 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicHOI: Leveraging 3D Priors for Accurate Hand-object Reconstruction from Short Monocular Video Clips
Aug 07, 2025



Most RGB-based hand-object reconstruction methods rely on object templates, while template-free methods typically assume full object visibility. This assumption often breaks in real-world settings, where fixed camera viewpoints and static grips leave parts of the object unobserved, resulting in implausible reconstructions. To overcome this, we present MagicHOI, a method for reconstructing hands and objects from short monocular interaction videos, even under limited viewpoint variation. Our key insight is that, despite the scarcity of paired 3D hand-object data, large-scale novel view synthesis diffusion models offer rich object supervision. This supervision serves as a prior to regularize unseen object regions during hand interactions. Leveraging this insight, we integrate a novel view synthesis model into our hand-object reconstruction framework. We further align hand to object by incorporating visible contact constraints. Our results demonstrate that MagicHOI significantly outperforms existing state-of-the-art hand-object reconstruction methods. We also show that novel view synthesis diffusion priors effectively regularize unseen object regions, enhancing 3D hand-object reconstruction.
Regressor-Guided Image Editing Regulates Emotional Response to Reduce Online Engagement
Jan 21, 2025



Emotions are known to mediate the relationship between users' content consumption and their online engagement, with heightened emotional intensity leading to increased engagement. Building on this insight, we propose three regressor-guided image editing approaches aimed at diminishing the emotional impact of images. These include (i) a parameter optimization approach based on global image transformations known to influence emotions, (ii) an optimization approach targeting the style latent space of a generative adversarial network, and (iii) a diffusion-based approach employing classifier guidance and classifier-free guidance. Our findings demonstrate that approaches can effectively alter the emotional properties of images while maintaining high visual quality. Optimization-based methods primarily adjust low-level properties like color hues and brightness, whereas the diffusion-based approach introduces semantic changes, such as altering appearance or facial expressions. Notably, results from a behavioral study reveal that only the diffusion-based approach successfully elicits changes in viewers' emotional responses while preserving high perceived image quality. In future work, we will investigate the impact of these image adaptations on internet user behavior.
RILe: Reinforced Imitation Learning
Jun 12, 2024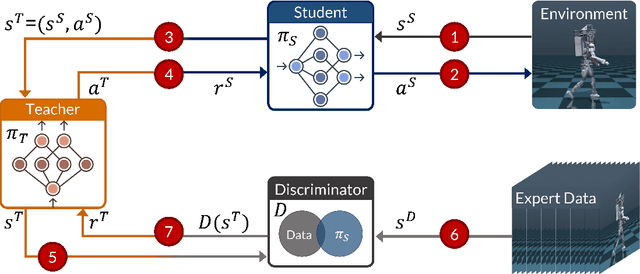
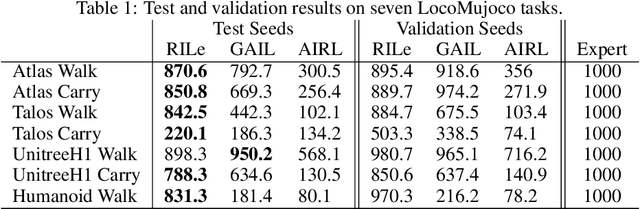
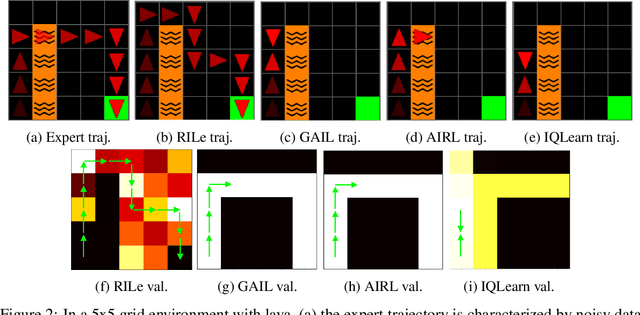
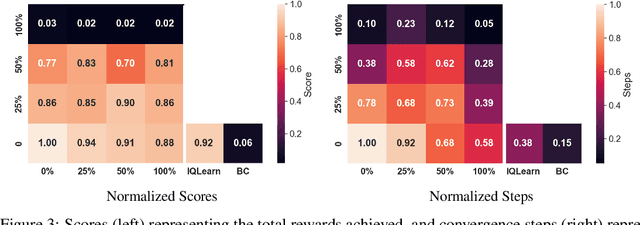
Reinforcement Learning has achieved significant success in generating complex behavior but often requires extensive reward function engineering. Adversarial variants of Imitation Learning and Inverse Reinforcement Learning offer an alternative by learning policies from expert demonstrations via a discriminator. Employing discriminators increases their data- and computational efficiency over the standard approaches; however, results in sensitivity to imperfections in expert data. We propose RILe, a teacher-student system that achieves both robustness to imperfect data and efficiency. In RILe, the student learns an action policy while the teacher dynamically adjusts a reward function based on the student's performance and its alignment with expert demonstrations. By tailoring the reward function to both performance of the student and expert similarity, our system reduces dependence on the discriminator and, hence, increases robustness against data imperfections. Experiments show that RILe outperforms existing methods by 2x in settings with limited or noisy expert data.
SemiMultiPose: A Semi-supervised Multi-animal Pose Estimation Framework
Apr 14, 2022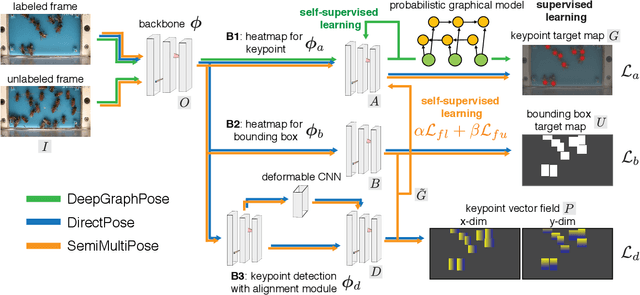


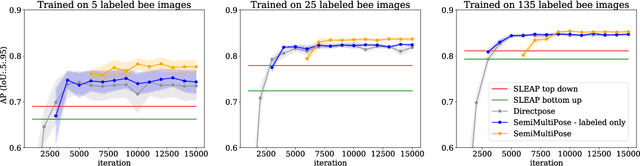
Multi-animal pose estimation is essential for studying animals' social behaviors in neuroscience and neuroethology. Advanced approaches have been proposed to support multi-animal estimation and achieve state-of-the-art performance. However, these models rarely exploit unlabeled data during training even though real world applications have exponentially more unlabeled frames than labeled frames. Manually adding dense annotations for a large number of images or videos is costly and labor-intensive, especially for multiple instances. Given these deficiencies, we propose a novel semi-supervised architecture for multi-animal pose estimation, leveraging the abundant structures pervasive in unlabeled frames in behavior videos to enhance training, which is critical for sparsely-labeled problems. The resulting algorithm will provide superior multi-animal pose estimation results on three animal experiments compared to the state-of-the-art baseline and exhibits more predictive power in sparsely-labeled data regimes.
Hierarchical Reinforcement Learning as a Model of Human Task Interleaving
Jan 04, 2020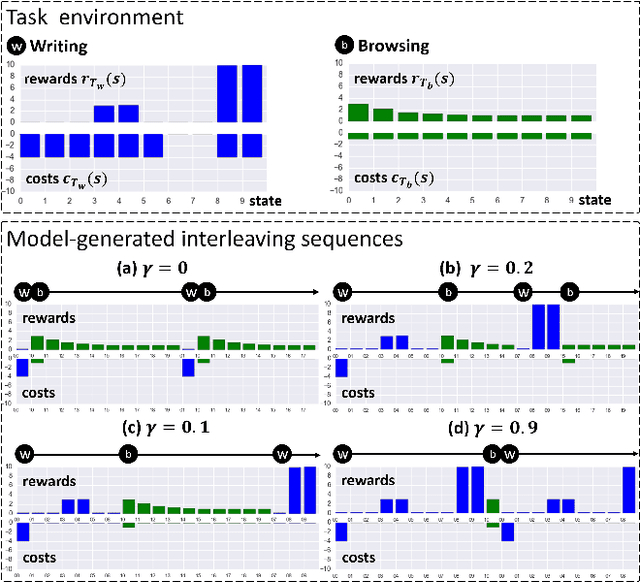
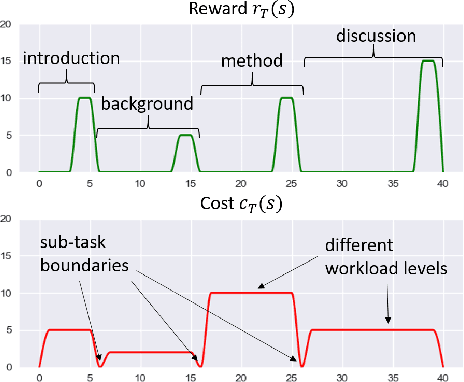
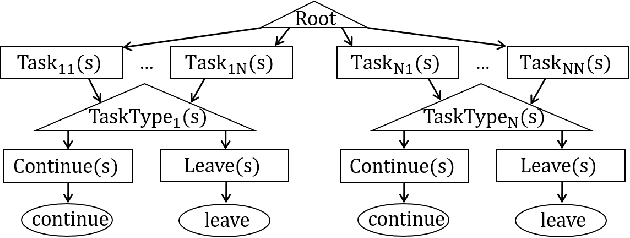
How do people decide how long to continue in a task, when to switch, and to which other task? Understanding the mechanisms that underpin task interleaving is a long-standing goal in the cognitive sciences. Prior work suggests greedy heuristics and a policy maximizing the marginal rate of return. However, it is unclear how such a strategy would allow for adaptation to everyday environments that offer multiple tasks with complex switch costs and delayed rewards. Here we develop a hierarchical model of supervisory control driven by reinforcement learning (RL). The supervisory level learns to switch using task-specific approximate utility estimates, which are computed on the lower level. A hierarchically optimal value function decomposition can be learned from experience, even in conditions with multiple tasks and arbitrary and uncertain reward and cost structures. The model reproduces known empirical effects of task interleaving. It yields better predictions of individual-level data than a myopic baseline in a six-task problem (N=211). The results support hierarchical RL as a plausible model of task interleaving.
Optimizing for Aesthetically Pleasing Quadrotor Camera Motion
Jun 27, 2019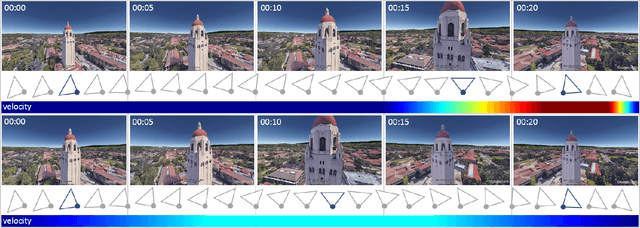
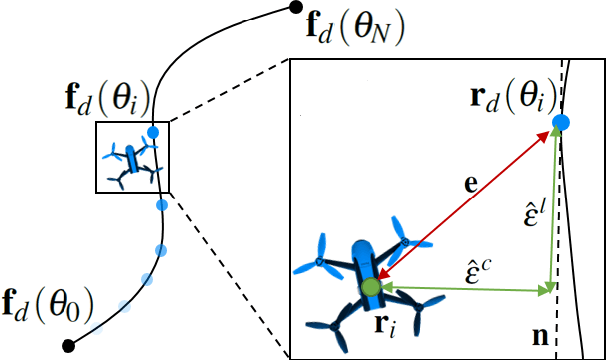
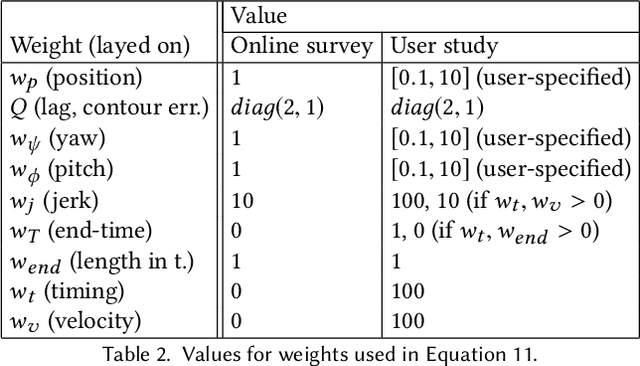
In this paper we first contribute a large scale online study (N=400) to better understand aesthetic perception of aerial video. The results indicate that it is paramount to optimize smoothness of trajectories across all keyframes. However, for experts timing control remains an essential tool. Satisfying this dual goal is technically challenging because it requires giving up desirable properties in the optimization formulation. Second, informed by this study we propose a method that optimizes positional and temporal reference fit jointly. This allows to generate globally smooth trajectories, while retaining user control over reference timings. The formulation is posed as a variable, infinite horizon, contour-following algorithm. Finally, a comparative lab study indicates that our optimization scheme outperforms the state-of-the-art in terms of perceived usability and preference of resulting videos. For novices our method produces smoother and better looking results and also experts benefit from generated timings.
Airways: Optimization-Based Planning of Quadrotor Trajectories according to High-Level User Goals
Jun 27, 2019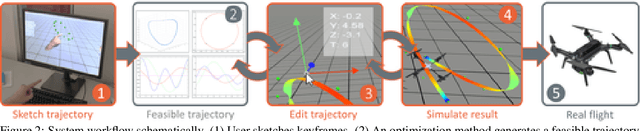
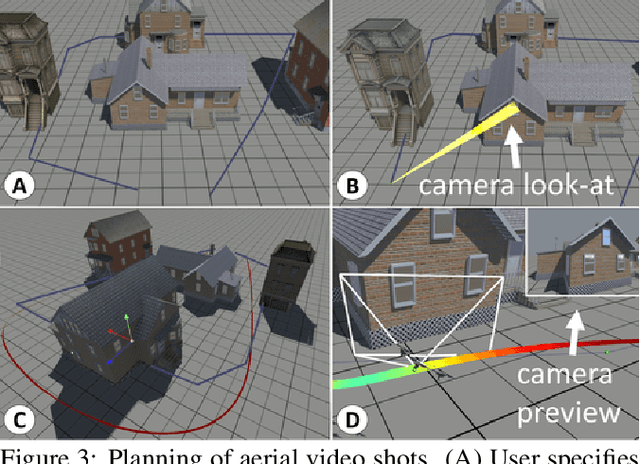

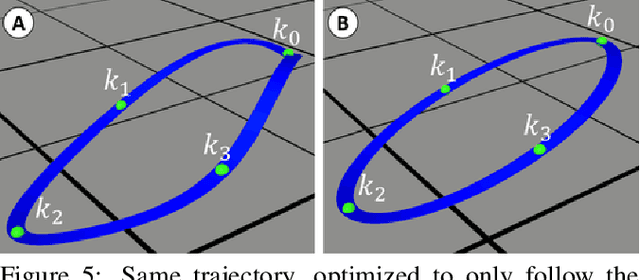
In this paper we propose a computational design tool that al-lows end-users to create advanced quadrotor trajectories witha variety of application scenarios in mind. Our algorithm al-lows novice users to create quadrotor based use-cases withoutrequiring deep knowledge in either quadrotor control or theunderlying constraints of the target domain. To achieve thisgoal we propose an optimization-based method that gener-ates feasible trajectories which can be flown in the real world.Furthermore, the method incorporates high-level human ob-jectives into the planning of flight trajectories. An easy touse 3D design tool allows for quick specification and edit-ing of trajectories as well as for intuitive exploration of theresulting solution space. We demonstrate the utility of our ap-proach in several real-world application scenarios, includingaerial-videography, robotic light-painting and drone racing.
* 12 pages