 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Attention Improves Iterative 6D Object Pose Estimation
Paper and Code
Jan 05, 2021
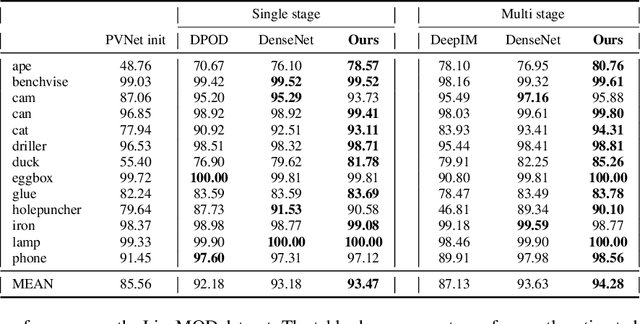
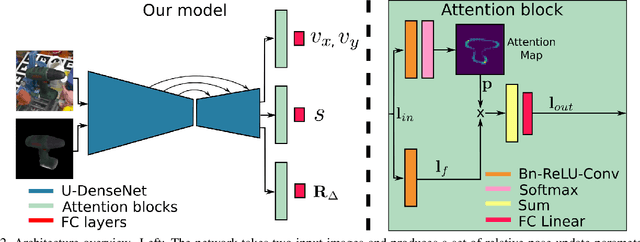
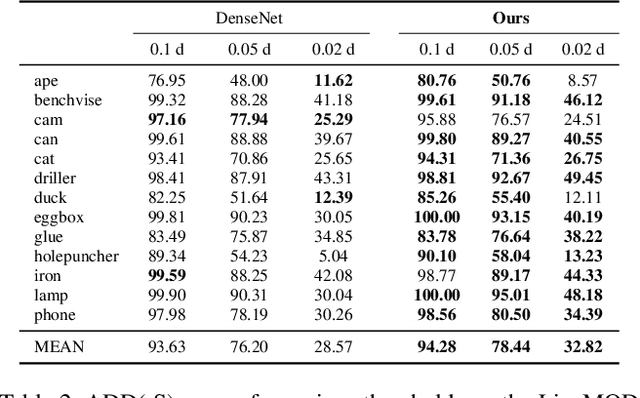
The task of estimating the 6D pose of an object from RGB images can be broken down into two main steps: an initial pose estimation step, followed by a refinement procedure to correctly register the object and its observation. In this paper, we propose a new method for 6D pose estimation refinement from RGB images. To achieve high accuracy of the final estimate, the observation and a rendered model need to be aligned. Our main insight is that after the initial pose estimate, it is important to pay attention to distinct spatial features of the object in order to improve the estimation accuracy during alignment. Furthermore, parts of the object that are occluded in the image should be given less weight during the alignment process. Most state-of-the-art refinement approaches do not allow for this fine-grained reasoning and can not fully leverage the structure of the problem. In contrast, we propose a novel neural network architecture built around a spatial attention mechanism that identifies and leverages information about spatial details during pose refinement. We experimentally show that this approach learns to attend to salient spatial features and learns to ignore occluded parts of the object, leading to better pose estimation across datasets. We conduct experiments on standard benchmark datasets for 6D pose estimation (LineMOD and Occlusion LineMOD) and outperform previous state-of-the-art methods.