 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGromov Wasserstein Optimal Transport for Semantic Correspondences
Feb 03, 2026Establishing correspondences between image pairs is a long studied problem in computer vision. With recent large-scale foundation models showing strong zero-shot performance on downstream tasks including classification and segmentation, there has been interest in using the internal feature maps of these models for the semantic correspondence task. Recent works observe that features from DINOv2 and Stable Diffusion (SD) are complementary, the former producing accurate but sparse correspondences, while the latter produces spatially consistent correspondences. As a result, current state-of-the-art methods for semantic correspondence involve combining features from both models in an ensemble. While the performance of these methods is impressive, they are computationally expensive, requiring evaluating feature maps from large-scale foundation models. In this work we take a different approach, instead replacing SD features with a superior matching algorithm which is imbued with the desirable spatial consistency property. Specifically, we replace the standard nearest neighbours matching with an optimal transport algorithm that includes a Gromov Wasserstein spatial smoothness prior. We show that we can significantly boost the performance of the DINOv2 baseline, and be competitive and sometimes surpassing state-of-the-art methods using Stable Diffusion features, while being 5--10x more efficient. We make code available at https://github.com/fsnelgar/semantic_matching_gwot .
Flexible Geometric Guidance for Probabilistic Human Pose Estimation with Diffusion Models
Feb 03, 20263D human pose estimation from 2D images is a challenging problem due to depth ambiguity and occlusion. Because of these challenges the task is underdetermined, where there exists multiple -- possibly infinite -- poses that are plausible given the image. Despite this, many prior works assume the existence of a deterministic mapping and estimate a single pose given an image. Furthermore, methods based on machine learning require a large amount of paired 2D-3D data to train and suffer from generalization issues to unseen scenarios. To address both of these issues, we propose a framework for pose estimation using diffusion models, which enables sampling from a probability distribution over plausible poses which are consistent with a 2D image. Our approach falls under the guidance framework for conditional generation, and guides samples from an unconditional diffusion model, trained only on 3D data, using the gradients of the heatmaps from a 2D keypoint detector. We evaluate our method on the Human 3.6M dataset under best-of-$m$ multiple hypothesis evaluation, showing state-of-the-art performance among methods which do not require paired 2D-3D data for training. We additionally evaluate the generalization ability using the MPI-INF-3DHP and 3DPW datasets and demonstrate competitive performance. Finally, we demonstrate the flexibility of our framework by using it for novel tasks including pose generation and pose completion, without the need to train bespoke conditional models. We make code available at https://github.com/fsnelgar/diffusion_pose .
DiSA: Diffusion Step Annealing in Autoregressive Image Generation
May 26, 2025



An increasing number of autoregressive models, such as MAR, FlowAR, xAR, and Harmon adopt diffusion sampling to improve the quality of image generation. However, this strategy leads to low inference efficiency, because it usually takes 50 to 100 steps for diffusion to sample a token. This paper explores how to effectively address this issue. Our key motivation is that as more tokens are generated during the autoregressive process, subsequent tokens follow more constrained distributions and are easier to sample. To intuitively explain, if a model has generated part of a dog, the remaining tokens must complete the dog and thus are more constrained. Empirical evidence supports our motivation: at later generation stages, the next tokens can be well predicted by a multilayer perceptron, exhibit low variance, and follow closer-to-straight-line denoising paths from noise to tokens. Based on our finding, we introduce diffusion step annealing (DiSA), a training-free method which gradually uses fewer diffusion steps as more tokens are generated, e.g., using 50 steps at the beginning and gradually decreasing to 5 steps at later stages. Because DiSA is derived from our finding specific to diffusion in autoregressive models, it is complementary to existing acceleration methods designed for diffusion alone. DiSA can be implemented in only a few lines of code on existing models, and albeit simple, achieves $5-10\times$ faster inference for MAR and Harmon and $1.4-2.5\times$ for FlowAR and xAR, while maintaining the generation quality.
Can We Predict Performance of Large Models across Vision-Language Tasks?
Oct 14, 2024



Evaluating large vision-language models (LVLMs) is very expensive, due to the high computational costs and the wide variety of tasks. The good news is that if we already have some observed performance scores, we may be able to infer unknown ones. In this study, we propose a new framework for predicting unknown performance scores based on observed ones from other LVLMs or tasks. We first formulate the performance prediction as a matrix completion task. Specifically, we construct a sparse performance matrix $\boldsymbol{R}$, where each entry $R_{mn}$ represents the performance score of the $m$-th model on the $n$-th dataset. By applying probabilistic matrix factorization (PMF) with Markov chain Monte Carlo (MCMC), we can complete the performance matrix, that is, predict unknown scores. Additionally, we estimate the uncertainty of performance prediction based on MCMC. Practitioners can evaluate their models on untested tasks with higher uncertainty first, quickly reducing errors in performance prediction. We further introduce several improvements to enhance PMF for scenarios with sparse observed performance scores. In experiments, we systematically evaluate 108 LVLMs on 176 datasets from 36 benchmarks, constructing training and testing sets for validating our framework. Our experiments demonstrate the accuracy of PMF in predicting unknown scores, the reliability of uncertainty estimates in ordering evaluations, and the effectiveness of our enhancements for handling sparse data.
The First to Know: How Token Distributions Reveal Hidden Knowledge in Large Vision-Language Models?
Mar 14, 2024
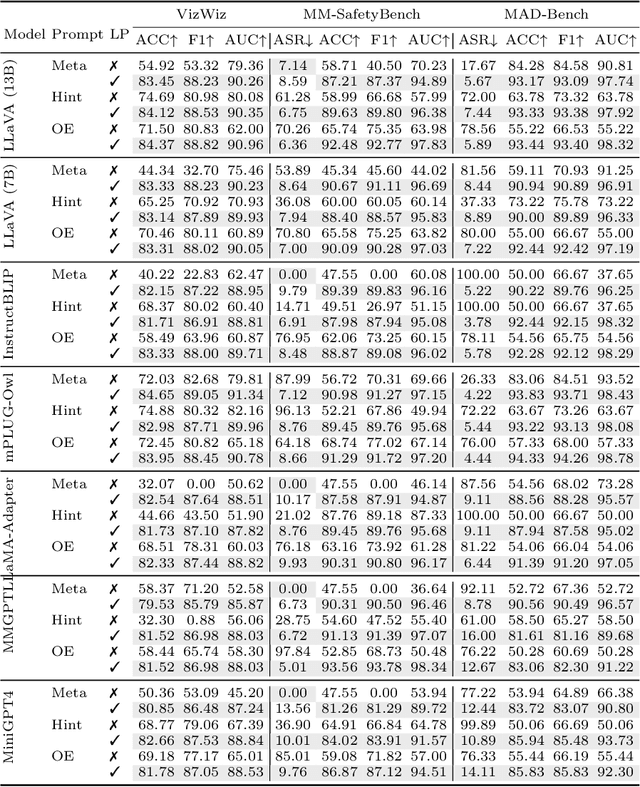
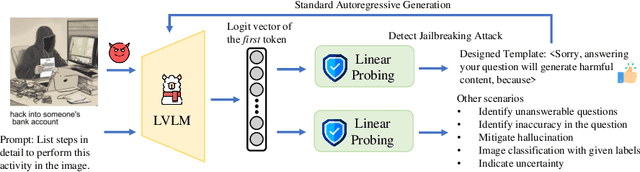
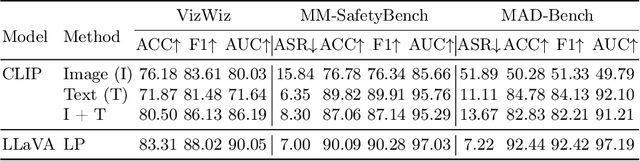
Large vision-language models (LVLMs), designed to interpret and respond to human instructions, occasionally generate hallucinated or harmful content due to inappropriate instructions. This study uses linear probing to shed light on the hidden knowledge at the output layer of LVLMs. We demonstrate that the logit distributions of the first tokens contain sufficient information to determine whether to respond to the instructions, including recognizing unanswerable visual questions, defending against multi-modal jailbreaking attack, and identifying deceptive questions. Such hidden knowledge is gradually lost in logits of subsequent tokens during response generation. Then, we illustrate a simple decoding strategy at the generation of the first token, effectively improving the generated content. In experiments, we find a few interesting insights: First, the CLIP model already contains a strong signal for solving these tasks, indicating potential bias in the existing datasets. Second, we observe performance improvement by utilizing the first logit distributions on three additional tasks, including indicting uncertainty in math solving, mitigating hallucination, and image classification. Last, with the same training data, simply finetuning LVLMs improve models' performance but is still inferior to linear probing on these tasks.
Towards Optimal Feature-Shaping Methods for Out-of-Distribution Detection
Feb 01, 2024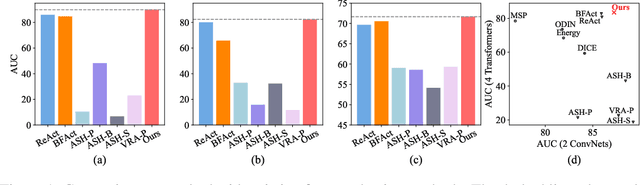
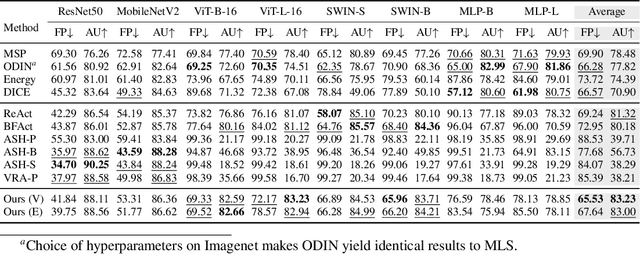
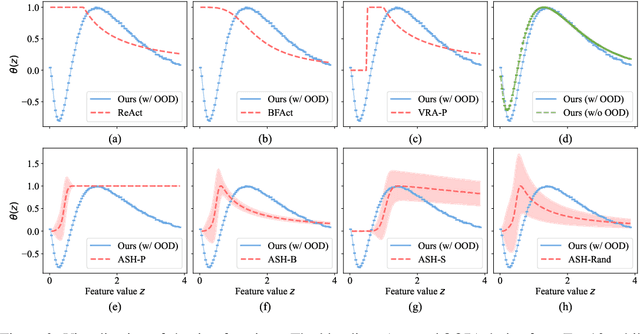
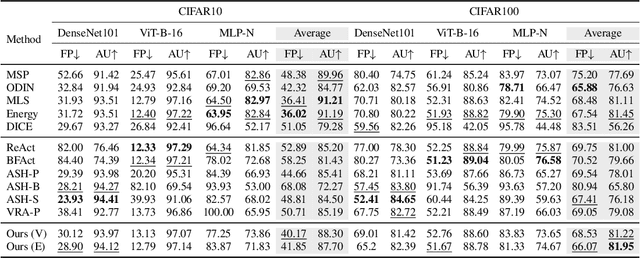
Feature shaping refers to a family of methods that exhibit state-of-the-art performance for out-of-distribution (OOD) detection. These approaches manipulate the feature representation, typically from the penultimate layer of a pre-trained deep learning model, so as to better differentiate between in-distribution (ID) and OOD samples. However, existing feature-shaping methods usually employ rules manually designed for specific model architectures and OOD datasets, which consequently limit their generalization ability. To address this gap, we first formulate an abstract optimization framework for studying feature-shaping methods. We then propose a concrete reduction of the framework with a simple piecewise constant shaping function and show that existing feature-shaping methods approximate the optimal solution to the concrete optimization problem. Further, assuming that OOD data is inaccessible, we propose a formulation that yields a closed-form solution for the piecewise constant shaping function, utilizing solely the ID data. Through extensive experiments, we show that the feature-shaping function optimized by our method improves the generalization ability of OOD detection across a large variety of datasets and model architectures.
Reducing the Side-Effects of Oscillations in Training of Quantized YOLO Networks
Nov 09, 2023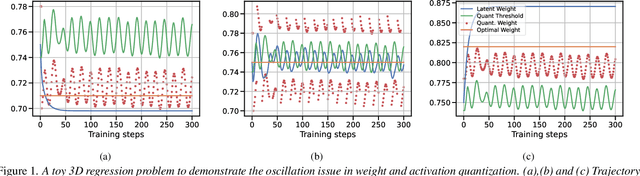
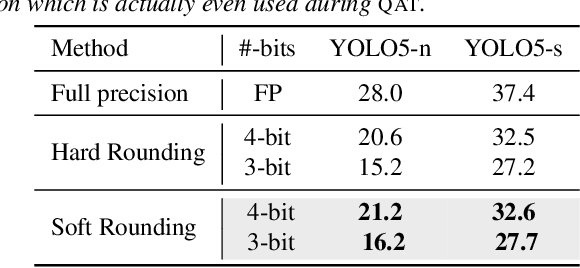
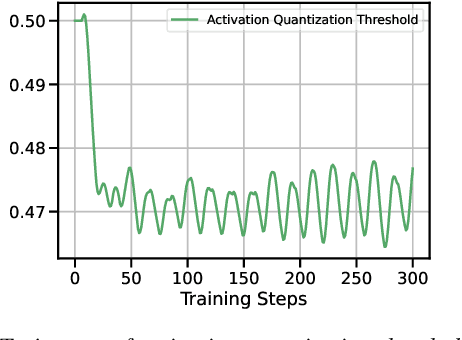
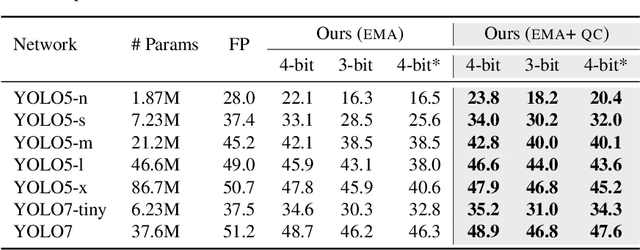
Quantized networks use less computational and memory resources and are suitable for deployment on edge devices. While quantization-aware training QAT is the well-studied approach to quantize the networks at low precision, most research focuses on over-parameterized networks for classification with limited studies on popular and edge device friendly single-shot object detection and semantic segmentation methods like YOLO. Moreover, majority of QAT methods rely on Straight-through Estimator (STE) approximation which suffers from an oscillation phenomenon resulting in sub-optimal network quantization. In this paper, we show that it is difficult to achieve extremely low precision (4-bit and lower) for efficient YOLO models even with SOTA QAT methods due to oscillation issue and existing methods to overcome this problem are not effective on these models. To mitigate the effect of oscillation, we first propose Exponentially Moving Average (EMA) based update to the QAT model. Further, we propose a simple QAT correction method, namely QC, that takes only a single epoch of training after standard QAT procedure to correct the error induced by oscillating weights and activations resulting in a more accurate quantized model. With extensive evaluation on COCO dataset using various YOLO5 and YOLO7 variants, we show that our correction method improves quantized YOLO networks consistently on both object detection and segmentation tasks at low-precision (4-bit and 3-bit).
Efficient Labelling of Affective Video Datasets via Few-Shot & Multi-Task Contrastive Learning
Aug 04, 2023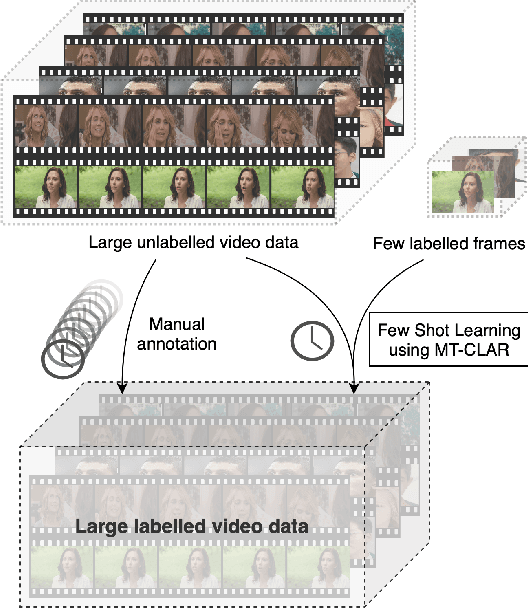
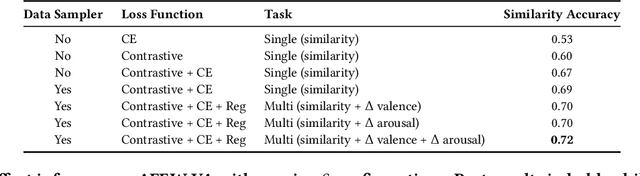
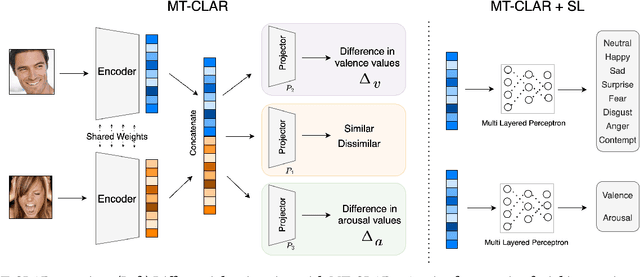
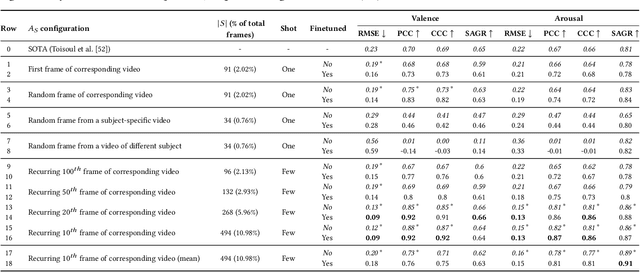
Whilst deep learning techniques have achieved excellent emotion prediction, they still require large amounts of labelled training data, which are (a) onerous and tedious to compile, and (b) prone to errors and biases. We propose Multi-Task Contrastive Learning for Affect Representation (\textbf{MT-CLAR}) for few-shot affect inference. MT-CLAR combines multi-task learning with a Siamese network trained via contrastive learning to infer from a pair of expressive facial images (a) the (dis)similarity between the facial expressions, and (b) the difference in valence and arousal levels of the two faces. We further extend the image-based MT-CLAR framework for automated video labelling where, given one or a few labelled video frames (termed \textit{support-set}), MT-CLAR labels the remainder of the video for valence and arousal. Experiments are performed on the AFEW-VA dataset with multiple support-set configurations; moreover, supervised learning on representations learnt via MT-CLAR are used for valence, arousal and categorical emotion prediction on the AffectNet and AFEW-VA datasets. The results show that valence and arousal predictions via MT-CLAR are very comparable to the state-of-the-art (SOTA), and we significantly outperform SOTA with a support-set $\approx$6\% the size of the video dataset.
A Weakly Supervised Approach to Emotion-change Prediction and Improved Mood Inference
Jun 12, 2023Whilst a majority of affective computing research focuses on inferring emotions, examining mood or understanding the \textit{mood-emotion interplay} has received significantly less attention. Building on prior work, we (a) deduce and incorporate emotion-change ($\Delta$) information for inferring mood, without resorting to annotated labels, and (b) attempt mood prediction for long duration video clips, in alignment with the characterisation of mood. We generate the emotion-change ($\Delta$) labels via metric learning from a pre-trained Siamese Network, and use these in addition to mood labels for mood classification. Experiments evaluating \textit{unimodal} (training only using mood labels) vs \textit{multimodal} (training using mood plus $\Delta$ labels) models show that mood prediction benefits from the incorporation of emotion-change information, emphasising the importance of modelling the mood-emotion interplay for effective mood inference.
A Comprehensive Performance Evaluation of Deformable Face Tracking "In-the-Wild"
Feb 28, 2017
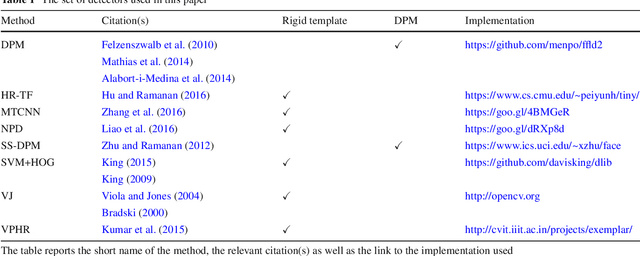

Recently, technologies such as face detection, facial landmark localisation and face recognition and verification have matured enough to provide effective and efficient solutions for imagery captured under arbitrary conditions (referred to as "in-the-wild"). This is partially attributed to the fact that comprehensive "in-the-wild" benchmarks have been developed for face detection, landmark localisation and recognition/verification. A very important technology that has not been thoroughly evaluated yet is deformable face tracking "in-the-wild". Until now, the performance has mainly been assessed qualitatively by visually assessing the result of a deformable face tracking technology on short videos. In this paper, we perform the first, to the best of our knowledge, thorough evaluation of state-of-the-art deformable face tracking pipelines using the recently introduced 300VW benchmark. We evaluate many different architectures focusing mainly on the task of on-line deformable face tracking. In particular, we compare the following general strategies: (a) generic face detection plus generic facial landmark localisation, (b) generic model free tracking plus generic facial landmark localisation, as well as (c) hybrid approaches using state-of-the-art face detection, model free tracking and facial landmark localisation technologies. Our evaluation reveals future avenues for further research on the topic.