 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNIL: No-data Imitation Learning by Leveraging Pre-trained Video Diffusion Models
Mar 13, 2025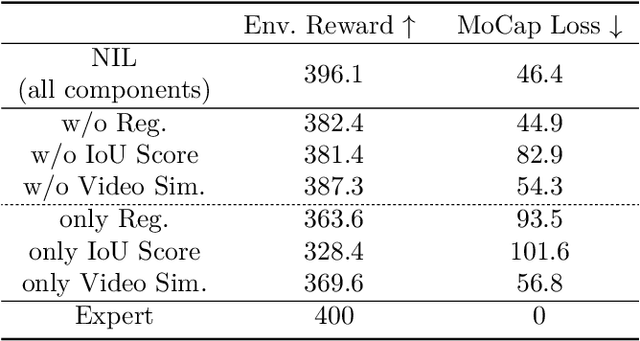
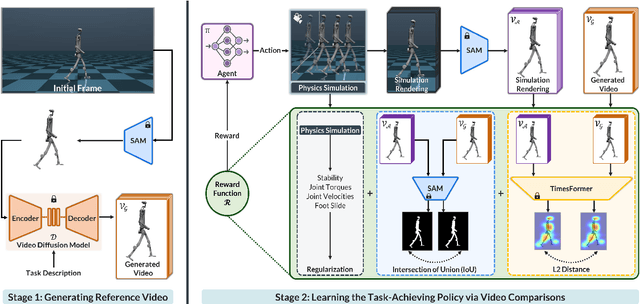
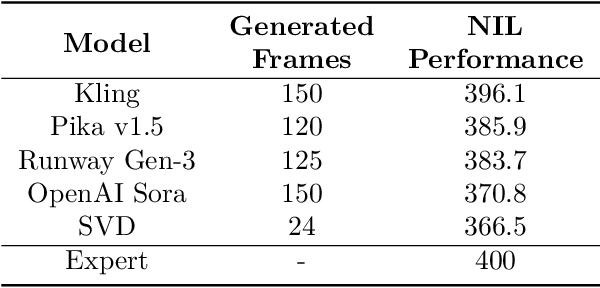
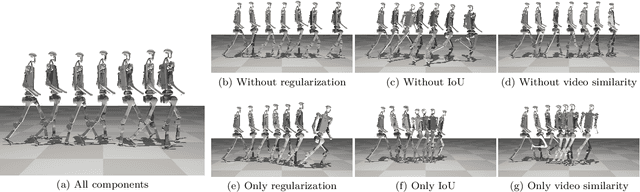
Acquiring physically plausible motor skills across diverse and unconventional morphologies-including humanoid robots, quadrupeds, and animals-is essential for advancing character simulation and robotics. Traditional methods, such as reinforcement learning (RL) are task- and body-specific, require extensive reward function engineering, and do not generalize well. Imitation learning offers an alternative but relies heavily on high-quality expert demonstrations, which are difficult to obtain for non-human morphologies. Video diffusion models, on the other hand, are capable of generating realistic videos of various morphologies, from humans to ants. Leveraging this capability, we propose a data-independent approach for skill acquisition that learns 3D motor skills from 2D-generated videos, with generalization capability to unconventional and non-human forms. Specifically, we guide the imitation learning process by leveraging vision transformers for video-based comparisons by calculating pair-wise distance between video embeddings. Along with video-encoding distance, we also use a computed similarity between segmented video frames as a guidance reward. We validate our method on locomotion tasks involving unique body configurations. In humanoid robot locomotion tasks, we demonstrate that 'No-data Imitation Learning' (NIL) outperforms baselines trained on 3D motion-capture data. Our results highlight the potential of leveraging generative video models for physically plausible skill learning with diverse morphologies, effectively replacing data collection with data generation for imitation learning.
RILe: Reinforced Imitation Learning
Jun 12, 2024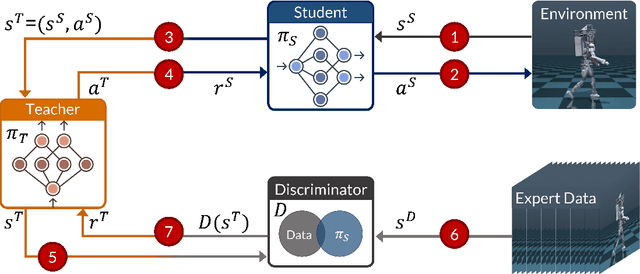
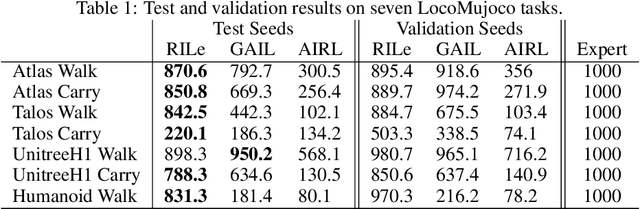
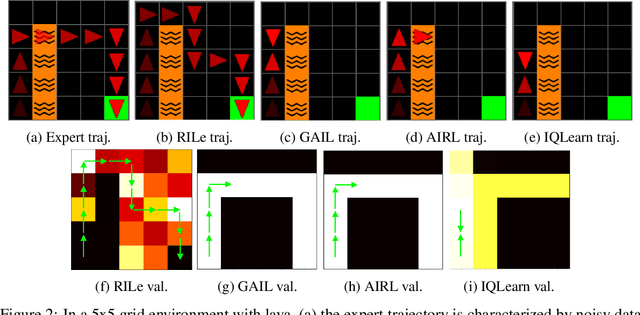
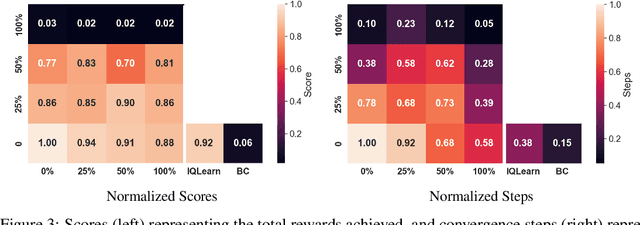
Reinforcement Learning has achieved significant success in generating complex behavior but often requires extensive reward function engineering. Adversarial variants of Imitation Learning and Inverse Reinforcement Learning offer an alternative by learning policies from expert demonstrations via a discriminator. Employing discriminators increases their data- and computational efficiency over the standard approaches; however, results in sensitivity to imperfections in expert data. We propose RILe, a teacher-student system that achieves both robustness to imperfect data and efficiency. In RILe, the student learns an action policy while the teacher dynamically adjusts a reward function based on the student's performance and its alignment with expert demonstrations. By tailoring the reward function to both performance of the student and expert similarity, our system reduces dependence on the discriminator and, hence, increases robustness against data imperfections. Experiments show that RILe outperforms existing methods by 2x in settings with limited or noisy expert data.
Modeling Cyber-Physical Human Systems via an Interplay Between Reinforcement Learning and Game Theory
Oct 11, 2019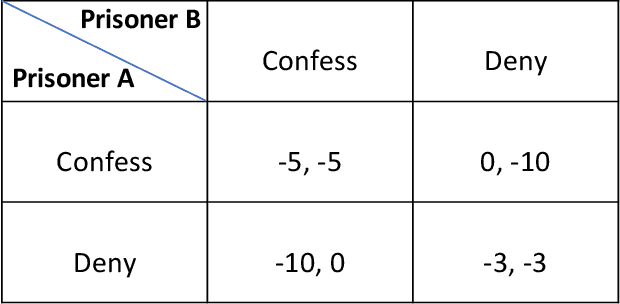
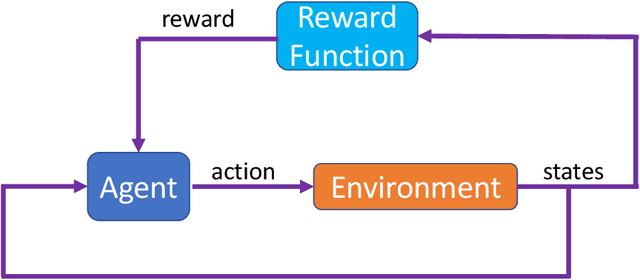
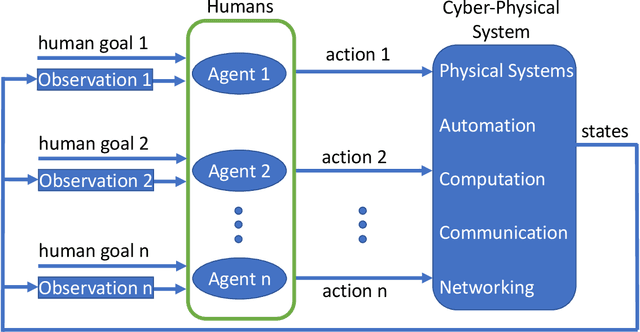
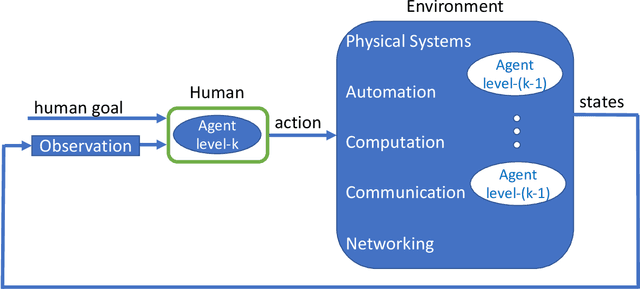
Predicting the outcomes of cyber-physical systems with multiple human interactions is a challenging problem. This article reviews a game theoretical approach to address this issue, where reinforcement learning is employed to predict the time-extended interaction dynamics. We explain that the most attractive feature of the method is proposing a computationally feasible approach to simultaneously model multiple humans as decision makers, instead of determining the decision dynamics of the intelligent agent of interest and forcing the others to obey certain kinematic and dynamic constraints imposed by the environment. We present two recent exploitations of the method to model 1) unmanned aircraft integration into the National Airspace System and 2) highway traffic. We conclude the article by providing ongoing and future work about employing, improving and validating the method. We also provide related open problems and research opportunities.