 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Split Mamba: Effective State Space Modelling for Image Restoration
Mar 10, 2026Image restoration requires simultaneously preserving fine-grained local structures and maintaining long-range spatial coherence. While convolutional networks struggle with limited receptive fields, and Transformers incur quadratic complexity for global attention, recent State Space Models (SSMs), such as Mamba, provide an appealing linear-time alternative for long-range dependency modelling. However, naively extending Mamba to 2D images exposes two intrinsic shortcomings. First, flattening 2D feature maps into 1D sequences disrupts spatial topology, leading to locality distortion that hampers precise structural recovery. Second, the stability-driven recurrent dynamics of SSMs induce long-range decay, progressively attenuating information across distant spatial positions and weakening global consistency. Together, these effects limit the effectiveness of state-space modelling in high-fidelity restoration. We propose Progressive Split-Mamba (PS-Mamba), a topology-aware hierarchical state-space framework designed to reconcile locality preservation with efficient global propagation. Instead of sequentially flattening entire feature maps, PS-Mamba performs geometry-consistent partitioning, maintaining neighbourhood integrity prior to state-space processing. A progressive split hierarchy (halves, quadrants, octants) enables structured multi-scale modelling while retaining linear complexity. To counteract long-range decay, we introduce symmetric cross-scale shortcut pathways that directly transmit low-frequency global context across hierarchical levels, stabilising information flow over large spatial extents. Extensive experiments on super-resolution, denoising, and JPEG artifact reduction show consistent improvements over recent Mamba-based and attention-based models with a clear margin.
Towards Autonomous Riding: A Review of Perception, Planning, and Control in Intelligent Two-Wheelers
Jul 16, 2025The rapid adoption of micromobility solutions, particularly two-wheeled vehicles like e-scooters and e-bikes, has created an urgent need for reliable autonomous riding (AR) technologies. While autonomous driving (AD) systems have matured significantly, AR presents unique challenges due to the inherent instability of two-wheeled platforms, limited size, limited power, and unpredictable environments, which pose very serious concerns about road users' safety. This review provides a comprehensive analysis of AR systems by systematically examining their core components, perception, planning, and control, through the lens of AD technologies. We identify critical gaps in current AR research, including a lack of comprehensive perception systems for various AR tasks, limited industry and government support for such developments, and insufficient attention from the research community. The review analyses the gaps of AR from the perspective of AD to highlight promising research directions, such as multimodal sensor techniques for lightweight platforms and edge deep learning architectures. By synthesising insights from AD research with the specific requirements of AR, this review aims to accelerate the development of safe, efficient, and scalable autonomous riding systems for future urban mobility.
End-to-End Human Pose Reconstruction from Wearable Sensors for 6G Extended Reality Systems
Mar 06, 2025Full 3D human pose reconstruction is a critical enabler for extended reality (XR) applications in future sixth generation (6G) networks, supporting immersive interactions in gaming, virtual meetings, and remote collaboration. However, achieving accurate pose reconstruction over wireless networks remains challenging due to channel impairments, bit errors, and quantization effects. Existing approaches often assume error-free transmission in indoor settings, limiting their applicability to real-world scenarios. To address these challenges, we propose a novel deep learning-based framework for human pose reconstruction over orthogonal frequency-division multiplexing (OFDM) systems. The framework introduces a two-stage deep learning receiver: the first stage jointly estimates the wireless channel and decodes OFDM symbols, and the second stage maps the received sensor signals to full 3D body poses. Simulation results demonstrate that the proposed neural receiver reduces bit error rate (BER), thus gaining a 5 dB gap at $10^{-4}$ BER, compared to the baseline method that employs separate signal detection steps, i.e., least squares channel estimation and linear minimum mean square error equalization. Additionally, our empirical findings show that 8-bit quantization is sufficient for accurate pose reconstruction, achieving a mean squared error of $5\times10^{-4}$ for reconstructed sensor signals, and reducing joint angular error by 37\% for the reconstructed human poses compared to the baseline.
Bird's-Eye View to Street-View: A Survey
May 14, 2024



In recent years, street view imagery has grown to become one of the most important sources of geospatial data collection and urban analytics, which facilitates generating meaningful insights and assisting in decision-making. Synthesizing a street-view image from its corresponding satellite image is a challenging task due to the significant differences in appearance and viewpoint between the two domains. In this study, we screened 20 recent research papers to provide a thorough review of the state-of-the-art of how street-view images are synthesized from their corresponding satellite counterparts. The main findings are: (i) novel deep learning techniques are required for synthesizing more realistic and accurate street-view images; (ii) more datasets need to be collected for public usage; and (iii) more specific evaluation metrics need to be investigated for evaluating the generated images appropriately. We conclude that, due to applying outdated deep learning techniques, the recent literature failed to generate detailed and diverse street-view images.
Efficient Labelling of Affective Video Datasets via Few-Shot & Multi-Task Contrastive Learning
Aug 04, 2023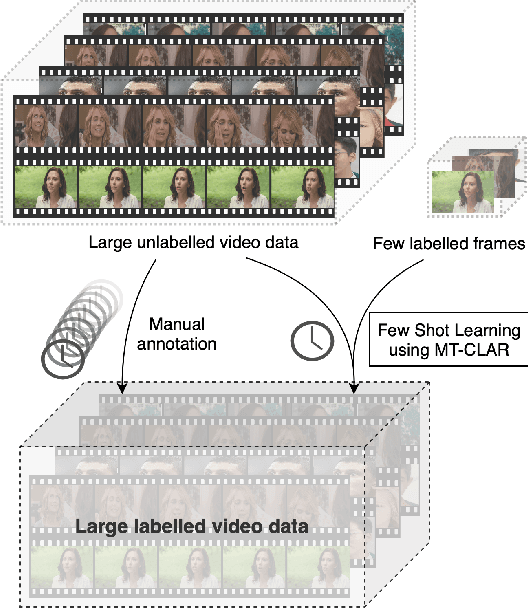
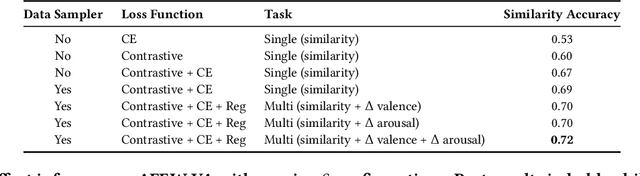
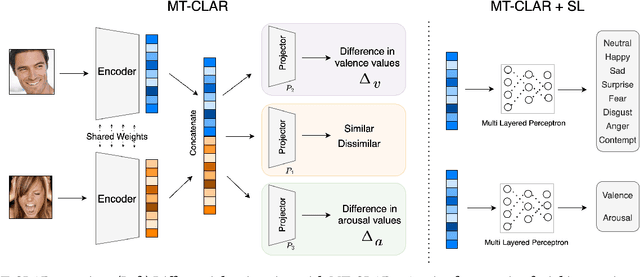
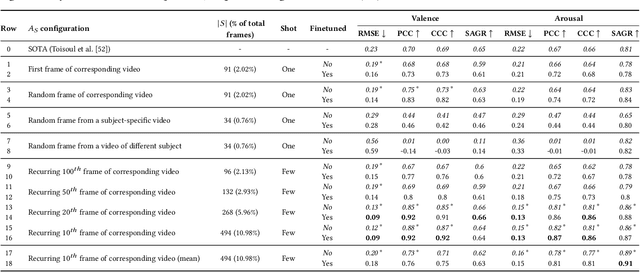
Whilst deep learning techniques have achieved excellent emotion prediction, they still require large amounts of labelled training data, which are (a) onerous and tedious to compile, and (b) prone to errors and biases. We propose Multi-Task Contrastive Learning for Affect Representation (\textbf{MT-CLAR}) for few-shot affect inference. MT-CLAR combines multi-task learning with a Siamese network trained via contrastive learning to infer from a pair of expressive facial images (a) the (dis)similarity between the facial expressions, and (b) the difference in valence and arousal levels of the two faces. We further extend the image-based MT-CLAR framework for automated video labelling where, given one or a few labelled video frames (termed \textit{support-set}), MT-CLAR labels the remainder of the video for valence and arousal. Experiments are performed on the AFEW-VA dataset with multiple support-set configurations; moreover, supervised learning on representations learnt via MT-CLAR are used for valence, arousal and categorical emotion prediction on the AffectNet and AFEW-VA datasets. The results show that valence and arousal predictions via MT-CLAR are very comparable to the state-of-the-art (SOTA), and we significantly outperform SOTA with a support-set $\approx$6\% the size of the video dataset.
A Weakly Supervised Approach to Emotion-change Prediction and Improved Mood Inference
Jun 12, 2023Whilst a majority of affective computing research focuses on inferring emotions, examining mood or understanding the \textit{mood-emotion interplay} has received significantly less attention. Building on prior work, we (a) deduce and incorporate emotion-change ($\Delta$) information for inferring mood, without resorting to annotated labels, and (b) attempt mood prediction for long duration video clips, in alignment with the characterisation of mood. We generate the emotion-change ($\Delta$) labels via metric learning from a pre-trained Siamese Network, and use these in addition to mood labels for mood classification. Experiments evaluating \textit{unimodal} (training only using mood labels) vs \textit{multimodal} (training using mood plus $\Delta$ labels) models show that mood prediction benefits from the incorporation of emotion-change information, emphasising the importance of modelling the mood-emotion interplay for effective mood inference.
Visual Attention Methods in Deep Learning: An In-Depth Survey
Apr 21, 2022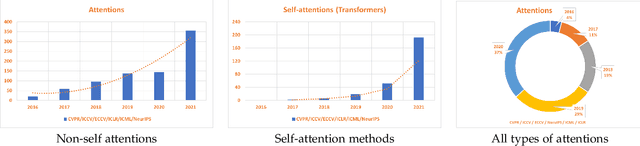
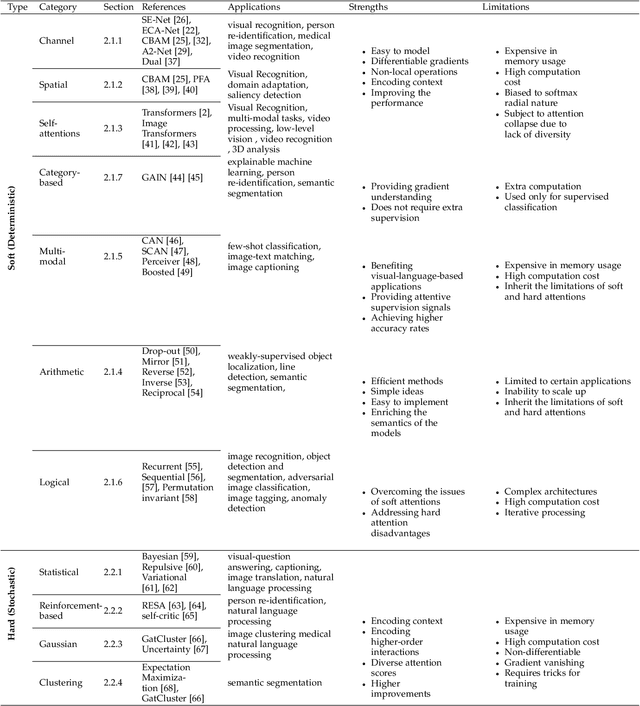
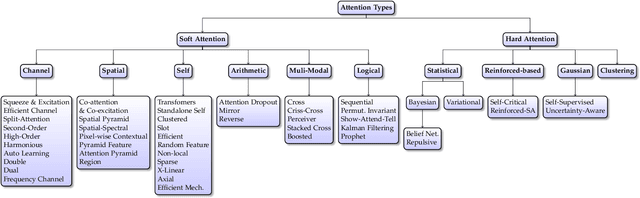
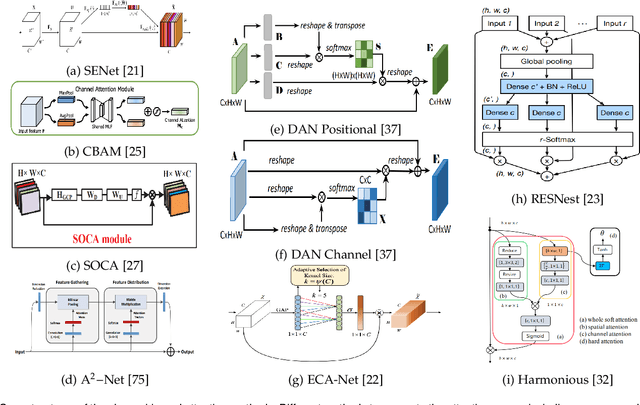
Inspired by the human cognitive system, attention is a mechanism that imitates the human cognitive awareness about specific information, amplifying critical details to focus more on the essential aspects of data. Deep learning has employed attention to boost performance for many applications. Interestingly, the same attention design can suit processing different data modalities and can easily be incorporated into large networks. Furthermore, multiple complementary attention mechanisms can be incorporated in one network. Hence, attention techniques have become extremely attractive. However, the literature lacks a comprehensive survey specific to attention techniques to guide researchers in employing attention in their deep models. Note that, besides being demanding in terms of training data and computational resources, transformers only cover a single category in self-attention out of the many categories available. We fill this gap and provide an in-depth survey of 50 attention techniques categorizing them by their most prominent features. We initiate our discussion by introducing the fundamental concepts behind the success of attention mechanism. Next, we furnish some essentials such as the strengths and limitations of each attention category, describe their fundamental building blocks, basic formulations with primary usage, and applications specifically for computer vision. We also discuss the challenges and open questions related to attention mechanism in general. Finally, we recommend possible future research directions for deep attention.
CrossFormer: Cross Spatio-Temporal Transformer for 3D Human Pose Estimation
Mar 24, 2022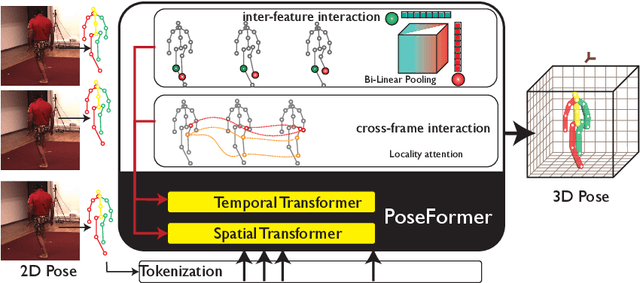
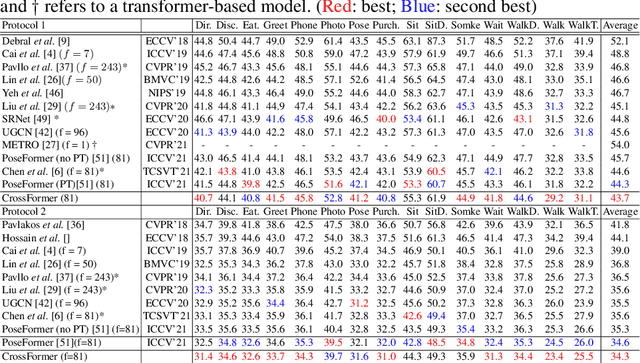
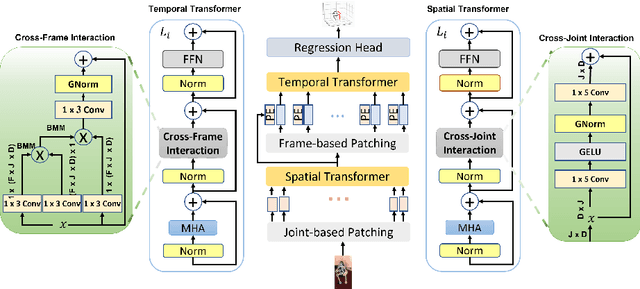
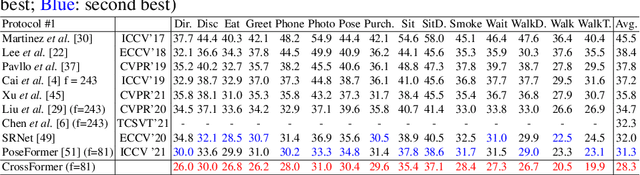
3D human pose estimation can be handled by encoding the geometric dependencies between the body parts and enforcing the kinematic constraints. Recently, Transformer has been adopted to encode the long-range dependencies between the joints in the spatial and temporal domains. While they had shown excellence in long-range dependencies, studies have noted the need for improving the locality of vision Transformers. In this direction, we propose a novel pose estimation Transformer featuring rich representations of body joints critical for capturing subtle changes across frames (i.e., inter-feature representation). Specifically, through two novel interaction modules; Cross-Joint Interaction and Cross-Frame Interaction, the model explicitly encodes the local and global dependencies between the body joints. The proposed architecture achieved state-of-the-art performance on two popular 3D human pose estimation datasets, Human3.6 and MPI-INF-3DHP. In particular, our proposed CrossFormer method boosts performance by 0.9% and 0.3%, compared to the closest counterpart, PoseFormer, using the detected 2D poses and ground-truth settings respectively.
Automated Parkinson's Disease Detection and Affective Analysis from Emotional EEG Signals
Feb 21, 2022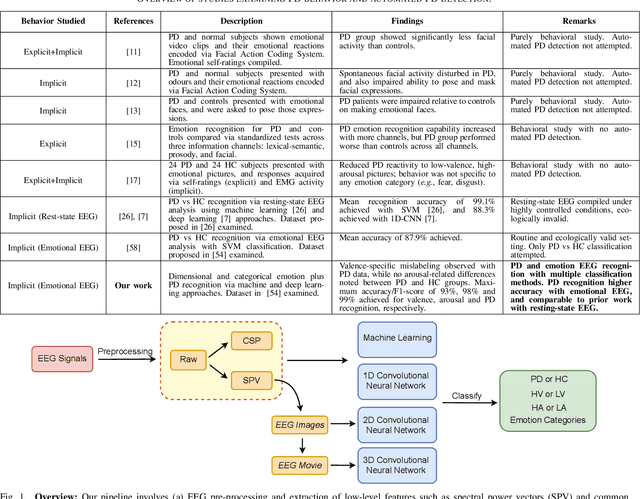
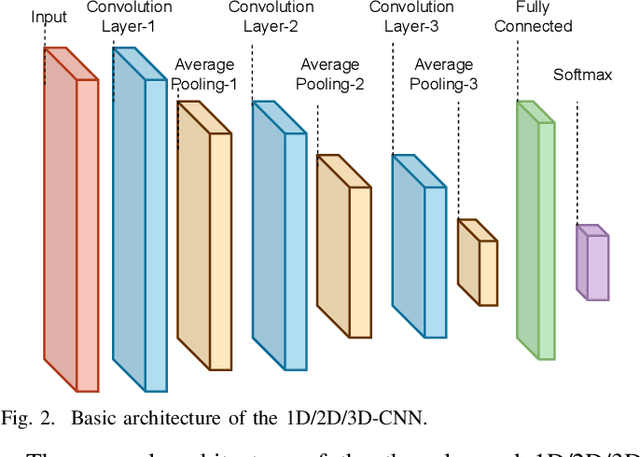
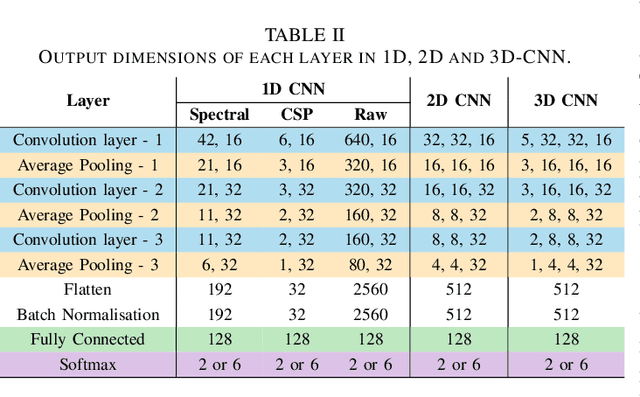
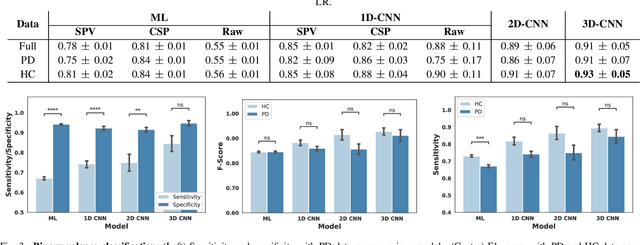
While Parkinson's disease (PD) is typically characterized by motor disorder, there is evidence of diminished emotion perception in PD patients. This study examines the utility of affective Electroencephalography (EEG) signals to understand emotional differences between PD vs Healthy Controls (HC), and for automated PD detection. Employing traditional machine learning and deep learning methods, we explore (a) dimensional and categorical emotion recognition, and (b) PD vs HC classification from emotional EEG signals. Our results reveal that PD patients comprehend arousal better than valence, and amongst emotion categories, \textit{fear}, \textit{disgust} and \textit{surprise} less accurately, and \textit{sadness} most accurately. Mislabeling analyses confirm confounds among opposite-valence emotions with PD data. Emotional EEG responses also achieve near-perfect PD vs HC recognition. {Cumulatively, our study demonstrates that (a) examining \textit{implicit} responses alone enables (i) discovery of valence-related impairments in PD patients, and (ii) differentiation of PD from HC, and (b) emotional EEG analysis is an ecologically-valid, effective, facile and sustainable tool for PD diagnosis vis-\'a-vis self reports, expert assessments and resting-state analysis.}
Learning Discriminative Representations for Multi-Label Image Recognition
Jul 23, 2021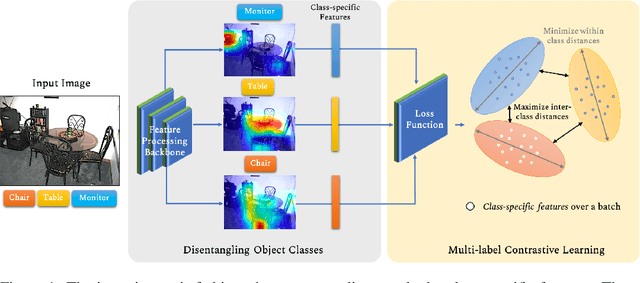
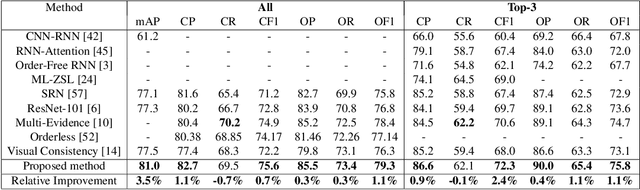
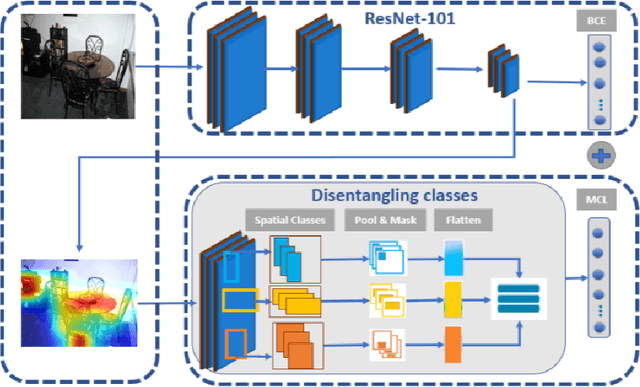
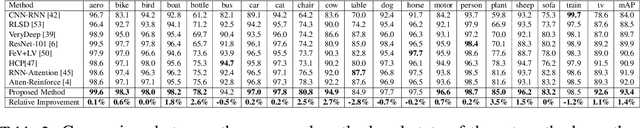
Multi-label recognition is a fundamental, and yet is a challenging task in computer vision. Recently, deep learning models have achieved great progress towards learning discriminative features from input images. However, conventional approaches are unable to model the inter-class discrepancies among features in multi-label images, since they are designed to work for image-level feature discrimination. In this paper, we propose a unified deep network to learn discriminative features for the multi-label task. Given a multi-label image, the proposed method first disentangles features corresponding to different classes. Then, it discriminates between these classes via increasing the inter-class distance while decreasing the intra-class differences in the output space. By regularizing the whole network with the proposed loss, the performance of applying the wellknown ResNet-101 is improved significantly. Extensive experiments have been performed on COCO-2014, VOC2007 and VOC2012 datasets, which demonstrate that the proposed method outperforms state-of-the-art approaches by a significant margin of 3:5% on large-scale COCO dataset. Moreover, analysis of the discriminative feature learning approach shows that it can be plugged into various types of multi-label methods as a general module.