 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRILe: Reinforced Imitation Learning
Jun 12, 2024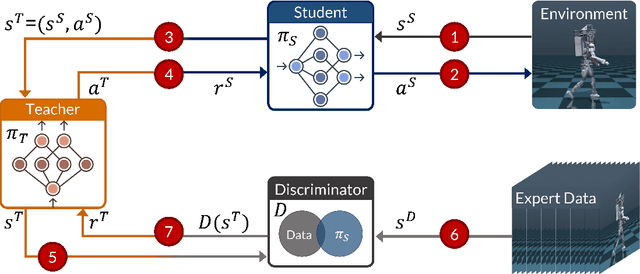
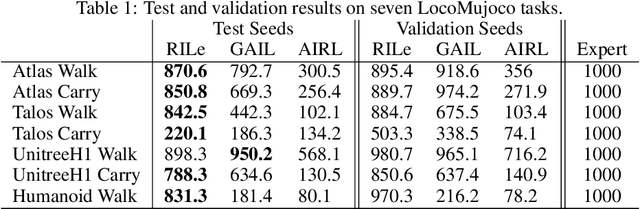
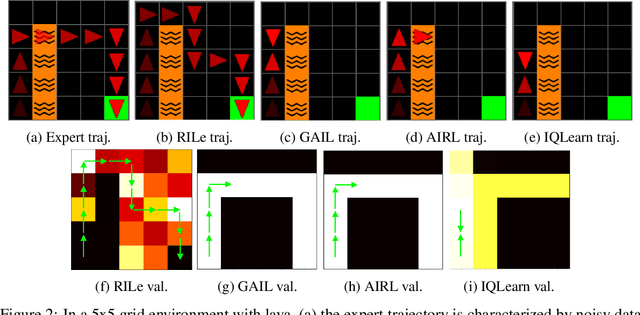
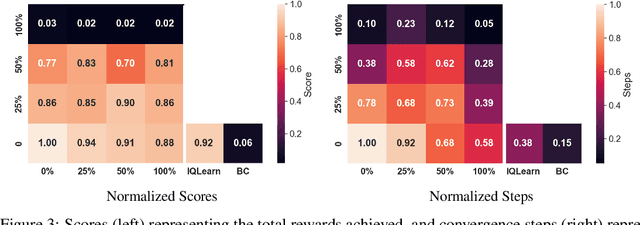
Reinforcement Learning has achieved significant success in generating complex behavior but often requires extensive reward function engineering. Adversarial variants of Imitation Learning and Inverse Reinforcement Learning offer an alternative by learning policies from expert demonstrations via a discriminator. Employing discriminators increases their data- and computational efficiency over the standard approaches; however, results in sensitivity to imperfections in expert data. We propose RILe, a teacher-student system that achieves both robustness to imperfect data and efficiency. In RILe, the student learns an action policy while the teacher dynamically adjusts a reward function based on the student's performance and its alignment with expert demonstrations. By tailoring the reward function to both performance of the student and expert similarity, our system reduces dependence on the discriminator and, hence, increases robustness against data imperfections. Experiments show that RILe outperforms existing methods by 2x in settings with limited or noisy expert data.