 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Discriminative Representations for Multi-Label Image Recognition
Jul 23, 2021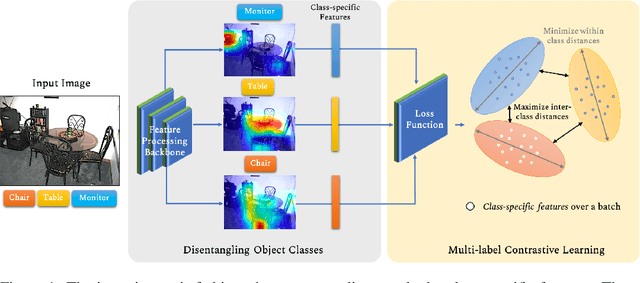
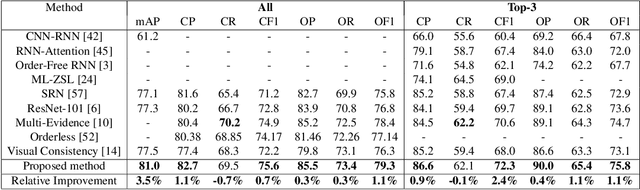
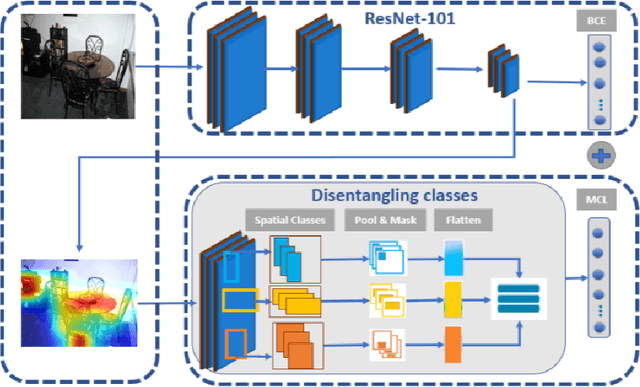
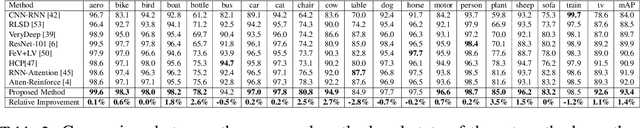
Multi-label recognition is a fundamental, and yet is a challenging task in computer vision. Recently, deep learning models have achieved great progress towards learning discriminative features from input images. However, conventional approaches are unable to model the inter-class discrepancies among features in multi-label images, since they are designed to work for image-level feature discrimination. In this paper, we propose a unified deep network to learn discriminative features for the multi-label task. Given a multi-label image, the proposed method first disentangles features corresponding to different classes. Then, it discriminates between these classes via increasing the inter-class distance while decreasing the intra-class differences in the output space. By regularizing the whole network with the proposed loss, the performance of applying the wellknown ResNet-101 is improved significantly. Extensive experiments have been performed on COCO-2014, VOC2007 and VOC2012 datasets, which demonstrate that the proposed method outperforms state-of-the-art approaches by a significant margin of 3:5% on large-scale COCO dataset. Moreover, analysis of the discriminative feature learning approach shows that it can be plugged into various types of multi-label methods as a general module.
Mitigating the Impact of Adversarial Attacks in Very Deep Networks
Dec 08, 2020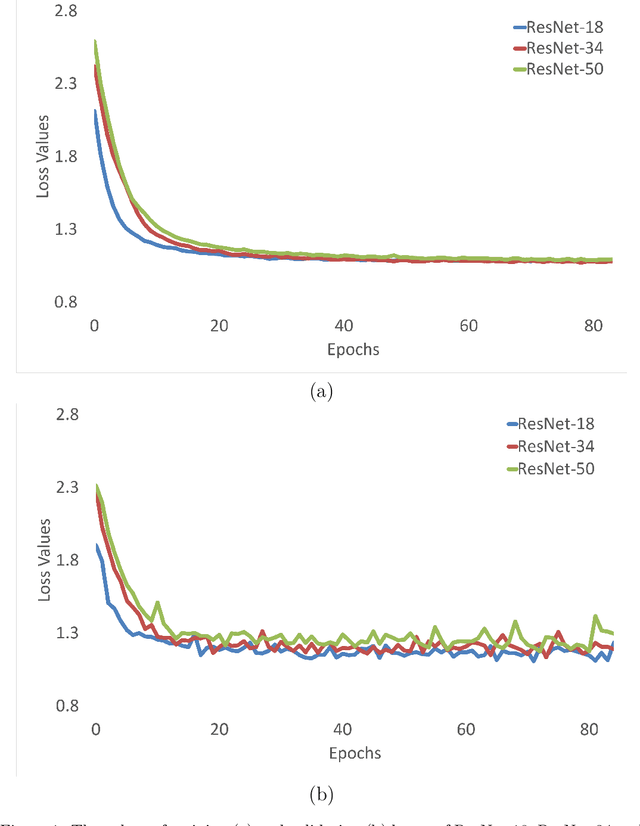
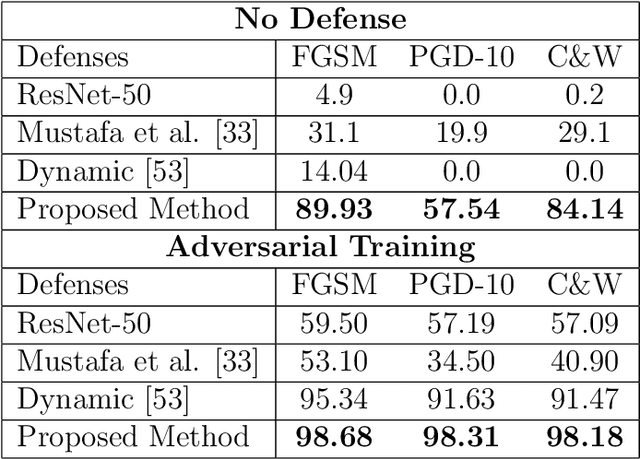
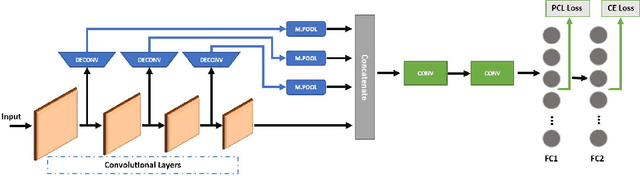
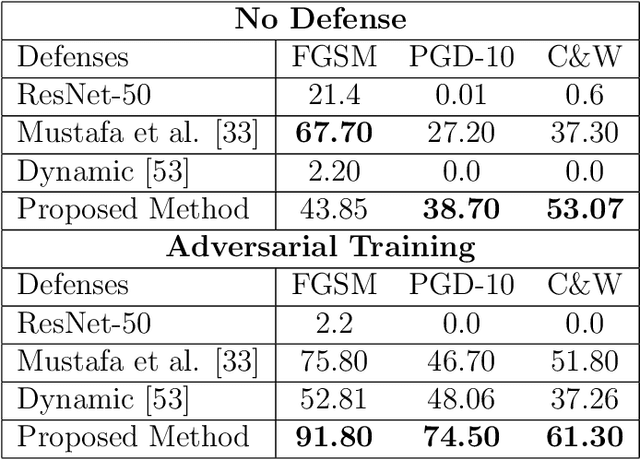
Deep Neural Network (DNN) models have vulnerabilities related to security concerns, with attackers usually employing complex hacking techniques to expose their structures. Data poisoning-enabled perturbation attacks are complex adversarial ones that inject false data into models. They negatively impact the learning process, with no benefit to deeper networks, as they degrade a model's accuracy and convergence rates. In this paper, we propose an attack-agnostic-based defense method for mitigating their influence. In it, a Defensive Feature Layer (DFL) is integrated with a well-known DNN architecture which assists in neutralizing the effects of illegitimate perturbation samples in the feature space. To boost the robustness and trustworthiness of this method for correctly classifying attacked input samples, we regularize the hidden space of a trained model with a discriminative loss function called Polarized Contrastive Loss (PCL). It improves discrimination among samples in different classes and maintains the resemblance of those in the same class. Also, we integrate a DFL and PCL in a compact model for defending against data poisoning attacks. This method is trained and tested using the CIFAR-10 and MNIST datasets with data poisoning-enabled perturbation attacks, with the experimental results revealing its excellent performance compared with those of recent peer techniques.
A Deep Marginal-Contrastive Defense against Adversarial Attacks on 1D Models
Dec 08, 2020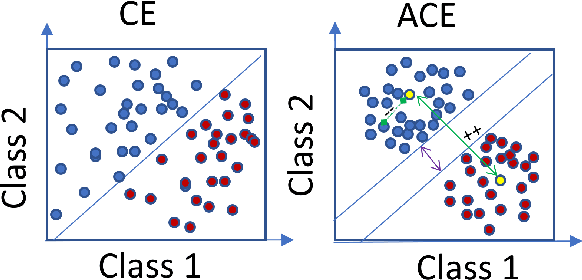
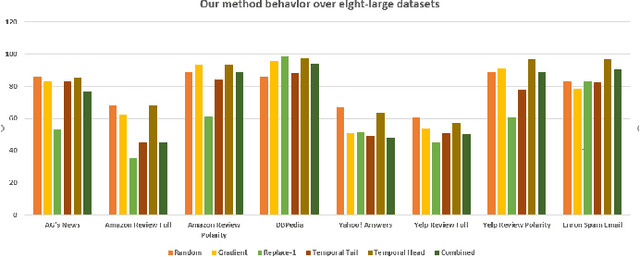
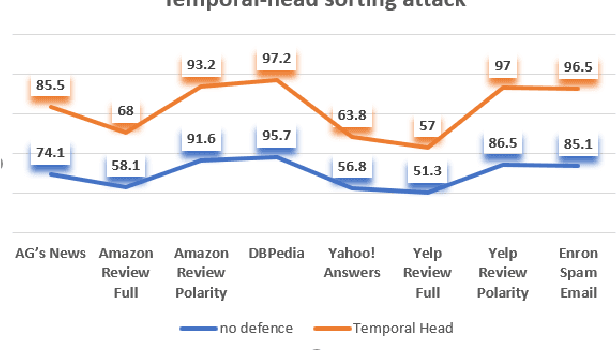
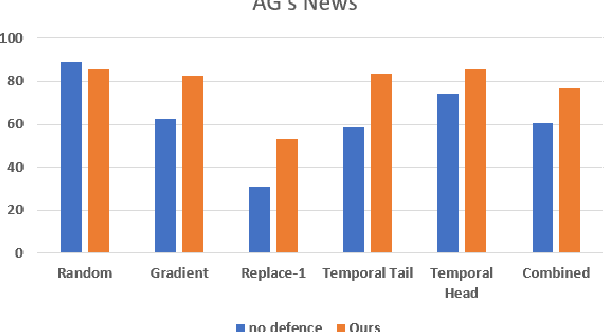
Deep learning algorithms have been recently targeted by attackers due to their vulnerability. Several research studies have been conducted to address this issue and build more robust deep learning models. Non-continuous deep models are still not robust against adversarial, where most of the recent studies have focused on developing attack techniques to evade the learning process of the models. One of the main reasons behind the vulnerability of such models is that a learning classifier is unable to slightly predict perturbed samples. To address this issue, we propose a novel objective/loss function, the so-called marginal contrastive, which enforces the features to lie under a specified margin to facilitate their prediction using deep convolutional networks (i.e., Char-CNN). Extensive experiments have been conducted on continuous cases (e.g., UNSW NB15 dataset) and discrete ones (i.e, eight-large-scale datasets [32]) to prove the effectiveness of the proposed method. The results revealed that the regularization of the learning process based on the proposed loss function can improve the performance of Char-CNN.
Visual Affordance and Function Understanding: A Survey
Jul 18, 2018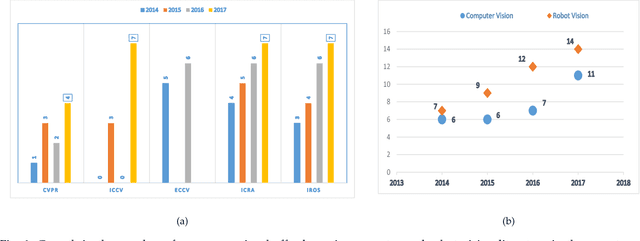

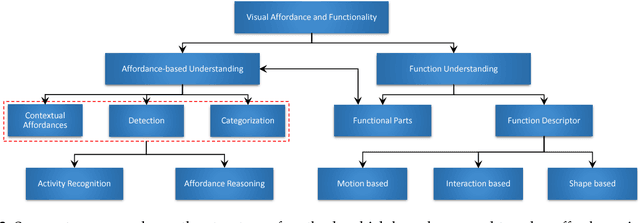

Nowadays, robots are dominating the manufacturing, entertainment and healthcare industries. Robot vision aims to equip robots with the ability to discover information, understand it and interact with the environment. These capabilities require an agent to effectively understand object affordances and functionalities in complex visual domains. In this literature survey, we first focus on Visual affordances and summarize the state of the art as well as open problems and research gaps. Specifically, we discuss sub-problems such as affordance detection, categorization, segmentation and high-level reasoning. Furthermore, we cover functional scene understanding and the prevalent functional descriptors used in the literature. The survey also provides necessary background to the problem, sheds light on its significance and highlights the existing challenges for affordance and functionality learning.