 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenseReg: Fully Convolutional Dense Shape Regression In-the-Wild
Mar 11, 2018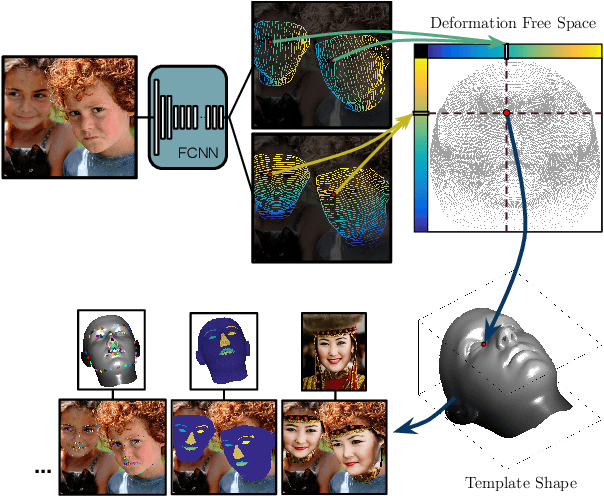
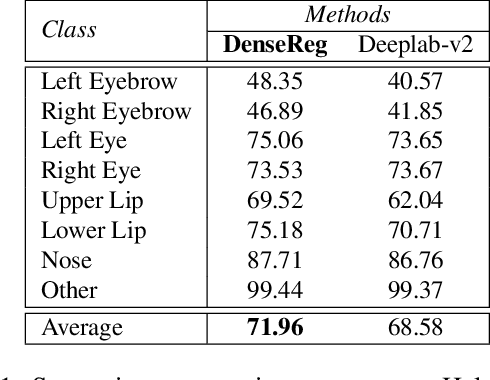
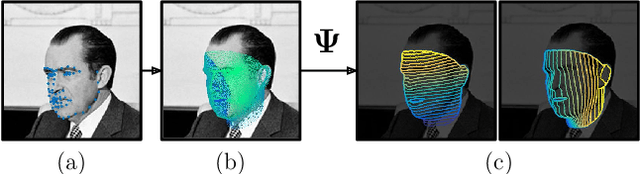
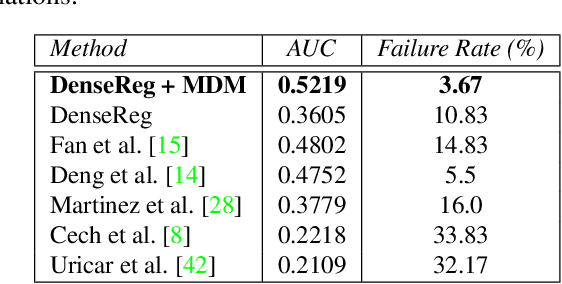
In this work we use deep learning to establish dense correspondences between a 3D object model and an image "in the wild". We introduce "DenseReg", a fully-convolutional neural network (F-CNN) that densely regresses at every foreground pixel a pair of U-V template coordinates in a single feedforward pass. To train DenseReg we construct a supervision signal by combining 3D deformable model fitting and 2D landmark annotations. We define the regression task in terms of the intrinsic, U-V coordinates of a 3D deformable model that is brought into correspondence with image instances at training time. A host of other object-related tasks (e.g. part segmentation, landmark localization) are shown to be by-products of this task, and to largely improve thanks to its introduction. We obtain highly-accurate regression results by combining ideas from semantic segmentation with regression networks, yielding a 'quantized regression' architecture that first obtains a quantized estimate of position through classification, and refines it through regression of the residual. We show that such networks can boost the performance of existing state-of-the-art systems for pose estimation. Firstly, we show that our system can serve as an initialization for Statistical Deformable Models, as well as an element of cascaded architectures that jointly localize landmarks and estimate dense correspondences. We also show that the obtained dense correspondence can act as a source of 'privileged information' that complements and extends the pure landmark-level annotations, accelerating and improving the training of pose estimation networks. We report state-of-the-art performance on the challenging 300W benchmark for facial landmark localization and on the MPII and LSP datasets for human pose estimation.
Joint Multi-view Face Alignment in the Wild
Aug 20, 2017
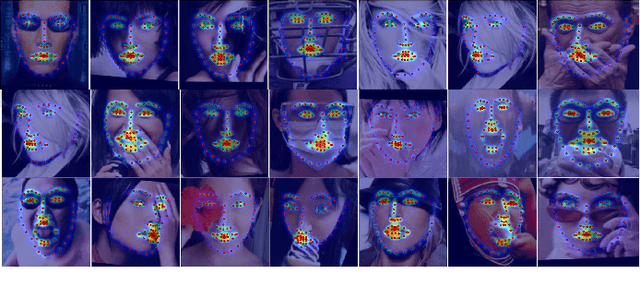
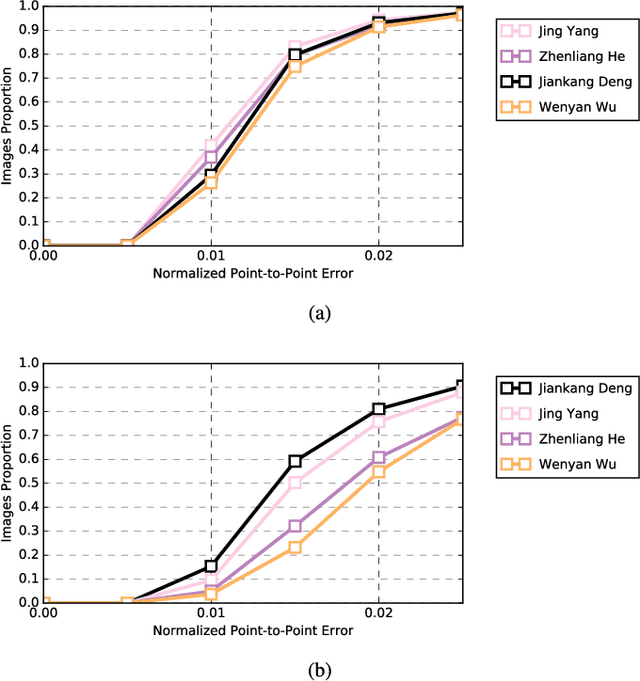

The de facto algorithm for facial landmark estimation involves running a face detector with a subsequent deformable model fitting on the bounding box. This encompasses two basic problems: i) the detection and deformable fitting steps are performed independently, while the detector might not provide best-suited initialisation for the fitting step, ii) the face appearance varies hugely across different poses, which makes the deformable face fitting very challenging and thus distinct models have to be used (\eg, one for profile and one for frontal faces). In this work, we propose the first, to the best of our knowledge, joint multi-view convolutional network to handle large pose variations across faces in-the-wild, and elegantly bridge face detection and facial landmark localisation tasks. Existing joint face detection and landmark localisation methods focus only on a very small set of landmarks. By contrast, our method can detect and align a large number of landmarks for semi-frontal (68 landmarks) and profile (39 landmarks) faces. We evaluate our model on a plethora of datasets including standard static image datasets such as IBUG, 300W, COFW, and the latest Menpo Benchmark for both semi-frontal and profile faces. Significant improvement over state-of-the-art methods on deformable face tracking is witnessed on 300VW benchmark. We also demonstrate state-of-the-art results for face detection on FDDB and MALF datasets.
End-to-End Multimodal Emotion Recognition using Deep Neural Networks
Apr 27, 2017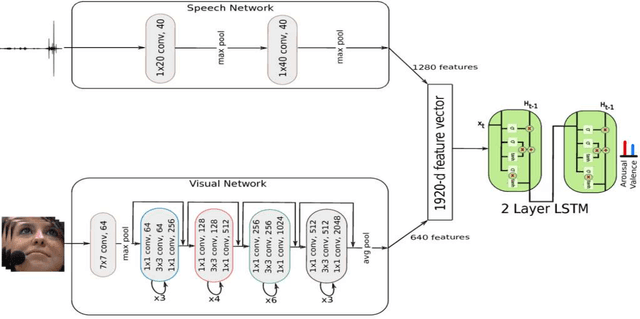
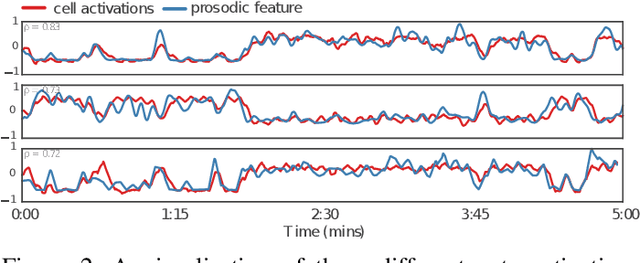
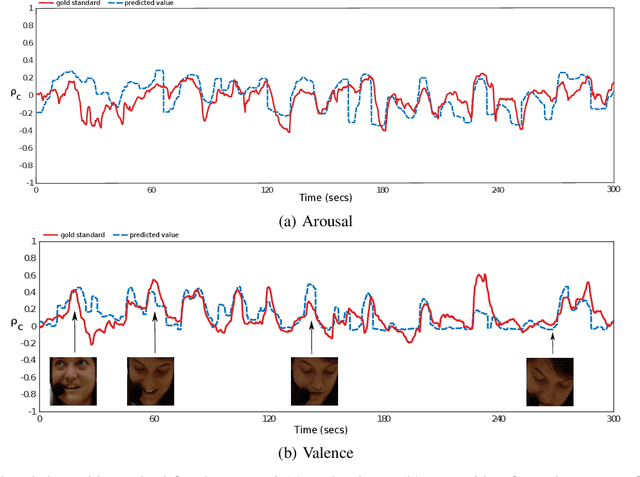

Automatic affect recognition is a challenging task due to the various modalities emotions can be expressed with. Applications can be found in many domains including multimedia retrieval and human computer interaction. In recent years, deep neural networks have been used with great success in determining emotional states. Inspired by this success, we propose an emotion recognition system using auditory and visual modalities. To capture the emotional content for various styles of speaking, robust features need to be extracted. To this purpose, we utilize a Convolutional Neural Network (CNN) to extract features from the speech, while for the visual modality a deep residual network (ResNet) of 50 layers. In addition to the importance of feature extraction, a machine learning algorithm needs also to be insensitive to outliers while being able to model the context. To tackle this problem, Long Short-Term Memory (LSTM) networks are utilized. The system is then trained in an end-to-end fashion where - by also taking advantage of the correlations of the each of the streams - we manage to significantly outperform the traditional approaches based on auditory and visual handcrafted features for the prediction of spontaneous and natural emotions on the RECOLA database of the AVEC 2016 research challenge on emotion recognition.
3D Face Morphable Models "In-the-Wild"
Jan 19, 2017
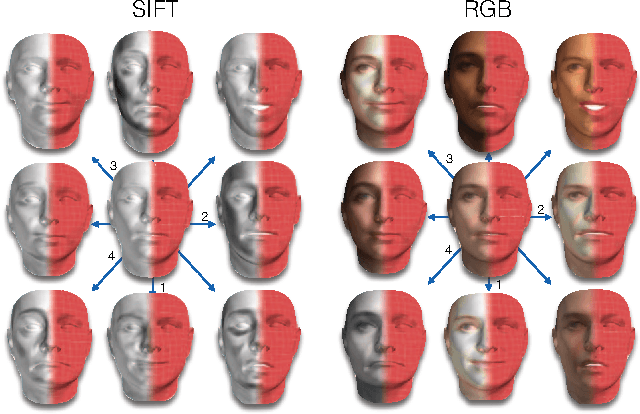

3D Morphable Models (3DMMs) are powerful statistical models of 3D facial shape and texture, and among the state-of-the-art methods for reconstructing facial shape from single images. With the advent of new 3D sensors, many 3D facial datasets have been collected containing both neutral as well as expressive faces. However, all datasets are captured under controlled conditions. Thus, even though powerful 3D facial shape models can be learnt from such data, it is difficult to build statistical texture models that are sufficient to reconstruct faces captured in unconstrained conditions ("in-the-wild"). In this paper, we propose the first, to the best of our knowledge, "in-the-wild" 3DMM by combining a powerful statistical model of facial shape, which describes both identity and expression, with an "in-the-wild" texture model. We show that the employment of such an "in-the-wild" texture model greatly simplifies the fitting procedure, because there is no need to optimize with regards to the illumination parameters. Furthermore, we propose a new fast algorithm for fitting the 3DMM in arbitrary images. Finally, we have captured the first 3D facial database with relatively unconstrained conditions and report quantitative evaluations with state-of-the-art performance. Complementary qualitative reconstruction results are demonstrated on standard "in-the-wild" facial databases. An open source implementation of our technique is released as part of the Menpo Project.
Domain Separation Networks
Aug 22, 2016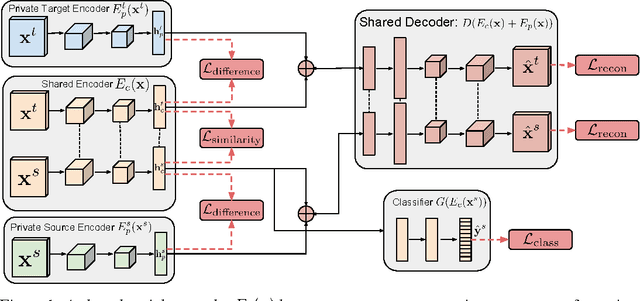
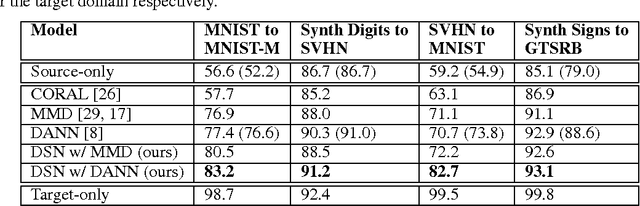
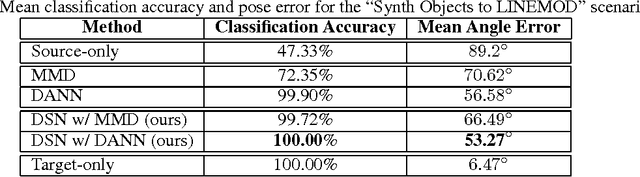

The cost of large scale data collection and annotation often makes the application of machine learning algorithms to new tasks or datasets prohibitively expensive. One approach circumventing this cost is training models on synthetic data where annotations are provided automatically. Despite their appeal, such models often fail to generalize from synthetic to real images, necessitating domain adaptation algorithms to manipulate these models before they can be successfully applied. Existing approaches focus either on mapping representations from one domain to the other, or on learning to extract features that are invariant to the domain from which they were extracted. However, by focusing only on creating a mapping or shared representation between the two domains, they ignore the individual characteristics of each domain. We suggest that explicitly modeling what is unique to each domain can improve a model's ability to extract domain-invariant features. Inspired by work on private-shared component analysis, we explicitly learn to extract image representations that are partitioned into two subspaces: one component which is private to each domain and one which is shared across domains. Our model is trained not only to perform the task we care about in the source domain, but also to use the partitioned representation to reconstruct the images from both domains. Our novel architecture results in a model that outperforms the state-of-the-art on a range of unsupervised domain adaptation scenarios and additionally produces visualizations of the private and shared representations enabling interpretation of the domain adaptation process.
A deep matrix factorization method for learning attribute representations
Sep 10, 2015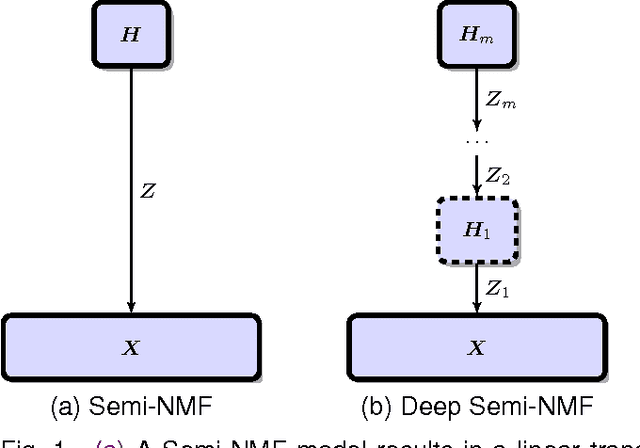
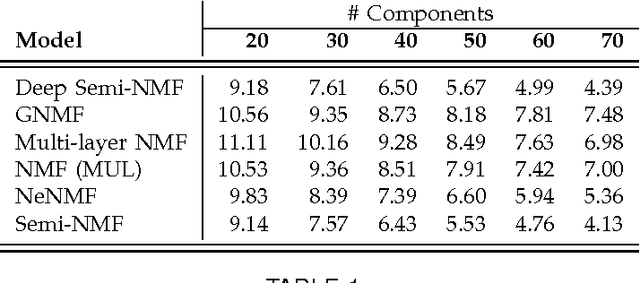
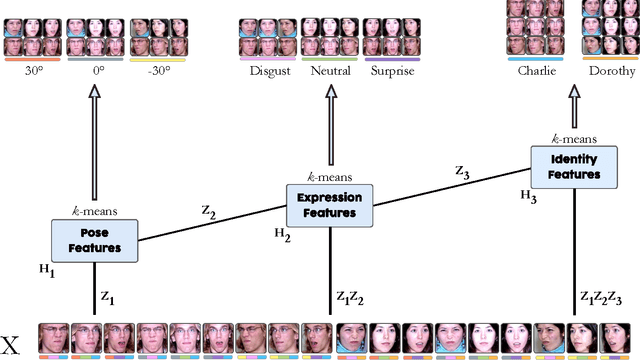

Semi-Non-negative Matrix Factorization is a technique that learns a low-dimensional representation of a dataset that lends itself to a clustering interpretation. It is possible that the mapping between this new representation and our original data matrix contains rather complex hierarchical information with implicit lower-level hidden attributes, that classical one level clustering methodologies can not interpret. In this work we propose a novel model, Deep Semi-NMF, that is able to learn such hidden representations that allow themselves to an interpretation of clustering according to different, unknown attributes of a given dataset. We also present a semi-supervised version of the algorithm, named Deep WSF, that allows the use of (partial) prior information for each of the known attributes of a dataset, that allows the model to be used on datasets with mixed attribute knowledge. Finally, we show that our models are able to learn low-dimensional representations that are better suited for clustering, but also classification, outperforming Semi-Non-negative Matrix Factorization, but also other state-of-the-art methodologies variants.