 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSenCache: Accelerating Diffusion Model Inference via Sensitivity-Aware Caching
Feb 27, 2026Diffusion models achieve state-of-the-art video generation quality, but their inference remains expensive due to the large number of sequential denoising steps. This has motivated a growing line of research on accelerating diffusion inference. Among training-free acceleration methods, caching reduces computation by reusing previously computed model outputs across timesteps. Existing caching methods rely on heuristic criteria to choose cache/reuse timesteps and require extensive tuning. We address this limitation with a principled sensitivity-aware caching framework. Specifically, we formalize the caching error through an analysis of the model output sensitivity to perturbations in the denoising inputs, i.e., the noisy latent and the timestep, and show that this sensitivity is a key predictor of caching error. Based on this analysis, we propose Sensitivity-Aware Caching (SenCache), a dynamic caching policy that adaptively selects caching timesteps on a per-sample basis. Our framework provides a theoretical basis for adaptive caching, explains why prior empirical heuristics can be partially effective, and extends them to a dynamic, sample-specific approach. Experiments on Wan 2.1, CogVideoX, and LTX-Video show that SenCache achieves better visual quality than existing caching methods under similar computational budgets.
Communication-Inspired Tokenization for Structured Image Representations
Feb 24, 2026Discrete image tokenizers have emerged as a key component of modern vision and multimodal systems, providing a sequential interface for transformer-based architectures. However, most existing approaches remain primarily optimized for reconstruction and compression, often yielding tokens that capture local texture rather than object-level semantic structure. Inspired by the incremental and compositional nature of human communication, we introduce COMmunication inspired Tokenization (COMiT), a framework for learning structured discrete visual token sequences. COMiT constructs a latent message within a fixed token budget by iteratively observing localized image crops and recurrently updating its discrete representation. At each step, the model integrates new visual information while refining and reorganizing the existing token sequence. After several encoding iterations, the final message conditions a flow-matching decoder that reconstructs the full image. Both encoding and decoding are implemented within a single transformer model and trained end-to-end using a combination of flow-matching reconstruction and semantic representation alignment losses. Our experiments demonstrate that while semantic alignment provides grounding, attentive sequential tokenization is critical for inducing interpretable, object-centric token structure and substantially improving compositional generalization and relational reasoning over prior methods.
LayerSync: Self-aligning Intermediate Layers
Oct 14, 2025We propose LayerSync, a domain-agnostic approach for improving the generation quality and the training efficiency of diffusion models. Prior studies have highlighted the connection between the quality of generation and the representations learned by diffusion models, showing that external guidance on model intermediate representations accelerates training. We reconceptualize this paradigm by regularizing diffusion models with their own intermediate representations. Building on the observation that representation quality varies across diffusion model layers, we show that the most semantically rich representations can act as an intrinsic guidance for weaker ones, reducing the need for external supervision. Our approach, LayerSync, is a self-sufficient, plug-and-play regularizer term with no overhead on diffusion model training and generalizes beyond the visual domain to other modalities. LayerSync requires no pretrained models nor additional data. We extensively evaluate the method on image generation and demonstrate its applicability to other domains such as audio, video, and motion generation. We show that it consistently improves the generation quality and the training efficiency. For example, we speed up the training of flow-based transformer by over 8.75x on ImageNet dataset and improved the generation quality by 23.6%. The code is available at https://github.com/vita-epfl/LayerSync.
EgoSim: An Egocentric Multi-view Simulator and Real Dataset for Body-worn Cameras during Motion and Activity
Feb 25, 2025Research on egocentric tasks in computer vision has mostly focused on head-mounted cameras, such as fisheye cameras or embedded cameras inside immersive headsets. We argue that the increasing miniaturization of optical sensors will lead to the prolific integration of cameras into many more body-worn devices at various locations. This will bring fresh perspectives to established tasks in computer vision and benefit key areas such as human motion tracking, body pose estimation, or action recognition -- particularly for the lower body, which is typically occluded. In this paper, we introduce EgoSim, a novel simulator of body-worn cameras that generates realistic egocentric renderings from multiple perspectives across a wearer's body. A key feature of EgoSim is its use of real motion capture data to render motion artifacts, which are especially noticeable with arm- or leg-worn cameras. In addition, we introduce MultiEgoView, a dataset of egocentric footage from six body-worn cameras and ground-truth full-body 3D poses during several activities: 119 hours of data are derived from AMASS motion sequences in four high-fidelity virtual environments, which we augment with 5 hours of real-world motion data from 13 participants using six GoPro cameras and 3D body pose references from an Xsens motion capture suit. We demonstrate EgoSim's effectiveness by training an end-to-end video-only 3D pose estimation network. Analyzing its domain gap, we show that our dataset and simulator substantially aid training for inference on real-world data. EgoSim code & MultiEgoView dataset: https://siplab.org/projects/EgoSim
GEM: A Generalizable Ego-Vision Multimodal World Model for Fine-Grained Ego-Motion, Object Dynamics, and Scene Composition Control
Dec 15, 2024



We present GEM, a Generalizable Ego-vision Multimodal world model that predicts future frames using a reference frame, sparse features, human poses, and ego-trajectories. Hence, our model has precise control over object dynamics, ego-agent motion and human poses. GEM generates paired RGB and depth outputs for richer spatial understanding. We introduce autoregressive noise schedules to enable stable long-horizon generations. Our dataset is comprised of 4000+ hours of multimodal data across domains like autonomous driving, egocentric human activities, and drone flights. Pseudo-labels are used to get depth maps, ego-trajectories, and human poses. We use a comprehensive evaluation framework, including a new Control of Object Manipulation (COM) metric, to assess controllability. Experiments show GEM excels at generating diverse, controllable scenarios and temporal consistency over long generations. Code, models, and datasets are fully open-sourced.
HEADS-UP: Head-Mounted Egocentric Dataset for Trajectory Prediction in Blind Assistance Systems
Sep 30, 2024

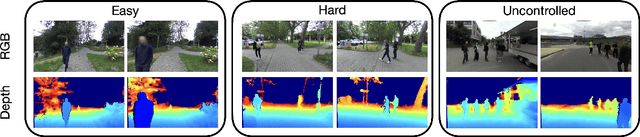
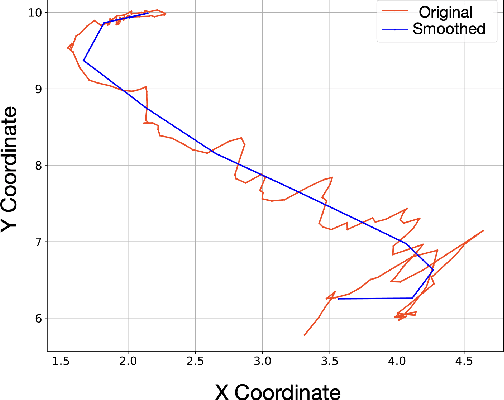
In this paper, we introduce HEADS-UP, the first egocentric dataset collected from head-mounted cameras, designed specifically for trajectory prediction in blind assistance systems. With the growing population of blind and visually impaired individuals, the need for intelligent assistive tools that provide real-time warnings about potential collisions with dynamic obstacles is becoming critical. These systems rely on algorithms capable of predicting the trajectories of moving objects, such as pedestrians, to issue timely hazard alerts. However, existing datasets fail to capture the necessary information from the perspective of a blind individual. To address this gap, HEADS-UP offers a novel dataset focused on trajectory prediction in this context. Leveraging this dataset, we propose a semi-local trajectory prediction approach to assess collision risks between blind individuals and pedestrians in dynamic environments. Unlike conventional methods that separately predict the trajectories of both the blind individual (ego agent) and pedestrians, our approach operates within a semi-local coordinate system, a rotated version of the camera's coordinate system, facilitating the prediction process. We validate our method on the HEADS-UP dataset and implement the proposed solution in ROS, performing real-time tests on an NVIDIA Jetson GPU through a user study. Results from both dataset evaluations and live tests demonstrate the robustness and efficiency of our approach.
Neural Implicit Dense Semantic SLAM
May 09, 2023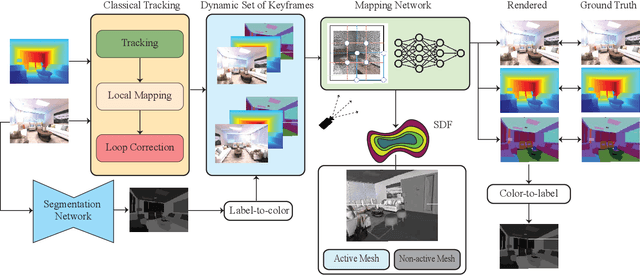
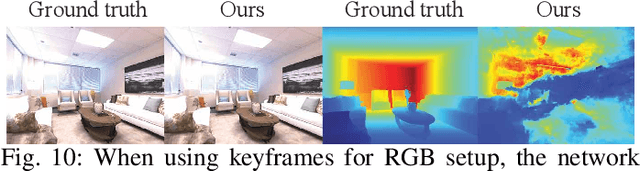
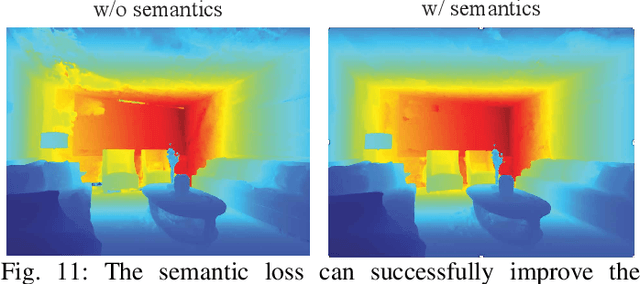

Visual Simultaneous Localization and Mapping (vSLAM) is a widely used technique in robotics and computer vision that enables a robot to create a map of an unfamiliar environment using a camera sensor while simultaneously tracking its position over time. In this paper, we propose a novel RGBD vSLAM algorithm that can learn a memory-efficient, dense 3D geometry, and semantic segmentation of an indoor scene in an online manner. Our pipeline combines classical 3D vision-based tracking and loop closing with neural fields-based mapping. The mapping network learns the SDF of the scene as well as RGB, depth, and semantic maps of any novel view using only a set of keyframes. Additionally, we extend our pipeline to large scenes by using multiple local mapping networks. Extensive experiments on well-known benchmark datasets confirm that our approach provides robust tracking, mapping, and semantic labeling even with noisy, sparse, or no input depth. Overall, our proposed algorithm can greatly enhance scene perception and assist with a range of robot control problems.