 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Split Mamba: Effective State Space Modelling for Image Restoration
Mar 10, 2026Image restoration requires simultaneously preserving fine-grained local structures and maintaining long-range spatial coherence. While convolutional networks struggle with limited receptive fields, and Transformers incur quadratic complexity for global attention, recent State Space Models (SSMs), such as Mamba, provide an appealing linear-time alternative for long-range dependency modelling. However, naively extending Mamba to 2D images exposes two intrinsic shortcomings. First, flattening 2D feature maps into 1D sequences disrupts spatial topology, leading to locality distortion that hampers precise structural recovery. Second, the stability-driven recurrent dynamics of SSMs induce long-range decay, progressively attenuating information across distant spatial positions and weakening global consistency. Together, these effects limit the effectiveness of state-space modelling in high-fidelity restoration. We propose Progressive Split-Mamba (PS-Mamba), a topology-aware hierarchical state-space framework designed to reconcile locality preservation with efficient global propagation. Instead of sequentially flattening entire feature maps, PS-Mamba performs geometry-consistent partitioning, maintaining neighbourhood integrity prior to state-space processing. A progressive split hierarchy (halves, quadrants, octants) enables structured multi-scale modelling while retaining linear complexity. To counteract long-range decay, we introduce symmetric cross-scale shortcut pathways that directly transmit low-frequency global context across hierarchical levels, stabilising information flow over large spatial extents. Extensive experiments on super-resolution, denoising, and JPEG artifact reduction show consistent improvements over recent Mamba-based and attention-based models with a clear margin.
Towards Autonomous Riding: A Review of Perception, Planning, and Control in Intelligent Two-Wheelers
Jul 16, 2025The rapid adoption of micromobility solutions, particularly two-wheeled vehicles like e-scooters and e-bikes, has created an urgent need for reliable autonomous riding (AR) technologies. While autonomous driving (AD) systems have matured significantly, AR presents unique challenges due to the inherent instability of two-wheeled platforms, limited size, limited power, and unpredictable environments, which pose very serious concerns about road users' safety. This review provides a comprehensive analysis of AR systems by systematically examining their core components, perception, planning, and control, through the lens of AD technologies. We identify critical gaps in current AR research, including a lack of comprehensive perception systems for various AR tasks, limited industry and government support for such developments, and insufficient attention from the research community. The review analyses the gaps of AR from the perspective of AD to highlight promising research directions, such as multimodal sensor techniques for lightweight platforms and edge deep learning architectures. By synthesising insights from AD research with the specific requirements of AR, this review aims to accelerate the development of safe, efficient, and scalable autonomous riding systems for future urban mobility.
ICML 2023 Topological Deep Learning Challenge : Design and Results
Oct 02, 2023
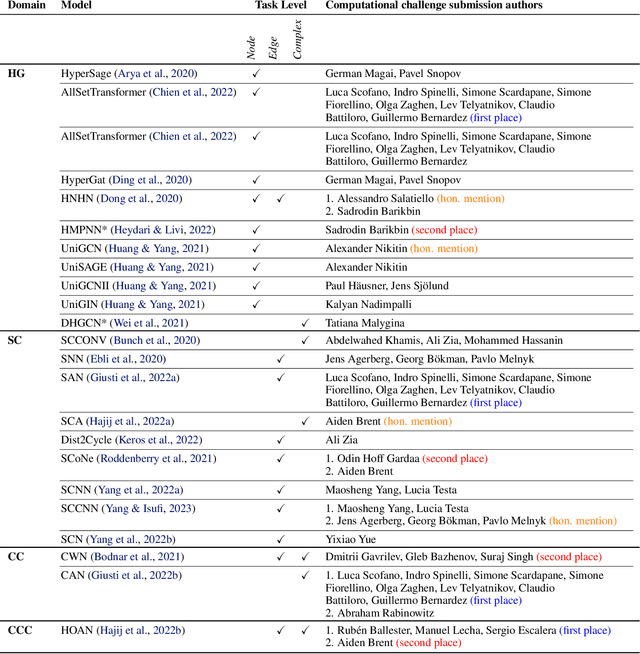
This paper presents the computational challenge on topological deep learning that was hosted within the ICML 2023 Workshop on Topology and Geometry in Machine Learning. The competition asked participants to provide open-source implementations of topological neural networks from the literature by contributing to the python packages TopoNetX (data processing) and TopoModelX (deep learning). The challenge attracted twenty-eight qualifying submissions in its two-month duration. This paper describes the design of the challenge and summarizes its main findings.
Visual Attention Methods in Deep Learning: An In-Depth Survey
Apr 21, 2022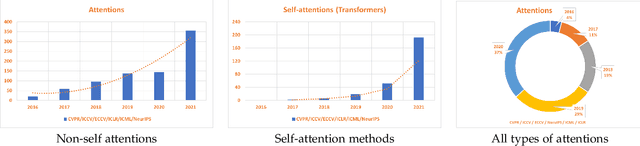
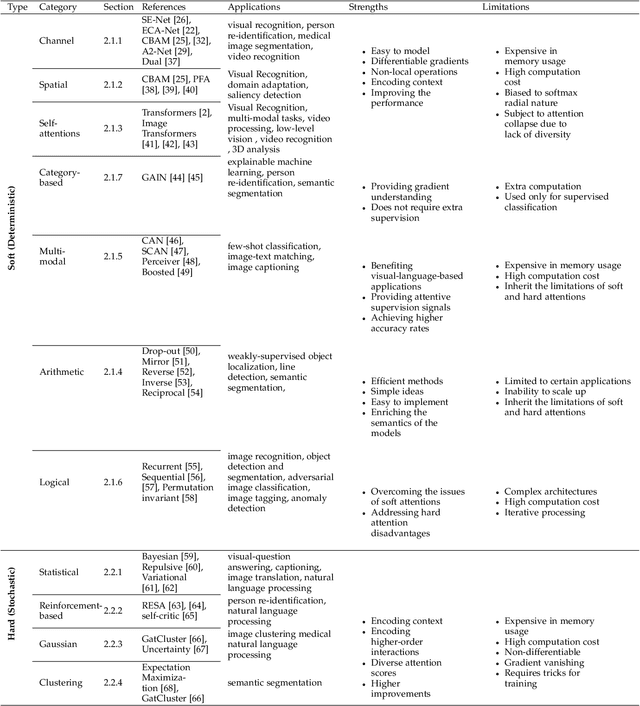
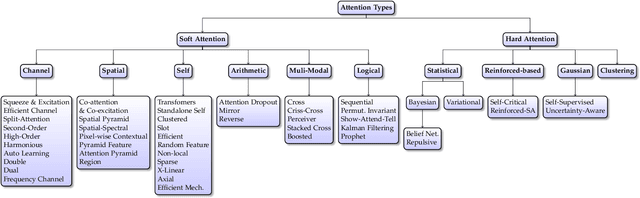
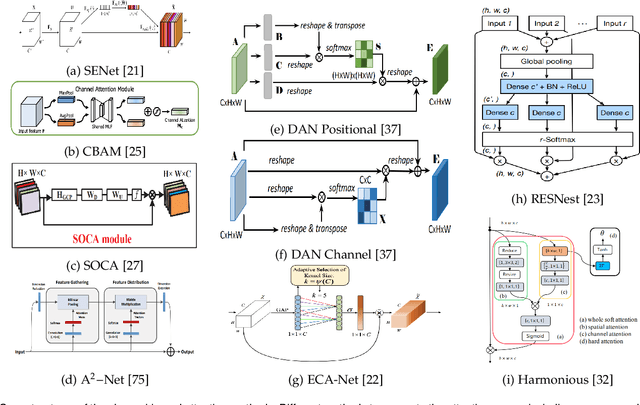
Inspired by the human cognitive system, attention is a mechanism that imitates the human cognitive awareness about specific information, amplifying critical details to focus more on the essential aspects of data. Deep learning has employed attention to boost performance for many applications. Interestingly, the same attention design can suit processing different data modalities and can easily be incorporated into large networks. Furthermore, multiple complementary attention mechanisms can be incorporated in one network. Hence, attention techniques have become extremely attractive. However, the literature lacks a comprehensive survey specific to attention techniques to guide researchers in employing attention in their deep models. Note that, besides being demanding in terms of training data and computational resources, transformers only cover a single category in self-attention out of the many categories available. We fill this gap and provide an in-depth survey of 50 attention techniques categorizing them by their most prominent features. We initiate our discussion by introducing the fundamental concepts behind the success of attention mechanism. Next, we furnish some essentials such as the strengths and limitations of each attention category, describe their fundamental building blocks, basic formulations with primary usage, and applications specifically for computer vision. We also discuss the challenges and open questions related to attention mechanism in general. Finally, we recommend possible future research directions for deep attention.
CrossFormer: Cross Spatio-Temporal Transformer for 3D Human Pose Estimation
Mar 24, 2022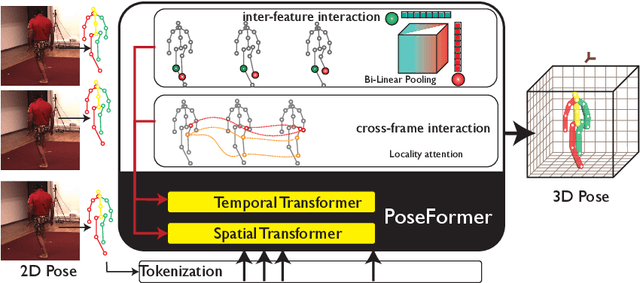
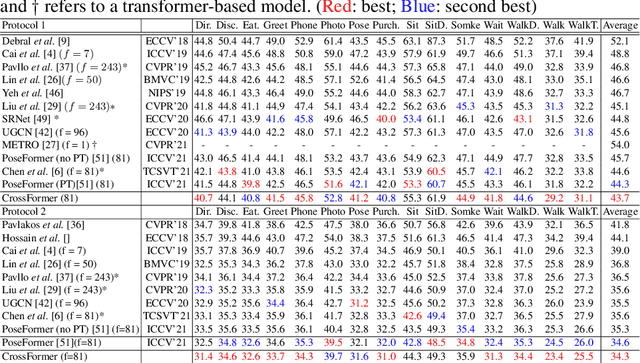
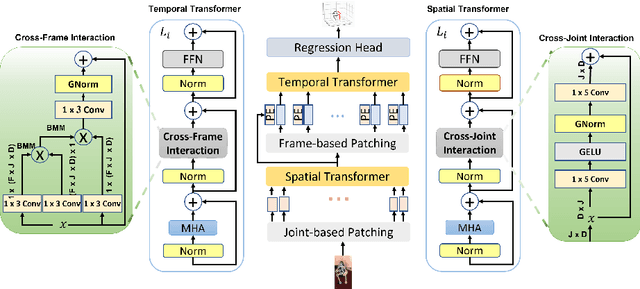
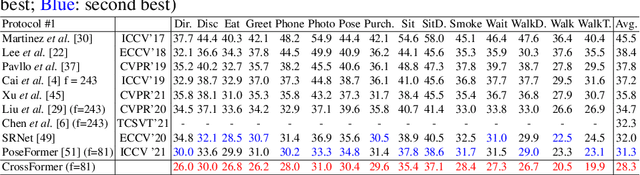
3D human pose estimation can be handled by encoding the geometric dependencies between the body parts and enforcing the kinematic constraints. Recently, Transformer has been adopted to encode the long-range dependencies between the joints in the spatial and temporal domains. While they had shown excellence in long-range dependencies, studies have noted the need for improving the locality of vision Transformers. In this direction, we propose a novel pose estimation Transformer featuring rich representations of body joints critical for capturing subtle changes across frames (i.e., inter-feature representation). Specifically, through two novel interaction modules; Cross-Joint Interaction and Cross-Frame Interaction, the model explicitly encodes the local and global dependencies between the body joints. The proposed architecture achieved state-of-the-art performance on two popular 3D human pose estimation datasets, Human3.6 and MPI-INF-3DHP. In particular, our proposed CrossFormer method boosts performance by 0.9% and 0.3%, compared to the closest counterpart, PoseFormer, using the detected 2D poses and ground-truth settings respectively.
Learning Discriminative Representations for Multi-Label Image Recognition
Jul 23, 2021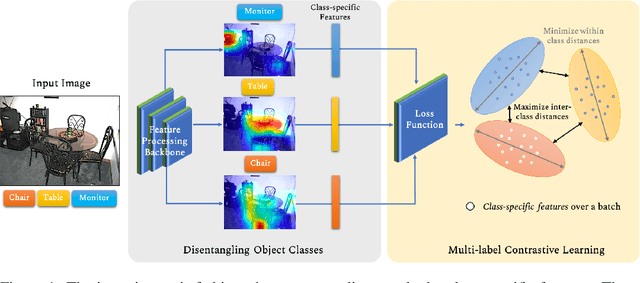
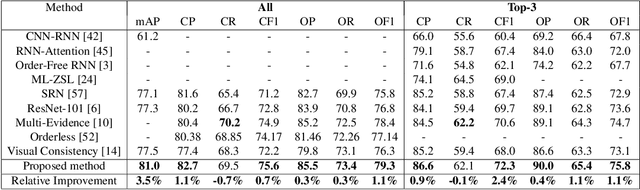
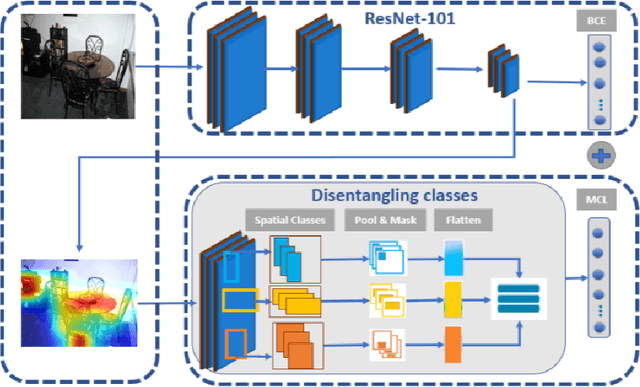
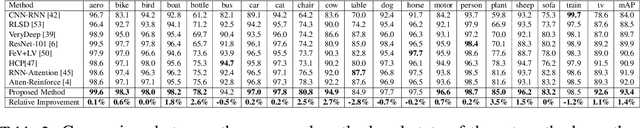
Multi-label recognition is a fundamental, and yet is a challenging task in computer vision. Recently, deep learning models have achieved great progress towards learning discriminative features from input images. However, conventional approaches are unable to model the inter-class discrepancies among features in multi-label images, since they are designed to work for image-level feature discrimination. In this paper, we propose a unified deep network to learn discriminative features for the multi-label task. Given a multi-label image, the proposed method first disentangles features corresponding to different classes. Then, it discriminates between these classes via increasing the inter-class distance while decreasing the intra-class differences in the output space. By regularizing the whole network with the proposed loss, the performance of applying the wellknown ResNet-101 is improved significantly. Extensive experiments have been performed on COCO-2014, VOC2007 and VOC2012 datasets, which demonstrate that the proposed method outperforms state-of-the-art approaches by a significant margin of 3:5% on large-scale COCO dataset. Moreover, analysis of the discriminative feature learning approach shows that it can be plugged into various types of multi-label methods as a general module.
Mitigating the Impact of Adversarial Attacks in Very Deep Networks
Dec 08, 2020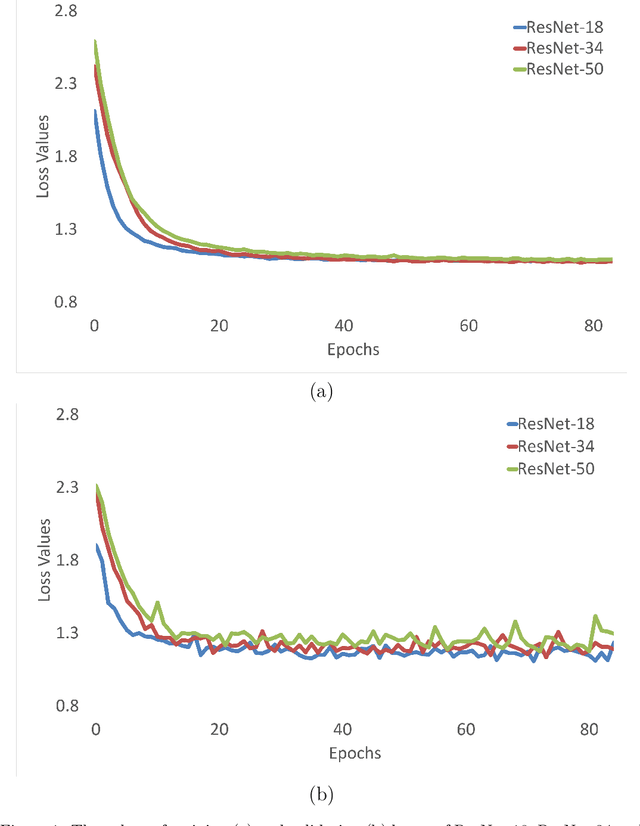
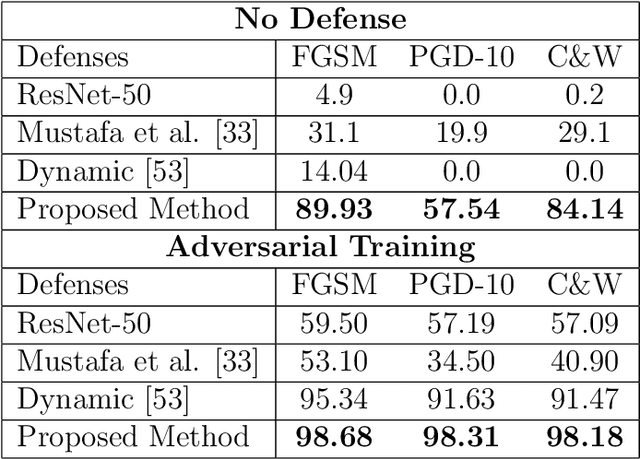
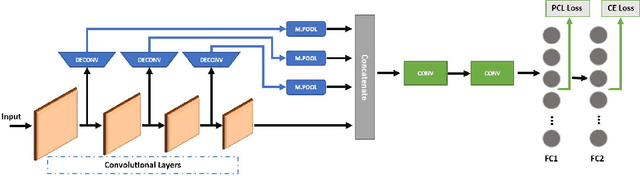
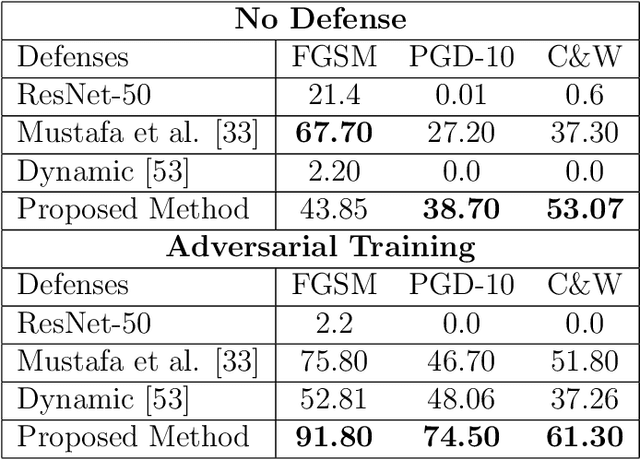
Deep Neural Network (DNN) models have vulnerabilities related to security concerns, with attackers usually employing complex hacking techniques to expose their structures. Data poisoning-enabled perturbation attacks are complex adversarial ones that inject false data into models. They negatively impact the learning process, with no benefit to deeper networks, as they degrade a model's accuracy and convergence rates. In this paper, we propose an attack-agnostic-based defense method for mitigating their influence. In it, a Defensive Feature Layer (DFL) is integrated with a well-known DNN architecture which assists in neutralizing the effects of illegitimate perturbation samples in the feature space. To boost the robustness and trustworthiness of this method for correctly classifying attacked input samples, we regularize the hidden space of a trained model with a discriminative loss function called Polarized Contrastive Loss (PCL). It improves discrimination among samples in different classes and maintains the resemblance of those in the same class. Also, we integrate a DFL and PCL in a compact model for defending against data poisoning attacks. This method is trained and tested using the CIFAR-10 and MNIST datasets with data poisoning-enabled perturbation attacks, with the experimental results revealing its excellent performance compared with those of recent peer techniques.
A Deep Marginal-Contrastive Defense against Adversarial Attacks on 1D Models
Dec 08, 2020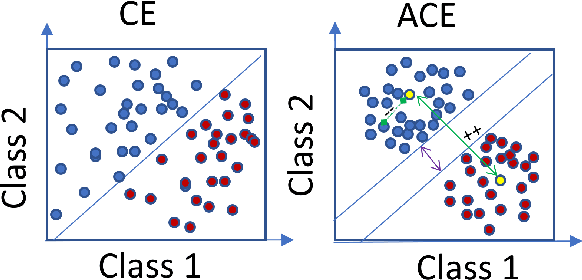
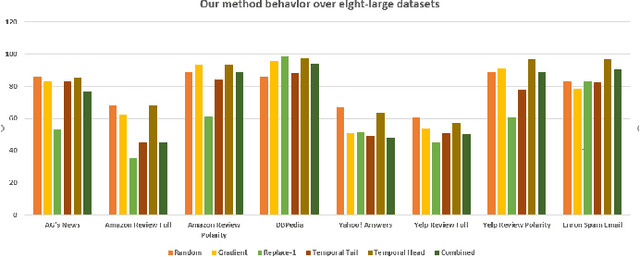
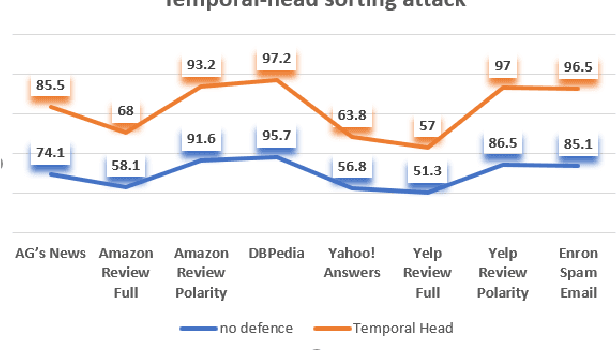
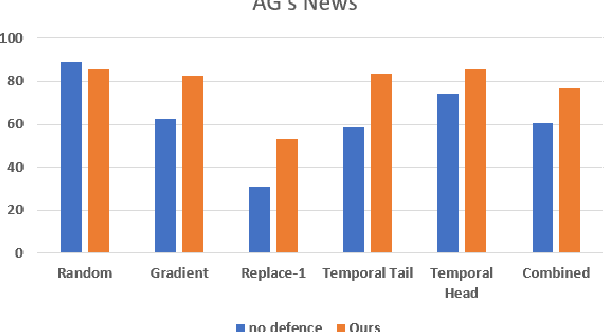
Deep learning algorithms have been recently targeted by attackers due to their vulnerability. Several research studies have been conducted to address this issue and build more robust deep learning models. Non-continuous deep models are still not robust against adversarial, where most of the recent studies have focused on developing attack techniques to evade the learning process of the models. One of the main reasons behind the vulnerability of such models is that a learning classifier is unable to slightly predict perturbed samples. To address this issue, we propose a novel objective/loss function, the so-called marginal contrastive, which enforces the features to lie under a specified margin to facilitate their prediction using deep convolutional networks (i.e., Char-CNN). Extensive experiments have been conducted on continuous cases (e.g., UNSW NB15 dataset) and discrete ones (i.e, eight-large-scale datasets [32]) to prove the effectiveness of the proposed method. The results revealed that the regularization of the learning process based on the proposed loss function can improve the performance of Char-CNN.
Visual Affordance and Function Understanding: A Survey
Jul 18, 2018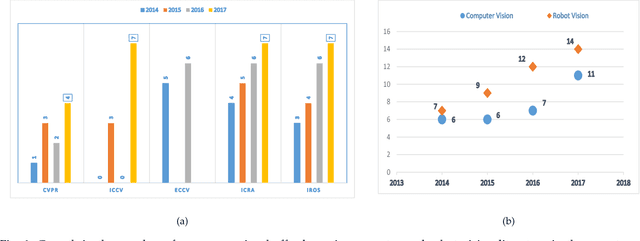

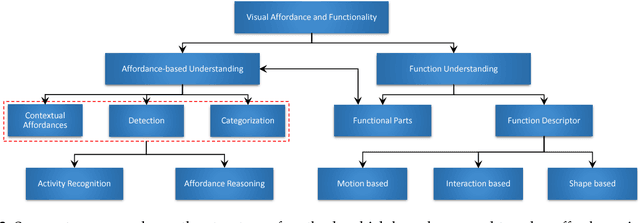

Nowadays, robots are dominating the manufacturing, entertainment and healthcare industries. Robot vision aims to equip robots with the ability to discover information, understand it and interact with the environment. These capabilities require an agent to effectively understand object affordances and functionalities in complex visual domains. In this literature survey, we first focus on Visual affordances and summarize the state of the art as well as open problems and research gaps. Specifically, we discuss sub-problems such as affordance detection, categorization, segmentation and high-level reasoning. Furthermore, we cover functional scene understanding and the prevalent functional descriptors used in the literature. The survey also provides necessary background to the problem, sheds light on its significance and highlights the existing challenges for affordance and functionality learning.