 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenseReg: Fully Convolutional Dense Shape Regression In-the-Wild
Mar 11, 2018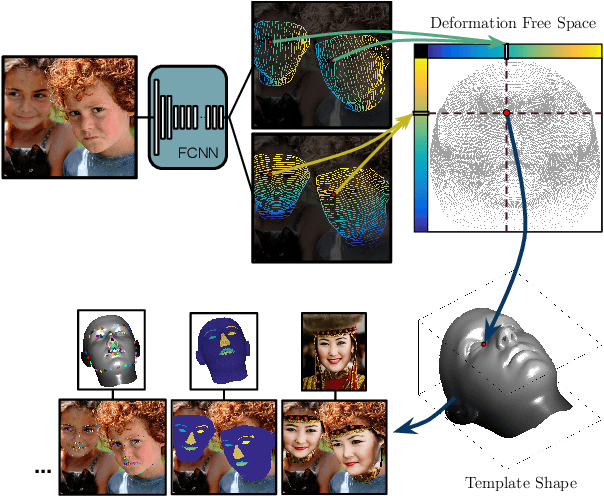
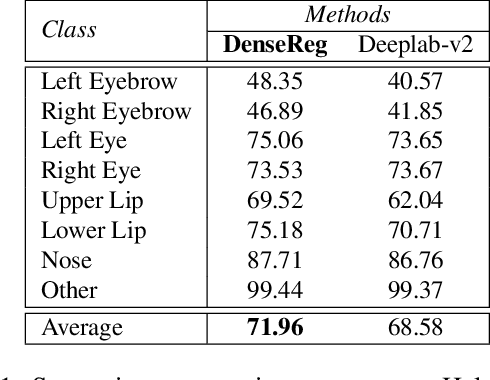
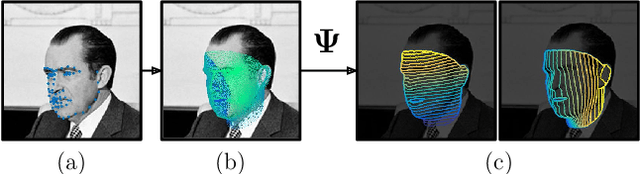
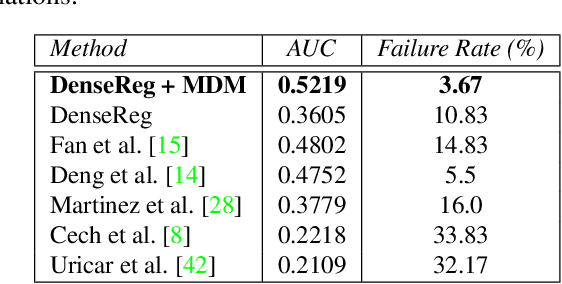
In this work we use deep learning to establish dense correspondences between a 3D object model and an image "in the wild". We introduce "DenseReg", a fully-convolutional neural network (F-CNN) that densely regresses at every foreground pixel a pair of U-V template coordinates in a single feedforward pass. To train DenseReg we construct a supervision signal by combining 3D deformable model fitting and 2D landmark annotations. We define the regression task in terms of the intrinsic, U-V coordinates of a 3D deformable model that is brought into correspondence with image instances at training time. A host of other object-related tasks (e.g. part segmentation, landmark localization) are shown to be by-products of this task, and to largely improve thanks to its introduction. We obtain highly-accurate regression results by combining ideas from semantic segmentation with regression networks, yielding a 'quantized regression' architecture that first obtains a quantized estimate of position through classification, and refines it through regression of the residual. We show that such networks can boost the performance of existing state-of-the-art systems for pose estimation. Firstly, we show that our system can serve as an initialization for Statistical Deformable Models, as well as an element of cascaded architectures that jointly localize landmarks and estimate dense correspondences. We also show that the obtained dense correspondence can act as a source of 'privileged information' that complements and extends the pure landmark-level annotations, accelerating and improving the training of pose estimation networks. We report state-of-the-art performance on the challenging 300W benchmark for facial landmark localization and on the MPII and LSP datasets for human pose estimation.
A Comprehensive Performance Evaluation of Deformable Face Tracking "In-the-Wild"
Feb 28, 2017

Recently, technologies such as face detection, facial landmark localisation and face recognition and verification have matured enough to provide effective and efficient solutions for imagery captured under arbitrary conditions (referred to as "in-the-wild"). This is partially attributed to the fact that comprehensive "in-the-wild" benchmarks have been developed for face detection, landmark localisation and recognition/verification. A very important technology that has not been thoroughly evaluated yet is deformable face tracking "in-the-wild". Until now, the performance has mainly been assessed qualitatively by visually assessing the result of a deformable face tracking technology on short videos. In this paper, we perform the first, to the best of our knowledge, thorough evaluation of state-of-the-art deformable face tracking pipelines using the recently introduced 300VW benchmark. We evaluate many different architectures focusing mainly on the task of on-line deformable face tracking. In particular, we compare the following general strategies: (a) generic face detection plus generic facial landmark localisation, (b) generic model free tracking plus generic facial landmark localisation, as well as (c) hybrid approaches using state-of-the-art face detection, model free tracking and facial landmark localisation technologies. Our evaluation reveals future avenues for further research on the topic.
3D Face Morphable Models "In-the-Wild"
Jan 19, 2017
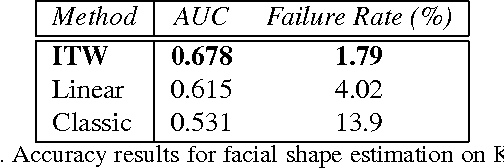
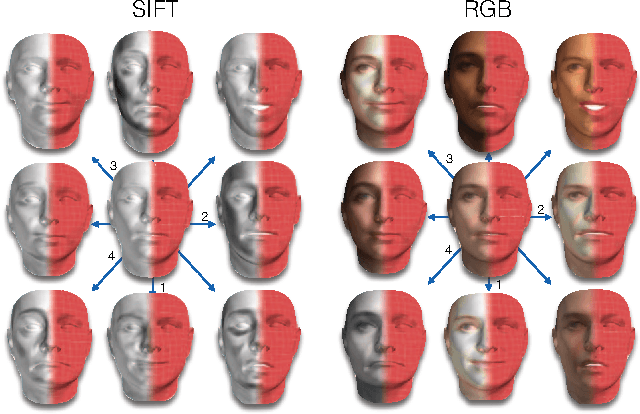

3D Morphable Models (3DMMs) are powerful statistical models of 3D facial shape and texture, and among the state-of-the-art methods for reconstructing facial shape from single images. With the advent of new 3D sensors, many 3D facial datasets have been collected containing both neutral as well as expressive faces. However, all datasets are captured under controlled conditions. Thus, even though powerful 3D facial shape models can be learnt from such data, it is difficult to build statistical texture models that are sufficient to reconstruct faces captured in unconstrained conditions ("in-the-wild"). In this paper, we propose the first, to the best of our knowledge, "in-the-wild" 3DMM by combining a powerful statistical model of facial shape, which describes both identity and expression, with an "in-the-wild" texture model. We show that the employment of such an "in-the-wild" texture model greatly simplifies the fitting procedure, because there is no need to optimize with regards to the illumination parameters. Furthermore, we propose a new fast algorithm for fitting the 3DMM in arbitrary images. Finally, we have captured the first 3D facial database with relatively unconstrained conditions and report quantitative evaluations with state-of-the-art performance. Complementary qualitative reconstruction results are demonstrated on standard "in-the-wild" facial databases. An open source implementation of our technique is released as part of the Menpo Project.