 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREFA: Real-time Egocentric Facial Animations for Virtual Reality
Jan 07, 2026We present a novel system for real-time tracking of facial expressions using egocentric views captured from a set of infrared cameras embedded in a virtual reality (VR) headset. Our technology facilitates any user to accurately drive the facial expressions of virtual characters in a non-intrusive manner and without the need of a lengthy calibration step. At the core of our system is a distillation based approach to train a machine learning model on heterogeneous data and labels coming form multiple sources, \eg synthetic and real images. As part of our dataset, we collected 18k diverse subjects using a lightweight capture setup consisting of a mobile phone and a custom VR headset with extra cameras. To process this data, we developed a robust differentiable rendering pipeline enabling us to automatically extract facial expression labels. Our system opens up new avenues for communication and expression in virtual environments, with applications in video conferencing, gaming, entertainment, and remote collaboration.
AvatarPoser: Articulated Full-Body Pose Tracking from Sparse Motion Sensing
Jul 27, 2022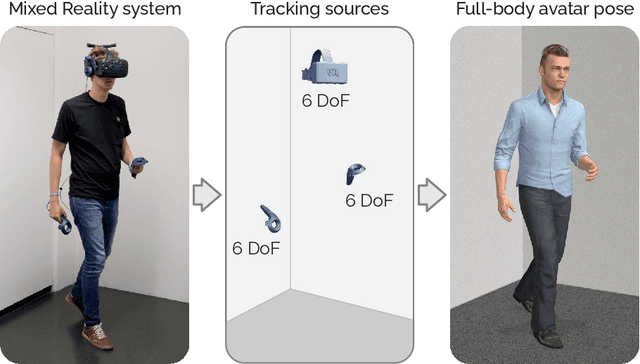
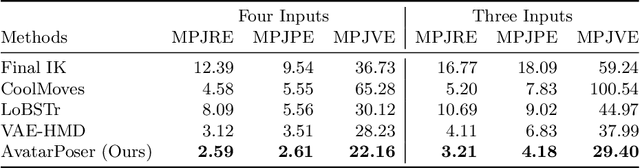
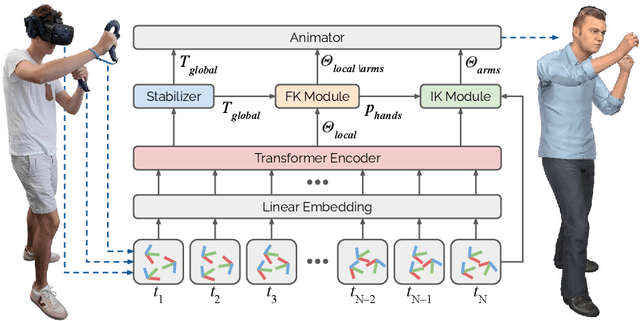
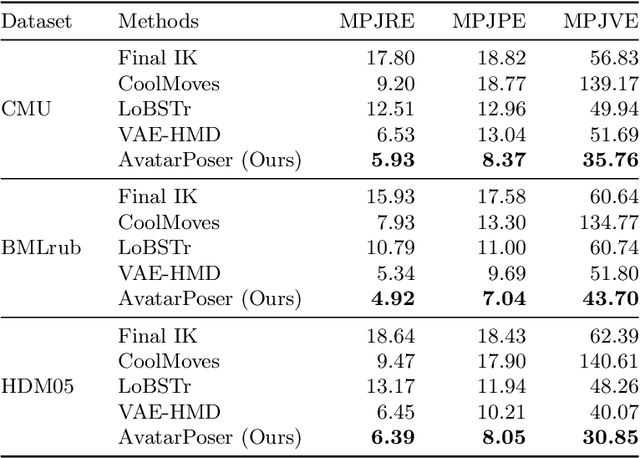
Today's Mixed Reality head-mounted displays track the user's head pose in world space as well as the user's hands for interaction in both Augmented Reality and Virtual Reality scenarios. While this is adequate to support user input, it unfortunately limits users' virtual representations to just their upper bodies. Current systems thus resort to floating avatars, whose limitation is particularly evident in collaborative settings. To estimate full-body poses from the sparse input sources, prior work has incorporated additional trackers and sensors at the pelvis or lower body, which increases setup complexity and limits practical application in mobile settings. In this paper, we present AvatarPoser, the first learning-based method that predicts full-body poses in world coordinates using only motion input from the user's head and hands. Our method builds on a Transformer encoder to extract deep features from the input signals and decouples global motion from the learned local joint orientations to guide pose estimation. To obtain accurate full-body motions that resemble motion capture animations, we refine the arm joints' positions using an optimization routine with inverse kinematics to match the original tracking input. In our evaluation, AvatarPoser achieved new state-of-the-art results in evaluations on large motion capture datasets (AMASS). At the same time, our method's inference speed supports real-time operation, providing a practical interface to support holistic avatar control and representation for Metaverse applications.
DenseReg: Fully Convolutional Dense Shape Regression In-the-Wild
Mar 11, 2018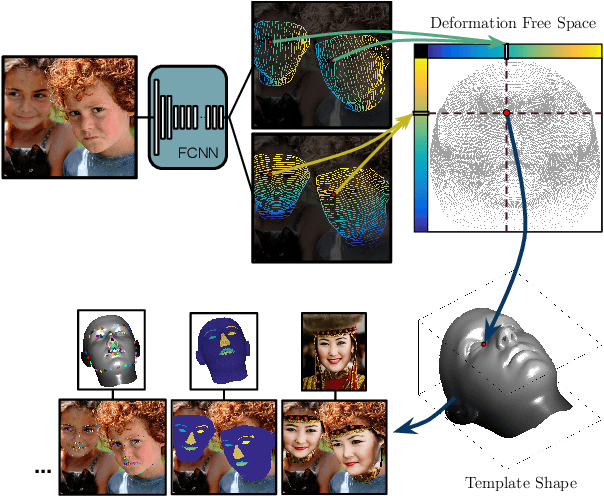
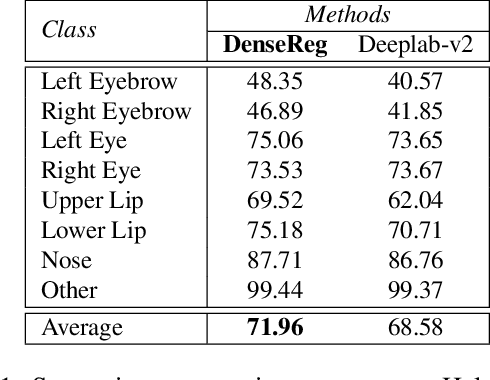
In this work we use deep learning to establish dense correspondences between a 3D object model and an image "in the wild". We introduce "DenseReg", a fully-convolutional neural network (F-CNN) that densely regresses at every foreground pixel a pair of U-V template coordinates in a single feedforward pass. To train DenseReg we construct a supervision signal by combining 3D deformable model fitting and 2D landmark annotations. We define the regression task in terms of the intrinsic, U-V coordinates of a 3D deformable model that is brought into correspondence with image instances at training time. A host of other object-related tasks (e.g. part segmentation, landmark localization) are shown to be by-products of this task, and to largely improve thanks to its introduction. We obtain highly-accurate regression results by combining ideas from semantic segmentation with regression networks, yielding a 'quantized regression' architecture that first obtains a quantized estimate of position through classification, and refines it through regression of the residual. We show that such networks can boost the performance of existing state-of-the-art systems for pose estimation. Firstly, we show that our system can serve as an initialization for Statistical Deformable Models, as well as an element of cascaded architectures that jointly localize landmarks and estimate dense correspondences. We also show that the obtained dense correspondence can act as a source of 'privileged information' that complements and extends the pure landmark-level annotations, accelerating and improving the training of pose estimation networks. We report state-of-the-art performance on the challenging 300W benchmark for facial landmark localization and on the MPII and LSP datasets for human pose estimation.
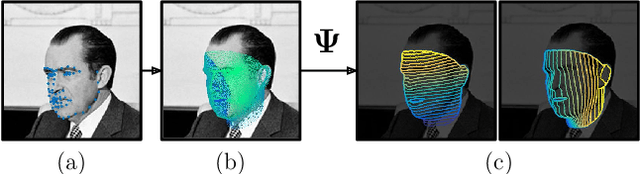
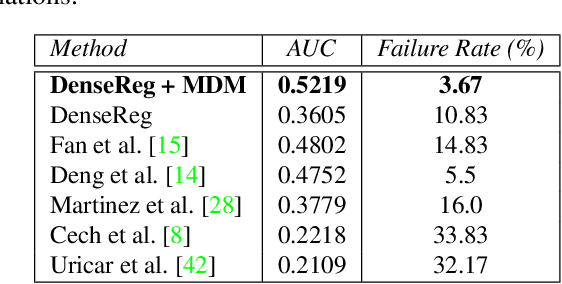
A Comprehensive Performance Evaluation of Deformable Face Tracking "In-the-Wild"
Feb 28, 2017
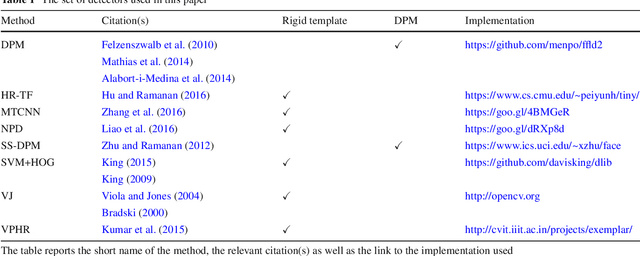
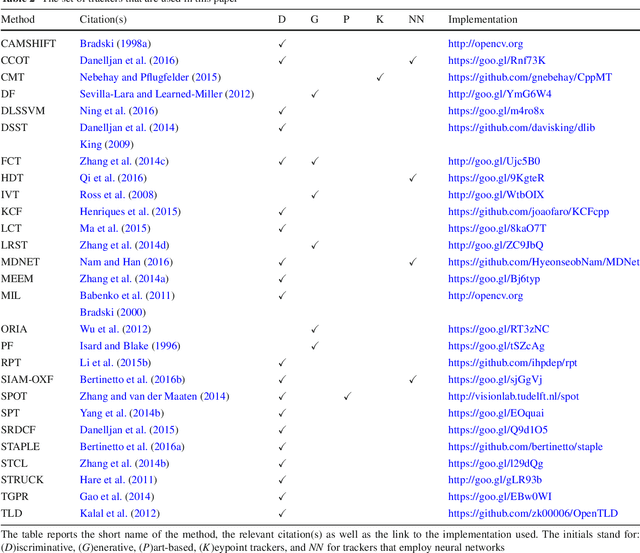

Recently, technologies such as face detection, facial landmark localisation and face recognition and verification have matured enough to provide effective and efficient solutions for imagery captured under arbitrary conditions (referred to as "in-the-wild"). This is partially attributed to the fact that comprehensive "in-the-wild" benchmarks have been developed for face detection, landmark localisation and recognition/verification. A very important technology that has not been thoroughly evaluated yet is deformable face tracking "in-the-wild". Until now, the performance has mainly been assessed qualitatively by visually assessing the result of a deformable face tracking technology on short videos. In this paper, we perform the first, to the best of our knowledge, thorough evaluation of state-of-the-art deformable face tracking pipelines using the recently introduced 300VW benchmark. We evaluate many different architectures focusing mainly on the task of on-line deformable face tracking. In particular, we compare the following general strategies: (a) generic face detection plus generic facial landmark localisation, (b) generic model free tracking plus generic facial landmark localisation, as well as (c) hybrid approaches using state-of-the-art face detection, model free tracking and facial landmark localisation technologies. Our evaluation reveals future avenues for further research on the topic.