 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Design Patterns: A System-Theoretic Framework
Jan 27, 2026With the development of foundation model (FM), agentic AI systems are getting more attention, yet their inherent issues like hallucination and poor reasoning, coupled with the frequent ad-hoc nature of system design, lead to unreliable and brittle applications. Existing efforts to characterise agentic design patterns often lack a rigorous systems-theoretic foundation, resulting in high-level or convenience-based taxonomies that are difficult to implement. This paper addresses this gap by introducing a principled methodology for engineering robust AI agents. We propose two primary contributions: first, a novel system-theoretic framework that deconstructs an agentic AI system into five core, interacting functional subsystems: Reasoning & World Model, Perception & Grounding, Action Execution, Learning & Adaptation, and Inter-Agent Communication. Second, derived from this architecture and directly mapped to a comprehensive taxonomy of agentic challenges, we present a collection of 12 agentic design patterns. These patterns - categorised as Foundational, Cognitive & Decisional, Execution & Interaction, and Adaptive & Learning - offer reusable, structural solutions to recurring problems in agent design. The utility of the framework is demonstrated by a case study on the ReAct framework, showing how the proposed patterns can rectify systemic architectural deficiencies. This work provides a foundational language and a structured methodology to standardise agentic design communication among researchers and engineers, leading to more modular, understandable, and reliable autonomous systems.
Towards Verifiable Federated Unlearning: Framework, Challenges, and The Road Ahead
Oct 01, 2025Federated unlearning (FUL) enables removing the data influence from the model trained across distributed clients, upholding the right to be forgotten as mandated by privacy regulations. FUL facilitates a value exchange where clients gain privacy-preserving control over their data contributions, while service providers leverage decentralized computing and data freshness. However, this entire proposition is undermined because clients have no reliable way to verify that their data influence has been provably removed, as current metrics and simple notifications offer insufficient assurance. We envision unlearning verification becoming a pivotal and trust-by-design part of the FUL life-cycle development, essential for highly regulated and data-sensitive services and applications like healthcare. This article introduces veriFUL, a reference framework for verifiable FUL that formalizes verification entities, goals, approaches, and metrics. Specifically, we consolidate existing efforts and contribute new insights, concepts, and metrics to this domain. Finally, we highlight research challenges and identify potential applications and developments for verifiable FUL and veriFUL.
ToFU: Transforming How Federated Learning Systems Forget User Data
Sep 19, 2025Neural networks unintentionally memorize training data, creating privacy risks in federated learning (FL) systems, such as inference and reconstruction attacks on sensitive data. To mitigate these risks and to comply with privacy regulations, Federated Unlearning (FU) has been introduced to enable participants in FL systems to remove their data's influence from the global model. However, current FU methods primarily act post-hoc, struggling to efficiently erase information deeply memorized by neural networks. We argue that effective unlearning necessitates a paradigm shift: designing FL systems inherently amenable to forgetting. To this end, we propose a learning-to-unlearn Transformation-guided Federated Unlearning (ToFU) framework that incorporates transformations during the learning process to reduce memorization of specific instances. Our theoretical analysis reveals how transformation composition provably bounds instance-specific information, directly simplifying subsequent unlearning. Crucially, ToFU can work as a plug-and-play framework that improves the performance of existing FU methods. Experiments on CIFAR-10, CIFAR-100, and the MUFAC benchmark show that ToFU outperforms existing FU baselines, enhances performance when integrated with current methods, and reduces unlearning time.
Knowledge Abstraction for Knowledge-based Semantic Communication: A Generative Causality Invariant Approach
Jul 23, 2025In this study, we design a low-complexity and generalized AI model that can capture common knowledge to improve data reconstruction of the channel decoder for semantic communication. Specifically, we propose a generative adversarial network that leverages causality-invariant learning to extract causal and non-causal representations from the data. Causal representations are invariant and encompass crucial information to identify the data's label. They can encapsulate semantic knowledge and facilitate effective data reconstruction at the receiver. Moreover, the causal mechanism ensures that learned representations remain consistent across different domains, making the system reliable even with users collecting data from diverse domains. As user-collected data evolves over time causing knowledge divergence among users, we design sparse update protocols to improve the invariant properties of the knowledge while minimizing communication overheads. Three key observations were drawn from our empirical evaluations. Firstly, causality-invariant knowledge ensures consistency across different devices despite the diverse training data. Secondly, invariant knowledge has promising performance in classification tasks, which is pivotal for goal-oriented semantic communications. Thirdly, our knowledge-based data reconstruction highlights the robustness of our decoder, which surpasses other state-of-the-art data reconstruction and semantic compression methods in terms of Peak Signal-to-Noise Ratio (PSNR).
Integration of TinyML and LargeML: A Survey of 6G and Beyond
May 20, 2025

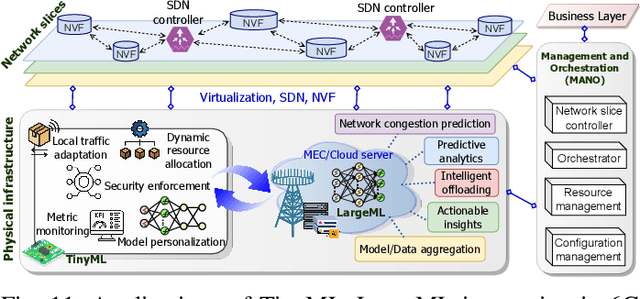
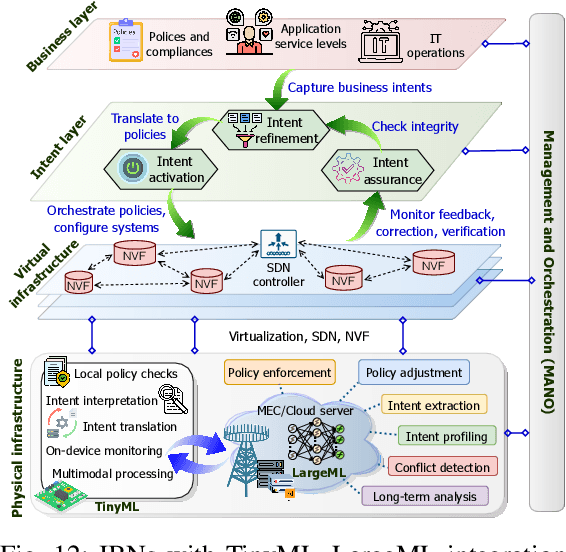
The transition from 5G networks to 6G highlights a significant demand for machine learning (ML). Deep learning models, in particular, have seen wide application in mobile networking and communications to support advanced services in emerging wireless environments, such as smart healthcare, smart grids, autonomous vehicles, aerial platforms, digital twins, and the metaverse. The rapid expansion of Internet-of-Things (IoT) devices, many with limited computational capabilities, has accelerated the development of tiny machine learning (TinyML) and resource-efficient ML approaches for cost-effective services. However, the deployment of large-scale machine learning (LargeML) solutions require major computing resources and complex management strategies to support extensive IoT services and ML-generated content applications. Consequently, the integration of TinyML and LargeML is projected as a promising approach for future seamless connectivity and efficient resource management. Although the integration of TinyML and LargeML shows abundant potential, several challenges persist, including performance optimization, practical deployment strategies, effective resource management, and security considerations. In this survey, we review and analyze the latest research aimed at enabling the integration of TinyML and LargeML models for the realization of smart services and applications in future 6G networks and beyond. The paper concludes by outlining critical challenges and identifying future research directions for the holistic integration of TinyML and LargeML in next-generation wireless networks.
Recent Advances in Near-Field Beam Training and Channel Estimation for XL-MIMO Systems
Apr 08, 2025Extremely large-scale multiple-input multiple-output (XL-MIMO) is a key technology for next-generation wireless communication systems. By deploying significantly more antennas than conventional massive MIMO systems, XL-MIMO promises substantial improvements in spectral efficiency. However, due to the drastically increased array size, the conventional planar wave channel model is no longer accurate, necessitating a transition to a near-field spherical wave model. This shift challenges traditional beam training and channel estimation methods, which were designed for planar wave propagation. In this article, we present a comprehensive review of state-of-the-art beam training and channel estimation techniques for XL-MIMO systems. We analyze the fundamental principles, key methodologies, and recent advancements in this area, highlighting their respective strengths and limitations in addressing the challenges posed by the near-field propagation environment. Furthermore, we explore open research challenges that remain unresolved to provide valuable insights for researchers and engineers working toward the development of next-generation XL-MIMO communication systems.
"Security for Everyone" in Finite Blocklength IRS-aided Systems With Perfect and Imperfect CSI
Apr 07, 2025Provisioning secrecy for all users, given the heterogeneity in their channel conditions, locations, and the unknown location of the attacker/eavesdropper, is challenging and not always feasible. The problem is even more difficult under finite blocklength constraints that are popular in ultra-reliable low-latency communication (URLLC) and massive machine-type communications (mMTC). This work takes the first step to guarantee secrecy for all URLLC/mMTC users in the finite blocklength regime (FBR) where intelligent reflecting surfaces (IRS) are used to enhance legitimate users' reception and thwart the potential eavesdropper (Eve) from intercepting. To that end, we aim to maximize the minimum secrecy rate (SR) among all users by jointly optimizing the transmitter's beamforming and IRS's passive reflective elements (PREs) under the FBR latency constraints. The resulting optimization problem is non-convex and even more complicated under imperfect channel state information (CSI). To tackle it, we linearize the objective function, and decompose the problem into sequential subproblems. When perfect CSI is not available, we use the successive convex approximation (SCA) approach to transform imperfect CSI-related semi-infinite constraints into finite linear matrix inequalities (LMI).
Right Reward Right Time for Federated Learning
Mar 10, 2025Critical learning periods (CLPs) in federated learning (FL) refer to early stages during which low-quality contributions (e.g., sparse training data availability) can permanently impair the learning performance of the global model owned by the model owner (i.e., the cloud server). However, strategies to motivate clients with high-quality contributions to join the FL training process and share trained model updates during CLPs remain underexplored. Additionally, existing incentive mechanisms in FL treat all training periods equally, which consequently fails to motivate clients to participate early. Compounding this challenge is the cloud's limited knowledge of client training capabilities due to privacy regulations, leading to information asymmetry. Therefore, in this article, we propose a time-aware incentive mechanism, called Right Reward Right Time (R3T), to encourage client involvement, especially during CLPs, to maximize the utility of the cloud in FL. Specifically, the cloud utility function captures the trade-off between the achieved model performance and payments allocated for clients' contributions, while accounting for clients' time and system capabilities, efforts, joining time, and rewards. Then, we analytically derive the optimal contract for the cloud and devise a CLP-aware mechanism to incentivize early participation and efforts while maximizing cloud utility, even under information asymmetry. By providing the right reward at the right time, our approach can attract the highest-quality contributions during CLPs. Simulation and proof-of-concept studies show that R3T increases cloud utility and is more economically effective than benchmarks. Notably, our proof-of-concept results show up to a 47.6% reduction in the total number of clients and up to a 300% improvement in convergence time while reaching competitive test accuracies compared with incentive mechanism benchmarks.
Quantum Annealing-Based Sum Rate Maximization for Multi-UAV-Aided Wireless Networks
Feb 25, 2025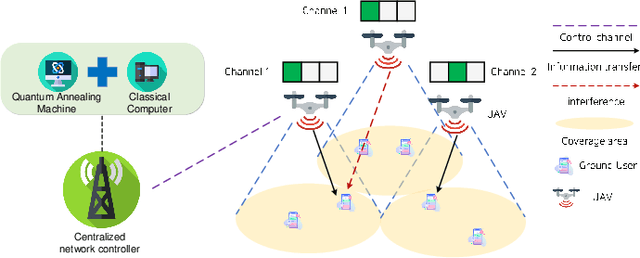
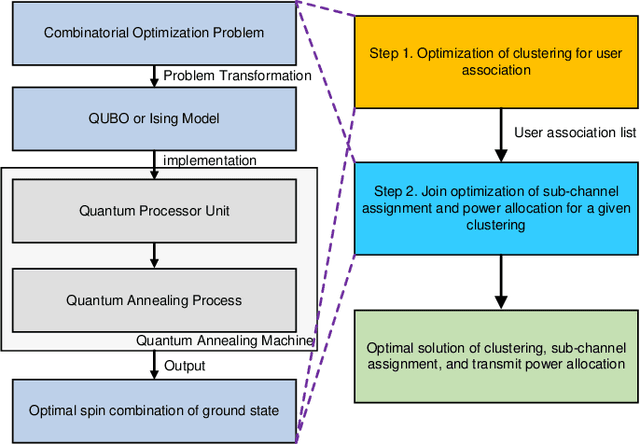
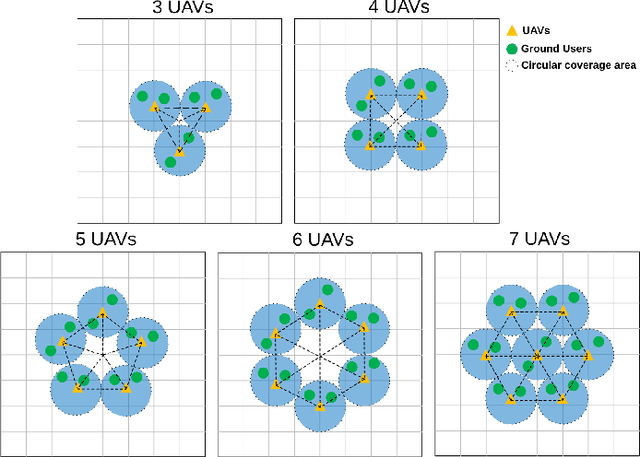
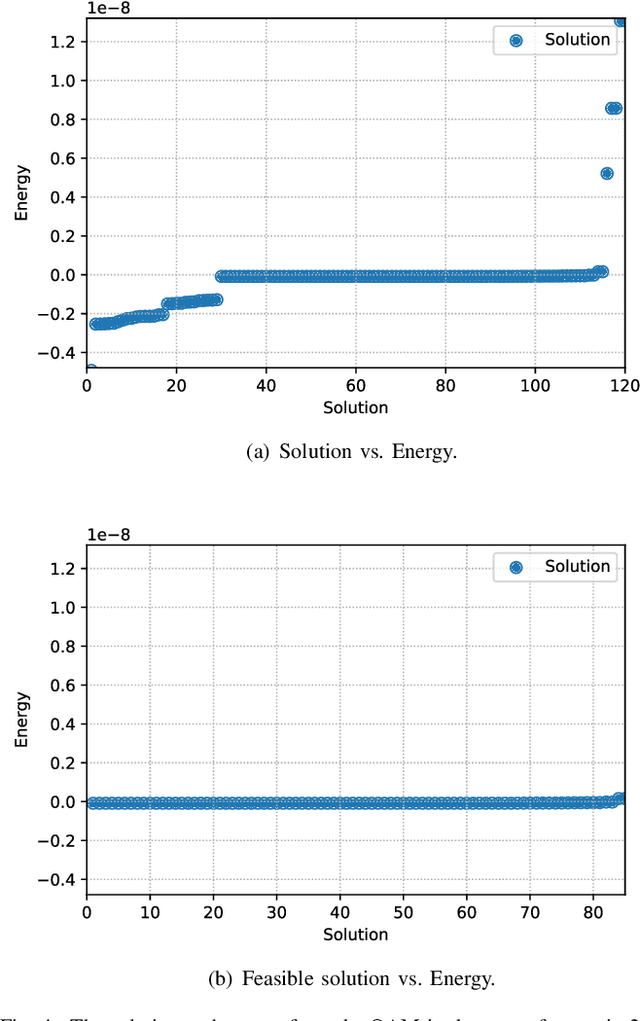
In wireless communication networks, it is difficult to solve many NP-hard problems owing to computational complexity and high cost. Recently, quantum annealing (QA) based on quantum physics was introduced as a key enabler for solving optimization problems quickly. However, only some studies consider quantum-based approaches in wireless communications. Therefore, we investigate the performance of a QA solution to an optimization problem in wireless networks. Specifically, we aim to maximize the sum rate by jointly optimizing clustering, sub-channel assignment, and power allocation in a multi-unmanned aerial vehicle-aided wireless network. We formulate the sum rate maximization problem as a combinatorial optimization problem. Then, we divide it into two sub-problems: 1) a QA-based clustering and 2) sub-channel assignment and power allocation for a given clustering configuration. Subsequently, we obtain an optimized solution for the joint optimization problem by solving these two sub-problems. For the first sub-problem, we convert the problem into a simplified quadratic unconstrained binary optimization (QUBO) model. As for the second sub-problem, we introduce a novel QA algorithm with optimal scaling parameters to address it. Simulation results demonstrate the effectiveness of the proposed algorithm in terms of the sum rate and running time.
Federated Domain Generalization with Data-free On-server Gradient Matching
Jan 24, 2025Domain Generalization (DG) aims to learn from multiple known source domains a model that can generalize well to unknown target domains. One of the key approaches in DG is training an encoder which generates domain-invariant representations. However, this approach is not applicable in Federated Domain Generalization (FDG), where data from various domains are distributed across different clients. In this paper, we introduce a novel approach, dubbed Federated Learning via On-server Matching Gradient (FedOMG), which can \emph{efficiently leverage domain information from distributed domains}. Specifically, we utilize the local gradients as information about the distributed models to find an invariant gradient direction across all domains through gradient inner product maximization. The advantages are two-fold: 1) FedOMG can aggregate the characteristics of distributed models on the centralized server without incurring any additional communication cost, and 2) FedOMG is orthogonal to many existing FL/FDG methods, allowing for additional performance improvements by being seamlessly integrated with them. Extensive experimental evaluations on various settings to demonstrate the robustness of FedOMG compared to other FL/FDG baselines. Our method outperforms recent SOTA baselines on four FL benchmark datasets (MNIST, EMNIST, CIFAR-10, and CIFAR-100), and three FDG benchmark datasets (PACS, VLCS, and OfficeHome).