 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Learning of Robot Manipulation Tasks via Tactile Intrinsic Motivation
Feb 22, 2021
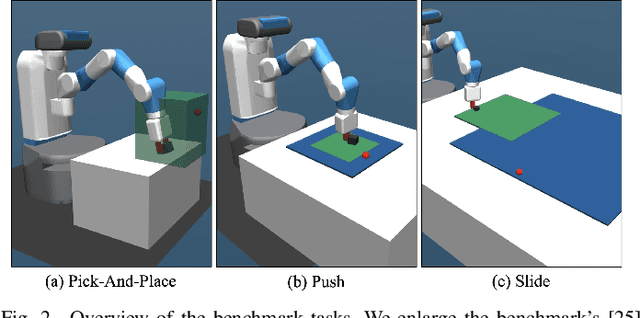
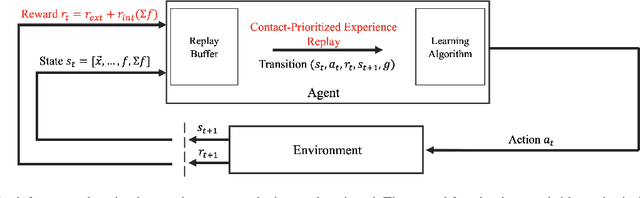
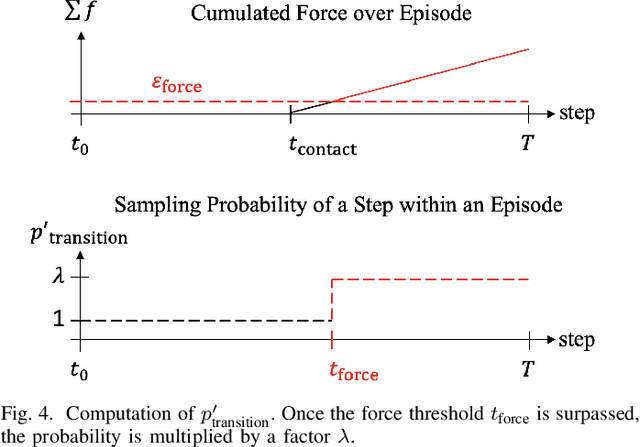
In this paper we address the challenge of exploration in deep reinforcement learning for robotic manipulation tasks. In sparse goal settings, an agent does not receive any positive feedback until randomly achieving the goal, which becomes infeasible for longer control sequences. Inspired by touch-based exploration observed in children, we formulate an intrinsic reward based on the sum of forces between a robot's force sensors and manipulation objects that encourages physical interaction. Furthermore, we introduce contact-prioritized experience replay, a sampling scheme that prioritizes contact rich episodes and transitions. We show that our solution accelerates the exploration and outperforms state-of-the-art methods on three fundamental robot manipulation benchmarks.
Spatial Attention Improves Iterative 6D Object Pose Estimation
Jan 05, 2021
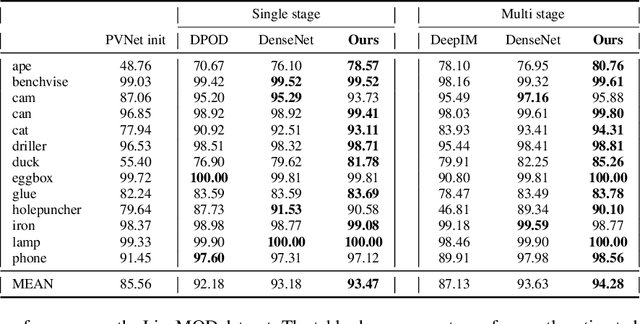
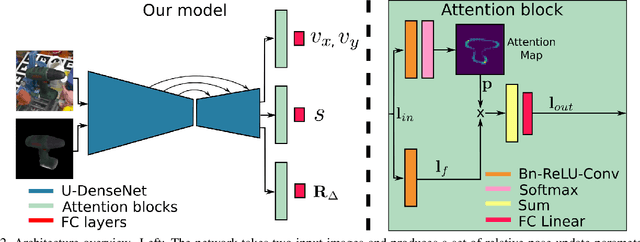
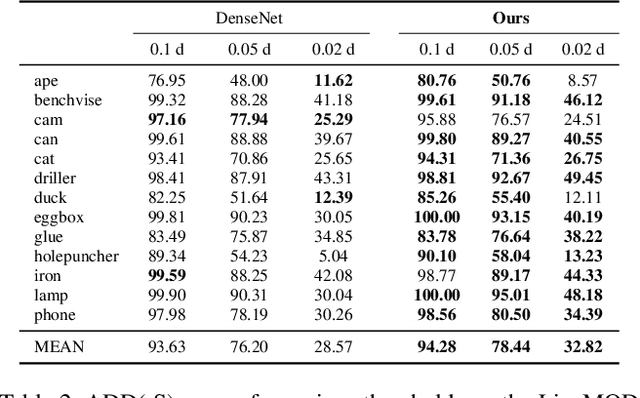
The task of estimating the 6D pose of an object from RGB images can be broken down into two main steps: an initial pose estimation step, followed by a refinement procedure to correctly register the object and its observation. In this paper, we propose a new method for 6D pose estimation refinement from RGB images. To achieve high accuracy of the final estimate, the observation and a rendered model need to be aligned. Our main insight is that after the initial pose estimate, it is important to pay attention to distinct spatial features of the object in order to improve the estimation accuracy during alignment. Furthermore, parts of the object that are occluded in the image should be given less weight during the alignment process. Most state-of-the-art refinement approaches do not allow for this fine-grained reasoning and can not fully leverage the structure of the problem. In contrast, we propose a novel neural network architecture built around a spatial attention mechanism that identifies and leverages information about spatial details during pose refinement. We experimentally show that this approach learns to attend to salient spatial features and learns to ignore occluded parts of the object, leading to better pose estimation across datasets. We conduct experiments on standard benchmark datasets for 6D pose estimation (LineMOD and Occlusion LineMOD) and outperform previous state-of-the-art methods.
Sample Efficient Learning of Path Following and Obstacle Avoidance Behavior for Quadrotors
Jun 28, 2019



In this paper we propose an algorithm for the training of neural network control policies for quadrotors. The learned control policy computes control commands directly from sensor inputs and is hence computationally efficient. An imitation learning algorithm produces a policy that reproduces the behavior of a path following control algorithm with collision avoidance. Due to the generalization ability of neural networks, the resulting policy performs local collision avoidance of unseen obstacles while following a global reference path. The algorithm uses a time-free model predictive path-following controller as a supervisor. The controller generates demonstrations by following few example paths. This enables an easy to implement learning algorithm that is robust to errors of the model used in the model predictive controller. The policy is trained on the real quadrotor, which requires collision-free exploration around the example path. An adapted version of the supervisor is used to enable exploration. Thus, the policy can be trained from a relatively small number of examples on the real quadrotor, making the training sample efficient.
* 8 pages
Demonstration-Guided Deep Reinforcement Learning of Control Policies for Dexterous Human-Robot Interaction
Jun 27, 2019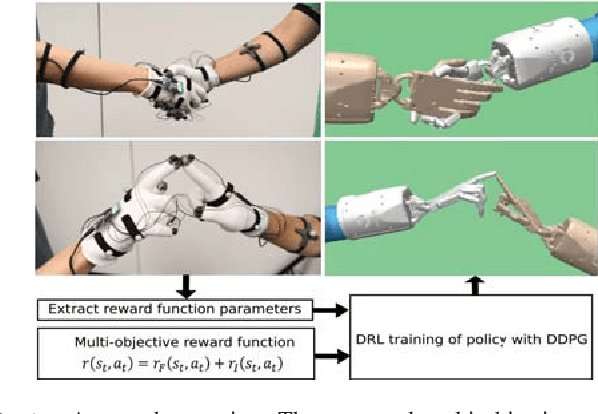
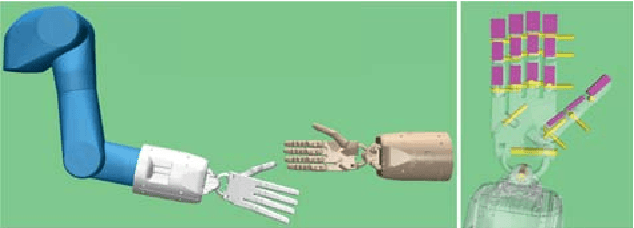
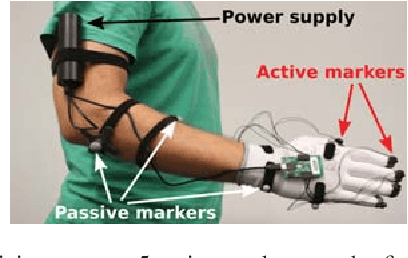
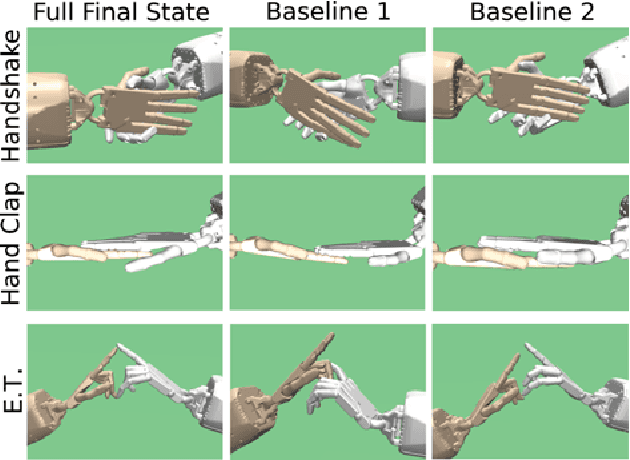
In this paper, we propose a method for training control policies for human-robot interactions such as handshakes or hand claps via Deep Reinforcement Learning. The policy controls a humanoid Shadow Dexterous Hand, attached to a robot arm. We propose a parameterizable multi-objective reward function that allows learning of a variety of interactions without changing the reward structure. The parameters of the reward function are estimated directly from motion capture data of human-human interactions in order to produce policies that are perceived as being natural and human-like by observers. We evaluate our method on three significantly different hand interactions: handshake, hand clap and finger touch. We provide detailed analysis of the proposed reward function and the resulting policies and conduct a large-scale user study, indicating that our policy produces natural looking motions.
* 7 pages
Optimizing for Aesthetically Pleasing Quadrotor Camera Motion
Jun 27, 2019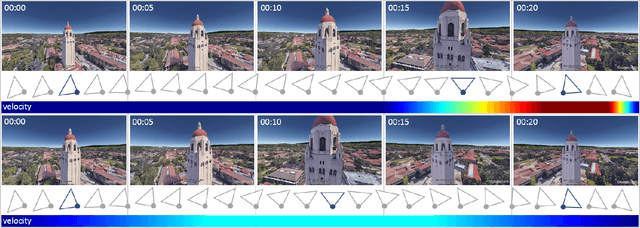
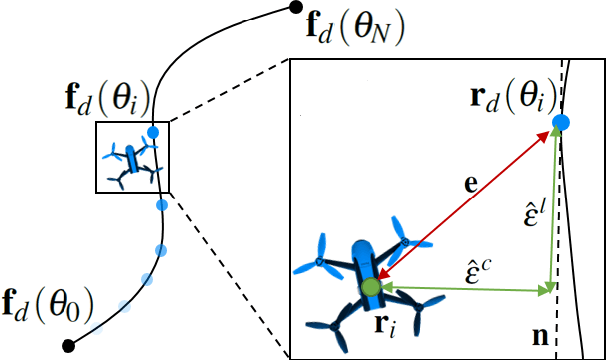
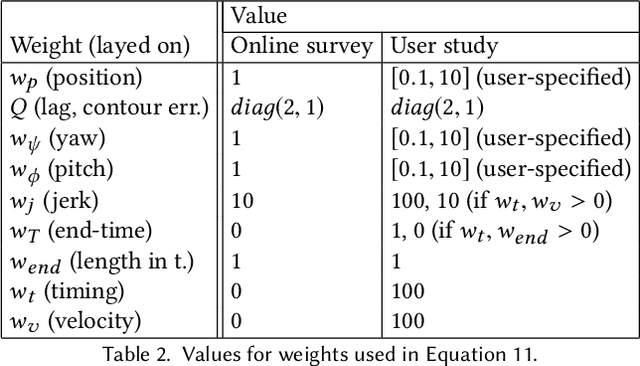
In this paper we first contribute a large scale online study (N=400) to better understand aesthetic perception of aerial video. The results indicate that it is paramount to optimize smoothness of trajectories across all keyframes. However, for experts timing control remains an essential tool. Satisfying this dual goal is technically challenging because it requires giving up desirable properties in the optimization formulation. Second, informed by this study we propose a method that optimizes positional and temporal reference fit jointly. This allows to generate globally smooth trajectories, while retaining user control over reference timings. The formulation is posed as a variable, infinite horizon, contour-following algorithm. Finally, a comparative lab study indicates that our optimization scheme outperforms the state-of-the-art in terms of perceived usability and preference of resulting videos. For novices our method produces smoother and better looking results and also experts benefit from generated timings.
Airways: Optimization-Based Planning of Quadrotor Trajectories according to High-Level User Goals
Jun 27, 2019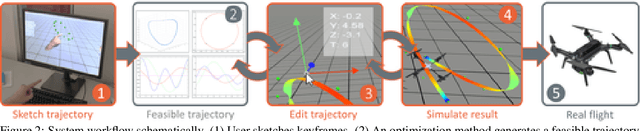
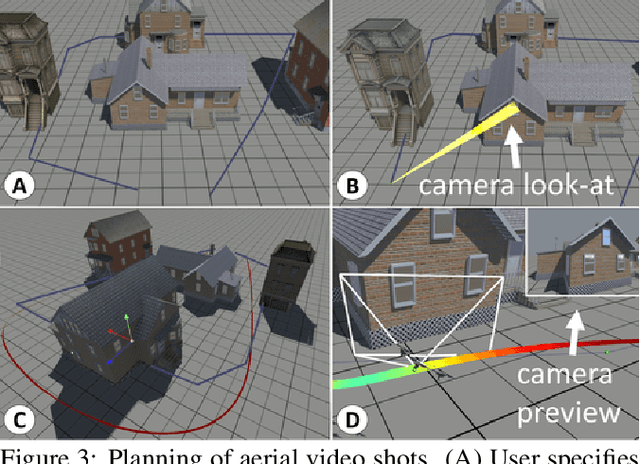

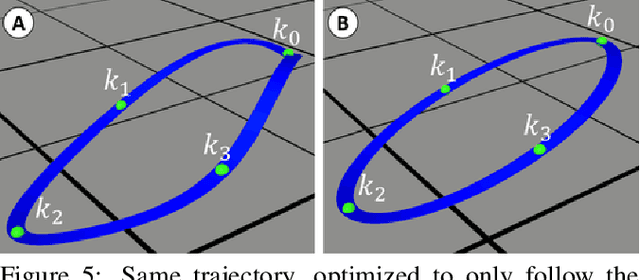
In this paper we propose a computational design tool that al-lows end-users to create advanced quadrotor trajectories witha variety of application scenarios in mind. Our algorithm al-lows novice users to create quadrotor based use-cases withoutrequiring deep knowledge in either quadrotor control or theunderlying constraints of the target domain. To achieve thisgoal we propose an optimization-based method that gener-ates feasible trajectories which can be flown in the real world.Furthermore, the method incorporates high-level human ob-jectives into the planning of flight trajectories. An easy touse 3D design tool allows for quick specification and edit-ing of trajectories as well as for intuitive exploration of theresulting solution space. We demonstrate the utility of our ap-proach in several real-world application scenarios, includingaerial-videography, robotic light-painting and drone racing.
* 12 pages