 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiking Personalized Federated Learning for Brain-Computer Interface-Enabled Immersive Communication
Mar 24, 2026This work proposes a novel immersive communication framework that leverages brain-computer interface (BCI) to acquire brain signals for inferring user-centric states (e.g., intention and perception-related discomfort), thereby enabling more personalized and robust immersive adaptation under strong individual variability. Specifically, we develop a personalized federated learning (PFL) model to analyze and process the collected brain signals, which not only accommodates neurodiverse brain-signal data but also prevents the leakage of sensitive brain-signal information. To address the energy bottleneck of continual on-device learning and inference on energy-limited immersive terminals (e.g., head-mounted display), we further embed spiking neural networks (SNNs) into the PFL. By exploiting sparse, event-driven spike computation, the SNN-enabled PFL reduces the computation and energy cost of training and inference while maintaining competitive personalization performance. Experiments on real brain-signal dataset demonstrate that our method achieves the best overall identification accuracy while reducing inference energy by 6.46$\times$ compared with conventional artificial neural network-based personalized baselines.
Deep Learning-Driven Friendly Jamming for Secure Multicarrier ISAC Under Channel Uncertainty
Mar 05, 2026Integrated sensing and communication (ISAC) systems promise efficient spectrum utilization by jointly supporting radar sensing and wireless communication. This paper presents a deep learning-driven framework for enhancing physical-layer security in multicarrier ISAC systems under imperfect channel state information (CSI) and in the presence of unknown eavesdropper (Eve) locations. Unlike conventional ISAC-based friendly jamming (FJ) approaches that require Eve's CSI or precise angle-of-arrival (AoA) estimates, our method exploits radar echo feedback to guide directional jamming without explicit Eve's information. To enhance robustness to radar sensing uncertainty, we propose a radar-aware neural network that jointly optimizes beamforming and jamming by integrating a novel nonparametric Fisher Information Matrix (FIM) estimator based on f-divergence. The jamming design satisfies the Cramer-Rao lower bound (CRLB) constraints even in the presence of noisy AoA. For efficient implementation, we introduce a quantized tensor train-based encoder that reduces the model size by more than 100 times with negligible performance loss. We also integrate a non-overlapping secure scheme into the proposed framework, in which specific sub-bands can be dedicated solely to communication. Extensive simulations demonstrate that the proposed solution achieves significant improvements in secrecy rate, reduced block error rate (BLER), and strong robustness against CSI uncertainty and angular estimation errors, underscoring the effectiveness of the proposed deep learning-driven friendly jamming framework under practical ISAC impairments.
Secure Communications for All Users in Low-Resolution IRS-aided Systems Under Imperfect and Unknown CSI
Apr 07, 2025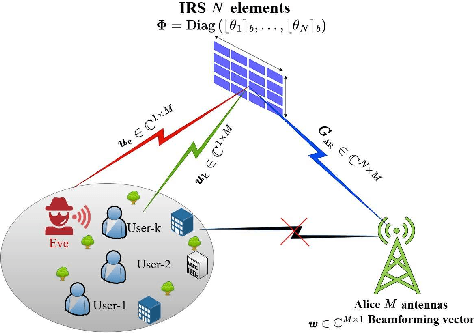
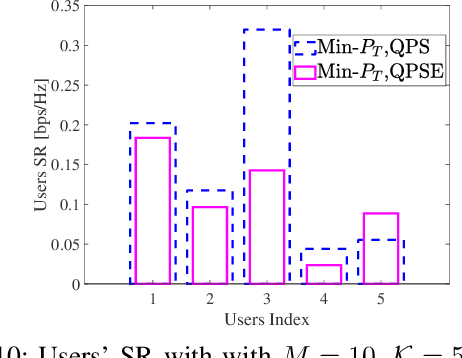
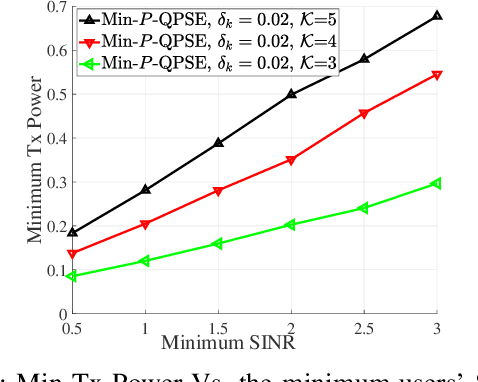
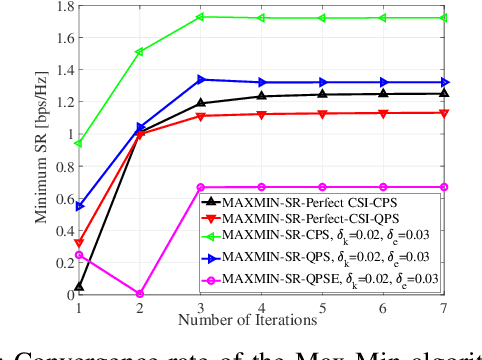
Provisioning secrecy for all users, given the heterogeneity and uncertainty of their channel conditions, locations, and the unknown location of the attacker/eavesdropper, is challenging and not always feasible. This work takes the first step to guarantee secrecy for all users where a low resolution intelligent reflecting surfaces (IRS) is used to enhance legitimate users' reception and thwart the potential eavesdropper (Eve) from intercepting. In real-life scenarios, due to hardware limitations of the IRS' passive reflective elements (PREs), the use of a full-resolution (continuous) phase shift (CPS) is impractical. In this paper, we thus consider a more practical case where the phase shift (PS) is modeled by a low-resolution (quantized) phase shift (QPS) while addressing the phase shift error (PSE) induced by the imperfect channel state information (CSI). To that end, we aim to maximize the minimum secrecy rate (SR) among all users by jointly optimizing the transmitter's beamforming vector and the IRS's passive reflective elements (PREs) under perfect/imperfect/unknown CSI. The resulting optimization problem is non-convex and even more complicated under imperfect/unknown CSI.
"Security for Everyone" in Finite Blocklength IRS-aided Systems With Perfect and Imperfect CSI
Apr 07, 2025Provisioning secrecy for all users, given the heterogeneity in their channel conditions, locations, and the unknown location of the attacker/eavesdropper, is challenging and not always feasible. The problem is even more difficult under finite blocklength constraints that are popular in ultra-reliable low-latency communication (URLLC) and massive machine-type communications (mMTC). This work takes the first step to guarantee secrecy for all URLLC/mMTC users in the finite blocklength regime (FBR) where intelligent reflecting surfaces (IRS) are used to enhance legitimate users' reception and thwart the potential eavesdropper (Eve) from intercepting. To that end, we aim to maximize the minimum secrecy rate (SR) among all users by jointly optimizing the transmitter's beamforming and IRS's passive reflective elements (PREs) under the FBR latency constraints. The resulting optimization problem is non-convex and even more complicated under imperfect channel state information (CSI). To tackle it, we linearize the objective function, and decompose the problem into sequential subproblems. When perfect CSI is not available, we use the successive convex approximation (SCA) approach to transform imperfect CSI-related semi-infinite constraints into finite linear matrix inequalities (LMI).
Right Reward Right Time for Federated Learning
Mar 10, 2025Critical learning periods (CLPs) in federated learning (FL) refer to early stages during which low-quality contributions (e.g., sparse training data availability) can permanently impair the learning performance of the global model owned by the model owner (i.e., the cloud server). However, strategies to motivate clients with high-quality contributions to join the FL training process and share trained model updates during CLPs remain underexplored. Additionally, existing incentive mechanisms in FL treat all training periods equally, which consequently fails to motivate clients to participate early. Compounding this challenge is the cloud's limited knowledge of client training capabilities due to privacy regulations, leading to information asymmetry. Therefore, in this article, we propose a time-aware incentive mechanism, called Right Reward Right Time (R3T), to encourage client involvement, especially during CLPs, to maximize the utility of the cloud in FL. Specifically, the cloud utility function captures the trade-off between the achieved model performance and payments allocated for clients' contributions, while accounting for clients' time and system capabilities, efforts, joining time, and rewards. Then, we analytically derive the optimal contract for the cloud and devise a CLP-aware mechanism to incentivize early participation and efforts while maximizing cloud utility, even under information asymmetry. By providing the right reward at the right time, our approach can attract the highest-quality contributions during CLPs. Simulation and proof-of-concept studies show that R3T increases cloud utility and is more economically effective than benchmarks. Notably, our proof-of-concept results show up to a 47.6% reduction in the total number of clients and up to a 300% improvement in convergence time while reaching competitive test accuracies compared with incentive mechanism benchmarks.
End-to-End Human Pose Reconstruction from Wearable Sensors for 6G Extended Reality Systems
Mar 06, 2025Full 3D human pose reconstruction is a critical enabler for extended reality (XR) applications in future sixth generation (6G) networks, supporting immersive interactions in gaming, virtual meetings, and remote collaboration. However, achieving accurate pose reconstruction over wireless networks remains challenging due to channel impairments, bit errors, and quantization effects. Existing approaches often assume error-free transmission in indoor settings, limiting their applicability to real-world scenarios. To address these challenges, we propose a novel deep learning-based framework for human pose reconstruction over orthogonal frequency-division multiplexing (OFDM) systems. The framework introduces a two-stage deep learning receiver: the first stage jointly estimates the wireless channel and decodes OFDM symbols, and the second stage maps the received sensor signals to full 3D body poses. Simulation results demonstrate that the proposed neural receiver reduces bit error rate (BER), thus gaining a 5 dB gap at $10^{-4}$ BER, compared to the baseline method that employs separate signal detection steps, i.e., least squares channel estimation and linear minimum mean square error equalization. Additionally, our empirical findings show that 8-bit quantization is sufficient for accurate pose reconstruction, achieving a mean squared error of $5\times10^{-4}$ for reconstructed sensor signals, and reducing joint angular error by 37\% for the reconstructed human poses compared to the baseline.
Multiple-Input Variational Auto-Encoder for Anomaly Detection in Heterogeneous Data
Jan 14, 2025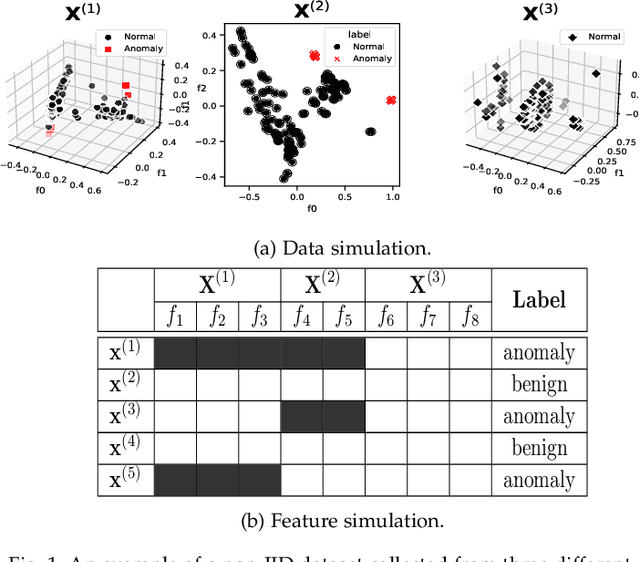

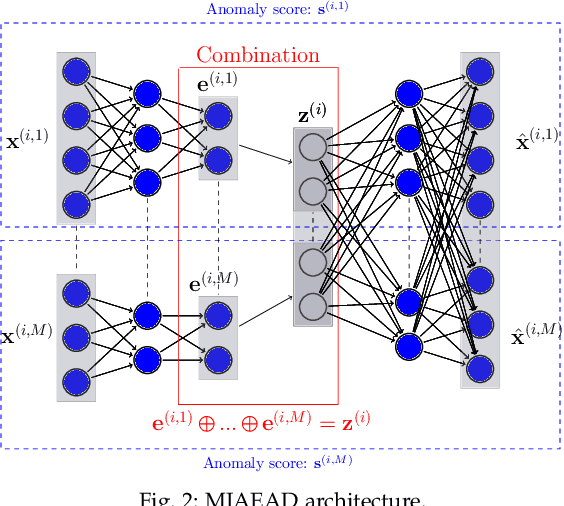
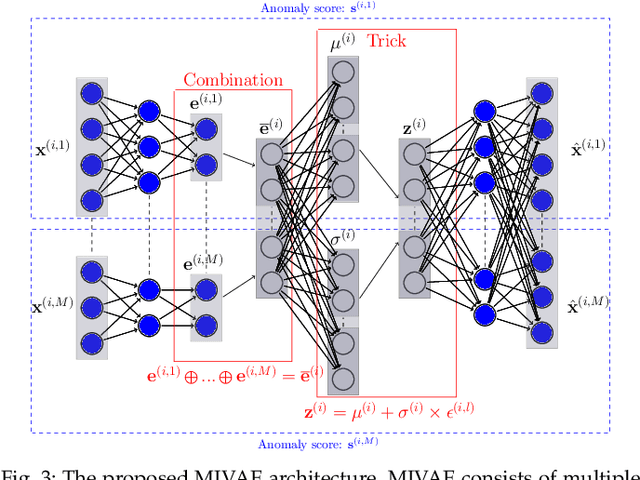
Anomaly detection (AD) plays a pivotal role in AI applications, e.g., in classification, and intrusion/threat detection in cybersecurity. However, most existing methods face challenges of heterogeneity amongst feature subsets posed by non-independent and identically distributed (non-IID) data. We propose a novel neural network model called Multiple-Input Auto-Encoder for AD (MIAEAD) to address this. MIAEAD assigns an anomaly score to each feature subset of a data sample to indicate its likelihood of being an anomaly. This is done by using the reconstruction error of its sub-encoder as the anomaly score. All sub-encoders are then simultaneously trained using unsupervised learning to determine the anomaly scores of feature subsets. The final AUC of MIAEAD is calculated for each sub-dataset, and the maximum AUC obtained among the sub-datasets is selected. To leverage the modelling of the distribution of normal data to identify anomalies of the generative models, we develop a novel neural network architecture/model called Multiple-Input Variational Auto-Encoder (MIVAE). MIVAE can process feature subsets through its sub-encoders before learning distribution of normal data in the latent space. This allows MIVAE to identify anomalies that deviate from the learned distribution. We theoretically prove that the difference in the average anomaly score between normal samples and anomalies obtained by the proposed MIVAE is greater than that of the Variational Auto-Encoder (VAEAD), resulting in a higher AUC for MIVAE. Extensive experiments on eight real-world anomaly datasets demonstrate the superior performance of MIAEAD and MIVAE over conventional methods and the state-of-the-art unsupervised models, by up to 6% in terms of AUC score. Alternatively, MIAEAD and MIVAE have a high AUC when applied to feature subsets with low heterogeneity based on the coefficient of variation (CV) score.
Dynamic Spectrum Access for Ambient Backscatter Communication-assisted D2D Systems with Quantum Reinforcement Learning
Oct 23, 2024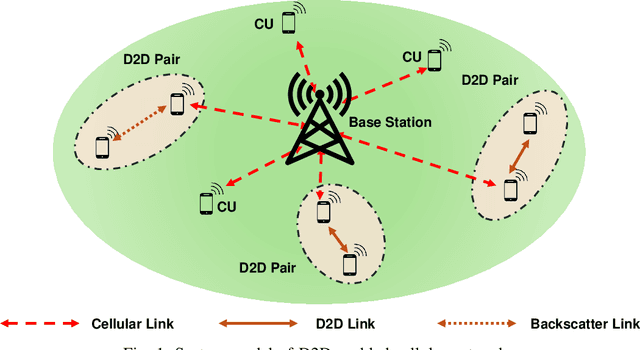
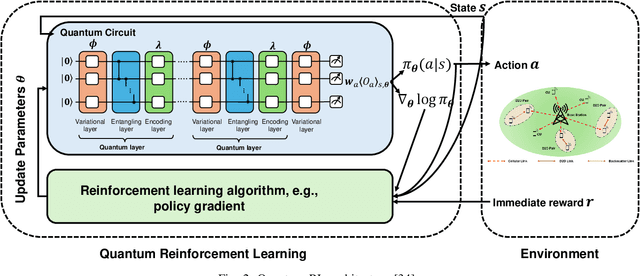
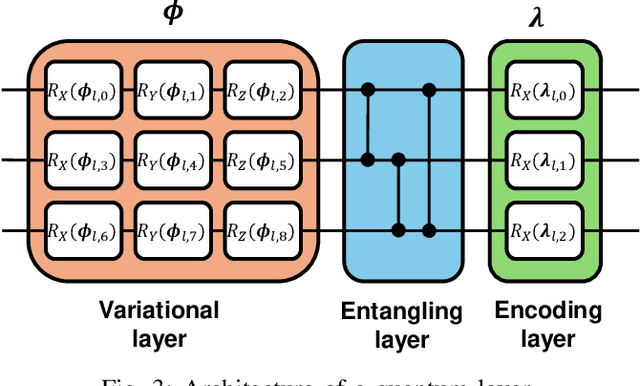
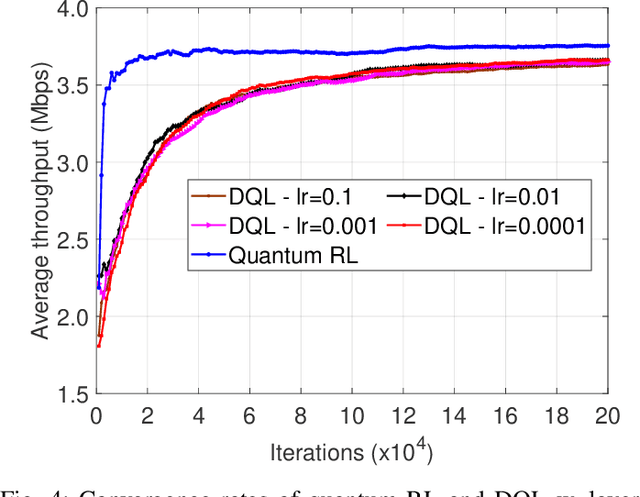
Spectrum access is an essential problem in device-to-device (D2D) communications. However, with the recent growth in the number of mobile devices, the wireless spectrum is becoming scarce, resulting in low spectral efficiency for D2D communications. To address this problem, this paper aims to integrate the ambient backscatter communication technology into D2D devices to allow them to backscatter ambient RF signals to transmit their data when the shared spectrum is occupied by mobile users. To obtain the optimal spectrum access policy, i.e., stay idle or access the shared spectrum and perform active transmissions or backscattering ambient RF signals for transmissions, to maximize the average throughput for D2D users, deep reinforcement learning (DRL) can be adopted. However, DRL-based solutions may require long training time due to the curse of dimensionality issue as well as complex deep neural network architectures. For that, we develop a novel quantum reinforcement learning (RL) algorithm that can achieve a faster convergence rate with fewer training parameters compared to DRL thanks to the quantum superposition and quantum entanglement principles. Specifically, instead of using conventional deep neural networks, the proposed quantum RL algorithm uses a parametrized quantum circuit to approximate an optimal policy. Extensive simulations then demonstrate that the proposed solution not only can significantly improve the average throughput of D2D devices when the shared spectrum is busy but also can achieve much better performance in terms of convergence rate and learning complexity compared to existing DRL-based methods.
Multiple-Input Auto-Encoder Guided Feature Selection for IoT Intrusion Detection Systems
Mar 22, 2024While intrusion detection systems (IDSs) benefit from the diversity and generalization of IoT data features, the data diversity (e.g., the heterogeneity and high dimensions of data) also makes it difficult to train effective machine learning models in IoT IDSs. This also leads to potentially redundant/noisy features that may decrease the accuracy of the detection engine in IDSs. This paper first introduces a novel neural network architecture called Multiple-Input Auto-Encoder (MIAE). MIAE consists of multiple sub-encoders that can process inputs from different sources with different characteristics. The MIAE model is trained in an unsupervised learning mode to transform the heterogeneous inputs into lower-dimensional representation, which helps classifiers distinguish between normal behaviour and different types of attacks. To distil and retain more relevant features but remove less important/redundant ones during the training process, we further design and embed a feature selection layer right after the representation layer of MIAE resulting in a new model called MIAEFS. This layer learns the importance of features in the representation vector, facilitating the selection of informative features from the representation vector. The results on three IDS datasets, i.e., NSLKDD, UNSW-NB15, and IDS2017, show the superior performance of MIAE and MIAEFS compared to other methods, e.g., conventional classifiers, dimensionality reduction models, unsupervised representation learning methods with different input dimensions, and unsupervised feature selection models. Moreover, MIAE and MIAEFS combined with the Random Forest (RF) classifier achieve accuracy of 96.5% in detecting sophisticated attacks, e.g., Slowloris. The average running time for detecting an attack sample using RF with the representation of MIAE and MIAEFS is approximate 1.7E-6 seconds, whilst the model size is lower than 1 MB.
Twin Auto-Encoder Model for Learning Separable Representation in Cyberattack Detection
Mar 22, 2024



Representation Learning (RL) plays a pivotal role in the success of many problems including cyberattack detection. Most of the RL methods for cyberattack detection are based on the latent vector of Auto-Encoder (AE) models. An AE transforms raw data into a new latent representation that better exposes the underlying characteristics of the input data. Thus, it is very useful for identifying cyberattacks. However, due to the heterogeneity and sophistication of cyberattacks, the representation of AEs is often entangled/mixed resulting in the difficulty for downstream attack detection models. To tackle this problem, we propose a novel mod called Twin Auto-Encoder (TAE). TAE deterministically transforms the latent representation into a more distinguishable representation namely the \textit{separable representation} and the reconstructsuct the separable representation at the output. The output of TAE called the \textit{reconstruction representation} is input to downstream models to detect cyberattacks. We extensively evaluate the effectiveness of TAE using a wide range of bench-marking datasets. Experiment results show the superior accuracy of TAE over state-of-the-art RL models and well-known machine learning algorithms. Moreover, TAE also outperforms state-of-the-art models on some sophisticated and challenging attacks. We then investigate various characteristics of TAE to further demonstrate its superiority.