 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning From Noisy Labels By Regularized Estimation Of Annotator Confusion
Feb 10, 2019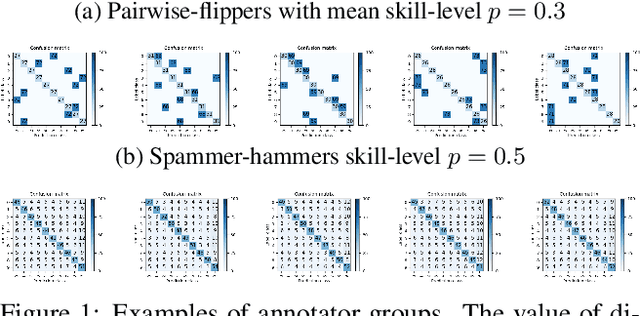
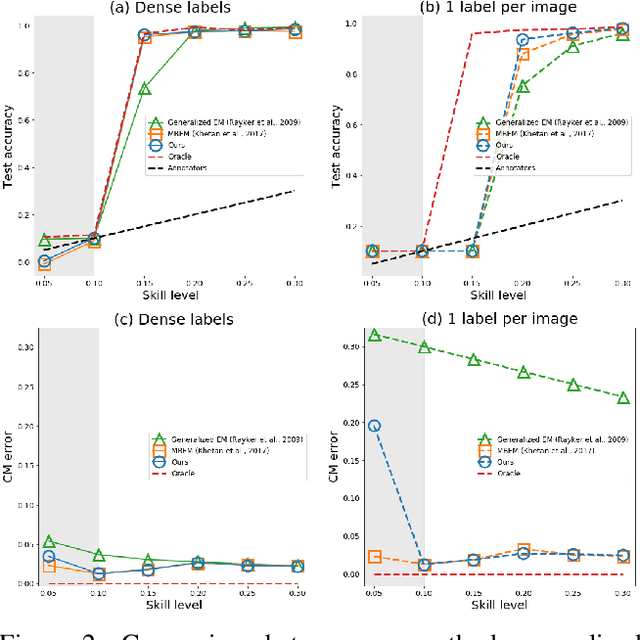
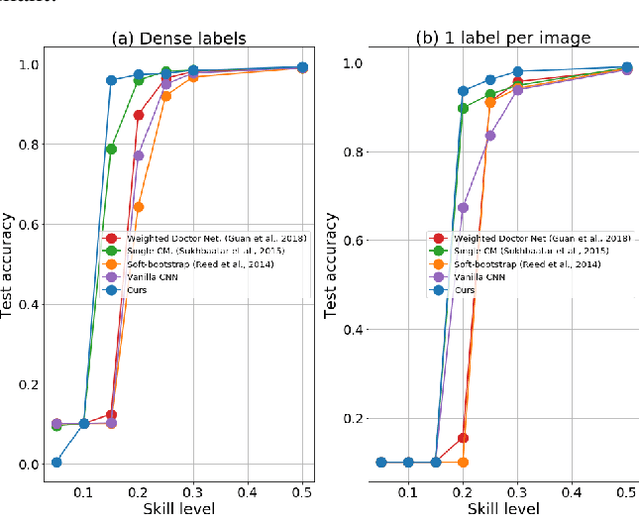
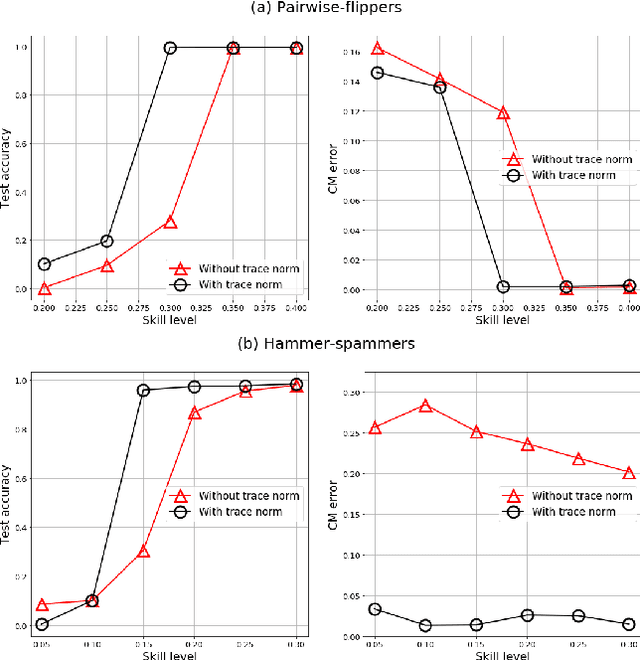
The predictive performance of supervised learning algorithms depends on the quality of labels. In a typical label collection process, multiple annotators provide subjective noisy estimates of the "truth" under the influence of their varying skill-levels and biases. Blindly treating these noisy labels as the ground truth limits the accuracy of learning algorithms in the presence of strong disagreement. This problem is critical for applications in domains such as medical imaging where both the annotation cost and inter-observer variability are high. In this work, we present a method for simultaneously learning the individual annotator model and the underlying true label distribution, using only noisy observations. Each annotator is modeled by a confusion matrix that is jointly estimated along with the classifier predictions. We propose to add a regularization term to the loss function that encourages convergence to the true annotator confusion matrix. We provide a theoretical argument as to how the regularization is essential to our approach both for the case of single annotator and multiple annotators. Despite the simplicity of the idea, experiments on image classification tasks with both simulated and real labels show that our method either outperforms or performs on par with the state-of-the-art methods and is capable of estimating the skills of annotators even with a single label available per image.
Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial Networks
Aug 23, 2017
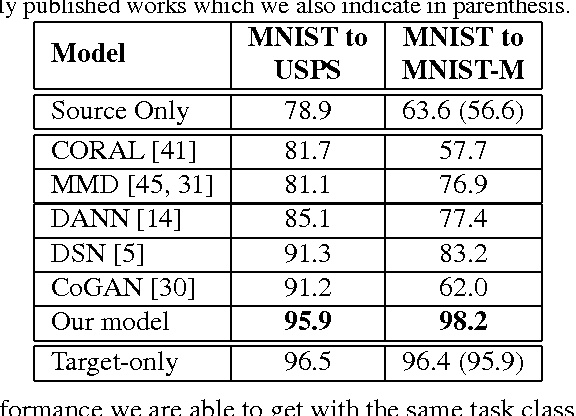
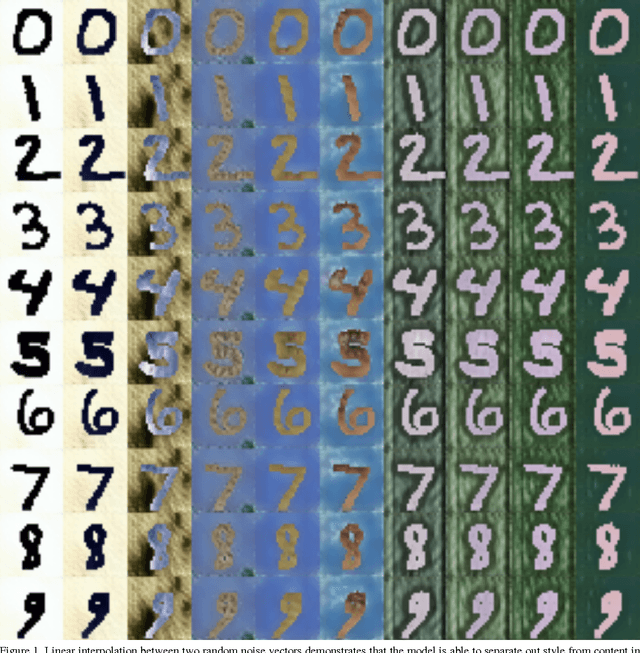
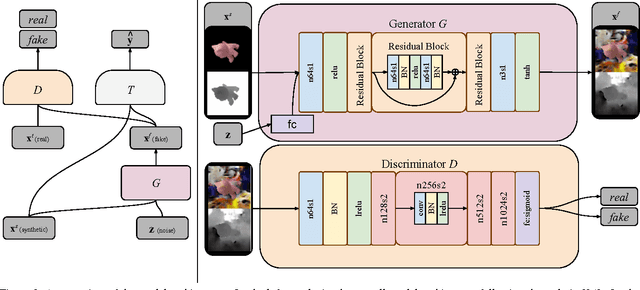
Collecting well-annotated image datasets to train modern machine learning algorithms is prohibitively expensive for many tasks. One appealing alternative is rendering synthetic data where ground-truth annotations are generated automatically. Unfortunately, models trained purely on rendered images often fail to generalize to real images. To address this shortcoming, prior work introduced unsupervised domain adaptation algorithms that attempt to map representations between the two domains or learn to extract features that are domain-invariant. In this work, we present a new approach that learns, in an unsupervised manner, a transformation in the pixel space from one domain to the other. Our generative adversarial network (GAN)-based method adapts source-domain images to appear as if drawn from the target domain. Our approach not only produces plausible samples, but also outperforms the state-of-the-art on a number of unsupervised domain adaptation scenarios by large margins. Finally, we demonstrate that the adaptation process generalizes to object classes unseen during training.
The Devil is in the Decoder
Aug 12, 2017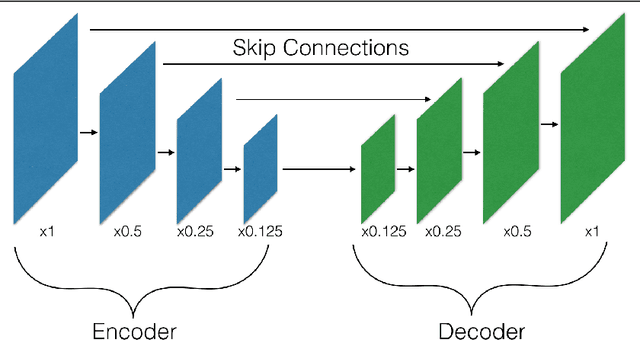

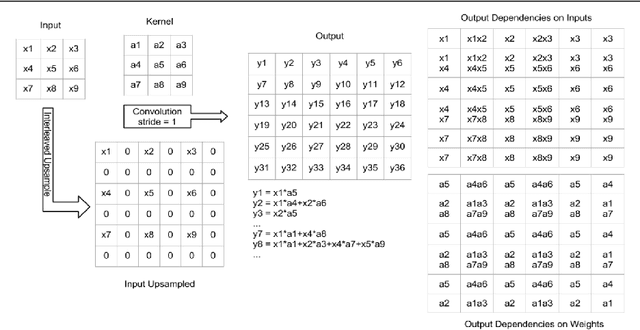
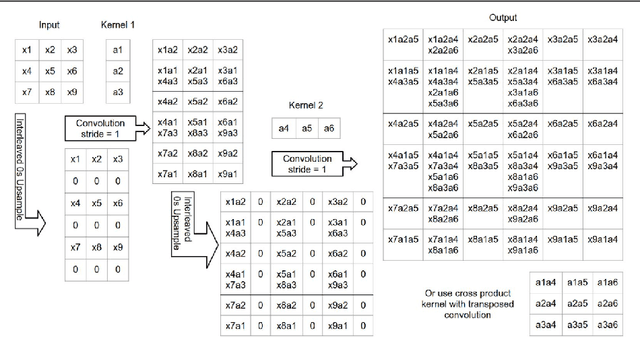
Many machine vision applications require predictions for every pixel of the input image (for example semantic segmentation, boundary detection). Models for such problems usually consist of encoders which decreases spatial resolution while learning a high-dimensional representation, followed by decoders who recover the original input resolution and result in low-dimensional predictions. While encoders have been studied rigorously, relatively few studies address the decoder side. Therefore this paper presents an extensive comparison of a variety of decoders for a variety of pixel-wise prediction tasks. Our contributions are: (1) Decoders matter: we observe significant variance in results between different types of decoders on various problems. (2) We introduce a novel decoder: bilinear additive upsampling. (3) We introduce new residual-like connections for decoders. (4) We identify two decoder types which give a consistently high performance.
Domain Separation Networks
Aug 22, 2016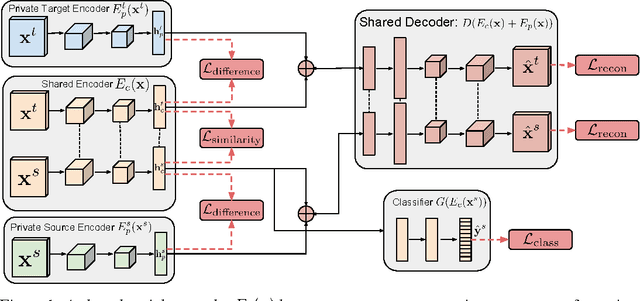
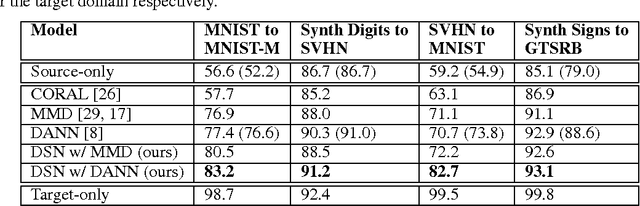
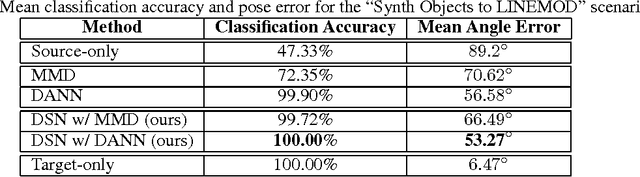

The cost of large scale data collection and annotation often makes the application of machine learning algorithms to new tasks or datasets prohibitively expensive. One approach circumventing this cost is training models on synthetic data where annotations are provided automatically. Despite their appeal, such models often fail to generalize from synthetic to real images, necessitating domain adaptation algorithms to manipulate these models before they can be successfully applied. Existing approaches focus either on mapping representations from one domain to the other, or on learning to extract features that are invariant to the domain from which they were extracted. However, by focusing only on creating a mapping or shared representation between the two domains, they ignore the individual characteristics of each domain. We suggest that explicitly modeling what is unique to each domain can improve a model's ability to extract domain-invariant features. Inspired by work on private-shared component analysis, we explicitly learn to extract image representations that are partitioned into two subspaces: one component which is private to each domain and one which is shared across domains. Our model is trained not only to perform the task we care about in the source domain, but also to use the partitioned representation to reconstruct the images from both domains. Our novel architecture results in a model that outperforms the state-of-the-art on a range of unsupervised domain adaptation scenarios and additionally produces visualizations of the private and shared representations enabling interpretation of the domain adaptation process.