 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenseReg: Fully Convolutional Dense Shape Regression In-the-Wild
Paper and Code
Mar 11, 2018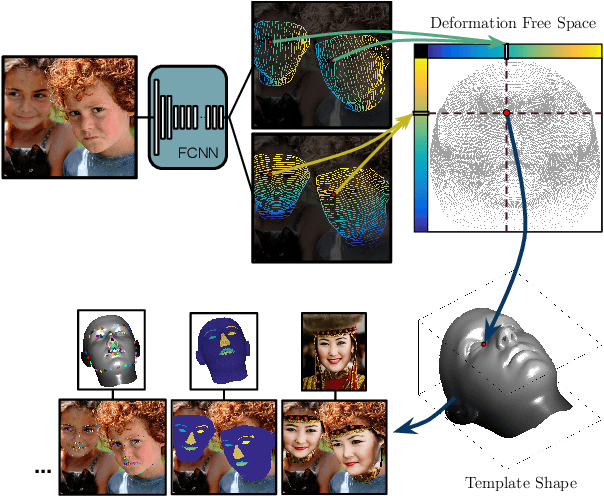
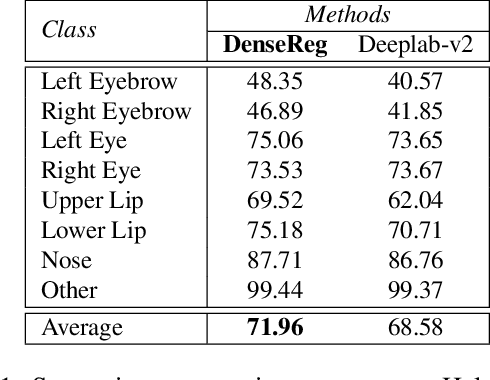
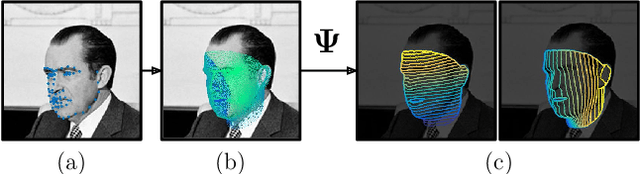
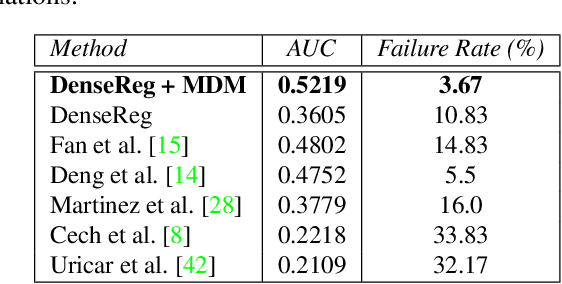
In this work we use deep learning to establish dense correspondences between a 3D object model and an image "in the wild". We introduce "DenseReg", a fully-convolutional neural network (F-CNN) that densely regresses at every foreground pixel a pair of U-V template coordinates in a single feedforward pass. To train DenseReg we construct a supervision signal by combining 3D deformable model fitting and 2D landmark annotations. We define the regression task in terms of the intrinsic, U-V coordinates of a 3D deformable model that is brought into correspondence with image instances at training time. A host of other object-related tasks (e.g. part segmentation, landmark localization) are shown to be by-products of this task, and to largely improve thanks to its introduction. We obtain highly-accurate regression results by combining ideas from semantic segmentation with regression networks, yielding a 'quantized regression' architecture that first obtains a quantized estimate of position through classification, and refines it through regression of the residual. We show that such networks can boost the performance of existing state-of-the-art systems for pose estimation. Firstly, we show that our system can serve as an initialization for Statistical Deformable Models, as well as an element of cascaded architectures that jointly localize landmarks and estimate dense correspondences. We also show that the obtained dense correspondence can act as a source of 'privileged information' that complements and extends the pure landmark-level annotations, accelerating and improving the training of pose estimation networks. We report state-of-the-art performance on the challenging 300W benchmark for facial landmark localization and on the MPII and LSP datasets for human pose estimation.