other features within the same row, as well as feedback from previous iterations. However, they struggle to detect more complex errors that require understanding data distribution across multiple rows, such as trends and biases.
egoPPG: Heart Rate Estimation from Eye-Tracking Cameras in Egocentric Systems to Benefit Downstream Vision Tasks
Feb 28, 2025



Egocentric vision systems aim to understand the spatial surroundings and the wearer's behavior inside it, including motions, activities, and interaction with objects. Since a person's attention and situational responses are influenced by their physiological state, egocentric systems must also detect this state for better context awareness. In this paper, we propose egoPPG, a novel task for egocentric vision systems to extract a person's heart rate (HR) as a key indicator of the wearer's physiological state from the system's built-in sensors (e.g., eye tracking videos). We then propose EgoPulseFormer, a method that solely takes eye-tracking video as input to estimate a person's photoplethysmogram (PPG) from areas around the eyes to track HR values-without requiring additional or dedicated hardware. We demonstrate the downstream benefit of EgoPulseFormer on EgoExo4D, where we find that augmenting existing models with tracked HR values improves proficiency estimation by 14%. To train and validate EgoPulseFormer, we collected a dataset of 13+ hours of eye-tracking videos from Project Aria and contact-based blood volume pulse signals as well as an electrocardiogram (ECG) for ground-truth HR values. 25 participants performed diverse everyday activities such as office work, cooking, dancing, and exercising, which induced significant natural motion and HR variation (44-164 bpm). Our model robustly estimates HR (MAE=8.82 bpm) and captures patterns (r=0.81). Our results show how egocentric systems may unify environmental and physiological tracking to better understand user actions and internal states.
Shifting the Paradigm: A Diffeomorphism Between Time Series Data Manifolds for Achieving Shift-Invariancy in Deep Learning
Feb 27, 2025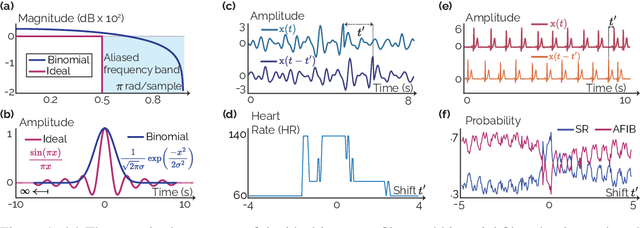
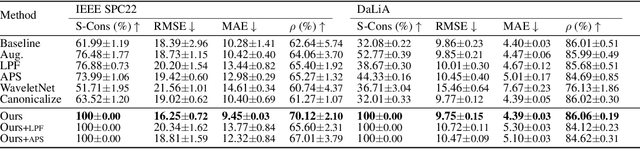
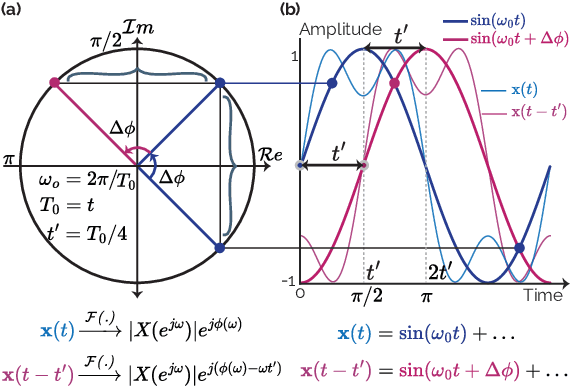
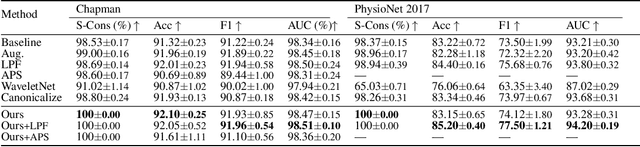
Deep learning models lack shift invariance, making them sensitive to input shifts that cause changes in output. While recent techniques seek to address this for images, our findings show that these approaches fail to provide shift-invariance in time series, where the data generation mechanism is more challenging due to the interaction of low and high frequencies. Worse, they also decrease performance across several tasks. In this paper, we propose a novel differentiable bijective function that maps samples from their high-dimensional data manifold to another manifold of the same dimension, without any dimensional reduction. Our approach guarantees that samples -- when subjected to random shifts -- are mapped to a unique point in the manifold while preserving all task-relevant information without loss. We theoretically and empirically demonstrate that the proposed transformation guarantees shift-invariance in deep learning models without imposing any limits to the shift. Our experiments on six time series tasks with state-of-the-art methods show that our approach consistently improves the performance while enabling models to achieve complete shift-invariance without modifying or imposing restrictions on the model's topology. The source code is available on \href{https://github.com/eth-siplab/Shifting-the-Paradigm}{GitHub}.
EgoSim: An Egocentric Multi-view Simulator and Real Dataset for Body-worn Cameras during Motion and Activity
Feb 25, 2025Research on egocentric tasks in computer vision has mostly focused on head-mounted cameras, such as fisheye cameras or embedded cameras inside immersive headsets. We argue that the increasing miniaturization of optical sensors will lead to the prolific integration of cameras into many more body-worn devices at various locations. This will bring fresh perspectives to established tasks in computer vision and benefit key areas such as human motion tracking, body pose estimation, or action recognition -- particularly for the lower body, which is typically occluded. In this paper, we introduce EgoSim, a novel simulator of body-worn cameras that generates realistic egocentric renderings from multiple perspectives across a wearer's body. A key feature of EgoSim is its use of real motion capture data to render motion artifacts, which are especially noticeable with arm- or leg-worn cameras. In addition, we introduce MultiEgoView, a dataset of egocentric footage from six body-worn cameras and ground-truth full-body 3D poses during several activities: 119 hours of data are derived from AMASS motion sequences in four high-fidelity virtual environments, which we augment with 5 hours of real-world motion data from 13 participants using six GoPro cameras and 3D body pose references from an Xsens motion capture suit. We demonstrate EgoSim's effectiveness by training an end-to-end video-only 3D pose estimation network. Analyzing its domain gap, we show that our dataset and simulator substantially aid training for inference on real-world data. EgoSim code & MultiEgoView dataset: https://siplab.org/projects/EgoSim