 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossFormer: Cross Spatio-Temporal Transformer for 3D Human Pose Estimation
Paper and Code
Mar 24, 2022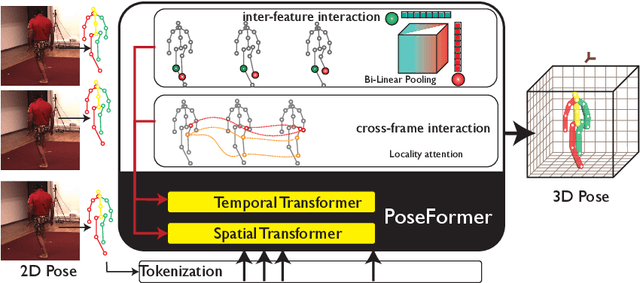
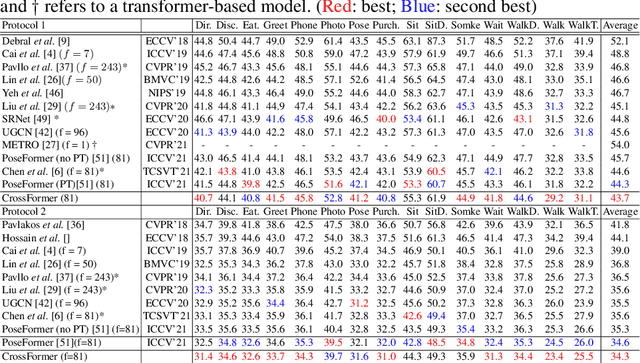
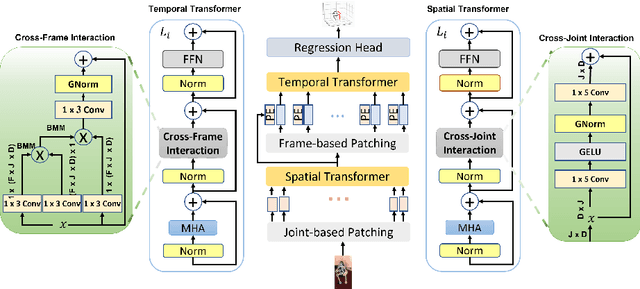
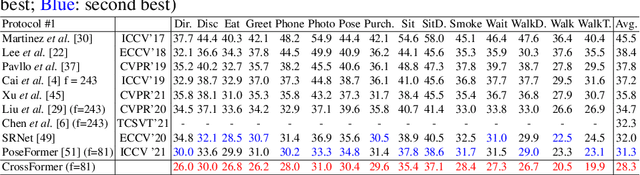
3D human pose estimation can be handled by encoding the geometric dependencies between the body parts and enforcing the kinematic constraints. Recently, Transformer has been adopted to encode the long-range dependencies between the joints in the spatial and temporal domains. While they had shown excellence in long-range dependencies, studies have noted the need for improving the locality of vision Transformers. In this direction, we propose a novel pose estimation Transformer featuring rich representations of body joints critical for capturing subtle changes across frames (i.e., inter-feature representation). Specifically, through two novel interaction modules; Cross-Joint Interaction and Cross-Frame Interaction, the model explicitly encodes the local and global dependencies between the body joints. The proposed architecture achieved state-of-the-art performance on two popular 3D human pose estimation datasets, Human3.6 and MPI-INF-3DHP. In particular, our proposed CrossFormer method boosts performance by 0.9% and 0.3%, compared to the closest counterpart, PoseFormer, using the detected 2D poses and ground-truth settings respectively.