 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Modeling in Protein Design: Neural Representations, Conditional Generation, and Evaluation Standards
Mar 27, 2026Generative modeling has become a central paradigm in protein research, extending machine learning beyond structure prediction toward sequence design, backbone generation, inverse folding, and biomolecular interaction modeling. However, the literature remains fragmented across representations, model classes, and task formulations, making it difficult to compare methods or identify appropriate evaluation standards. This survey provides a systematic synthesis of generative AI in protein research, organized around (i) foundational representations spanning sequence, geometric, and multimodal encodings; (ii) generative architectures including $\mathrm{SE}(3)$-equivariant diffusion, flow matching, and hybrid predictor-generator systems; and (iii) task settings from structure prediction and de novo design to protein-ligand and protein-protein interactions. Beyond cataloging methods, we compare assumptions, conditioning mechanisms, and controllability, and we synthesize evaluation best practices that emphasize leakage-aware splits, physical validity checks, and function-oriented benchmarks. We conclude with critical open challenges: modeling conformational dynamics and intrinsically disordered regions, scaling to large assemblies while maintaining efficiency, and developing robust safety frameworks for dual-use biosecurity risks. By unifying architectural advances with practical evaluation standards and responsible development considerations, this survey aims to accelerate the transition from predictive modeling to reliable, function-driven protein engineering.
Prototypical Exemplar Condensation for Memory-efficient Online Continual Learning
Mar 14, 2026Rehearsal-based continual learning (CL) mitigates catastrophic forgetting by maintaining a subset of samples from previous tasks for replay. Existing studies primarily focus on optimizing memory storage through coreset selection strategies. While these methods are effective, they typically require storing a substantial number of samples per class (SPC), often exceeding 20, to maintain satisfactory performance. In this work, we propose to further compress the memory footprint by synthesizing and storing prototypical exemplars, which can form representative prototypes when passed through the feature extractor. Owing to their representative nature, these exemplars enable the model to retain previous knowledge using only a small number of samples while preserving privacy. Moreover, we introduce a perturbation-based augmentation mechanism that generates synthetic variants of previous data during training, thereby enhancing CL performance. Extensive evaluations on widely used benchmark datasets and settings demonstrate that the proposed algorithm achieves superior performance compared to existing baselines, particularly in scenarios involving large-scale datasets and a high number of tasks.
Knowledge Abstraction for Knowledge-based Semantic Communication: A Generative Causality Invariant Approach
Jul 23, 2025In this study, we design a low-complexity and generalized AI model that can capture common knowledge to improve data reconstruction of the channel decoder for semantic communication. Specifically, we propose a generative adversarial network that leverages causality-invariant learning to extract causal and non-causal representations from the data. Causal representations are invariant and encompass crucial information to identify the data's label. They can encapsulate semantic knowledge and facilitate effective data reconstruction at the receiver. Moreover, the causal mechanism ensures that learned representations remain consistent across different domains, making the system reliable even with users collecting data from diverse domains. As user-collected data evolves over time causing knowledge divergence among users, we design sparse update protocols to improve the invariant properties of the knowledge while minimizing communication overheads. Three key observations were drawn from our empirical evaluations. Firstly, causality-invariant knowledge ensures consistency across different devices despite the diverse training data. Secondly, invariant knowledge has promising performance in classification tasks, which is pivotal for goal-oriented semantic communications. Thirdly, our knowledge-based data reconstruction highlights the robustness of our decoder, which surpasses other state-of-the-art data reconstruction and semantic compression methods in terms of Peak Signal-to-Noise Ratio (PSNR).
Federated Domain Generalization with Data-free On-server Gradient Matching
Jan 24, 2025Domain Generalization (DG) aims to learn from multiple known source domains a model that can generalize well to unknown target domains. One of the key approaches in DG is training an encoder which generates domain-invariant representations. However, this approach is not applicable in Federated Domain Generalization (FDG), where data from various domains are distributed across different clients. In this paper, we introduce a novel approach, dubbed Federated Learning via On-server Matching Gradient (FedOMG), which can \emph{efficiently leverage domain information from distributed domains}. Specifically, we utilize the local gradients as information about the distributed models to find an invariant gradient direction across all domains through gradient inner product maximization. The advantages are two-fold: 1) FedOMG can aggregate the characteristics of distributed models on the centralized server without incurring any additional communication cost, and 2) FedOMG is orthogonal to many existing FL/FDG methods, allowing for additional performance improvements by being seamlessly integrated with them. Extensive experimental evaluations on various settings to demonstrate the robustness of FedOMG compared to other FL/FDG baselines. Our method outperforms recent SOTA baselines on four FL benchmark datasets (MNIST, EMNIST, CIFAR-10, and CIFAR-100), and three FDG benchmark datasets (PACS, VLCS, and OfficeHome).
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
Jan 10, 2025With recent advances in Large Language Models (LLMs), Agentic AI has become phenomenal in real-world applications, moving toward multiple LLM-based agents to perceive, learn, reason, and act collaboratively. These LLM-based Multi-Agent Systems (MASs) enable groups of intelligent agents to coordinate and solve complex tasks collectively at scale, transitioning from isolated models to collaboration-centric approaches. This work provides an extensive survey of the collaborative aspect of MASs and introduces an extensible framework to guide future research. Our framework characterizes collaboration mechanisms based on key dimensions: actors (agents involved), types (e.g., cooperation, competition, or coopetition), structures (e.g., peer-to-peer, centralized, or distributed), strategies (e.g., role-based or model-based), and coordination protocols. Through a review of existing methodologies, our findings serve as a foundation for demystifying and advancing LLM-based MASs toward more intelligent and collaborative solutions for complex, real-world use cases. In addition, various applications of MASs across diverse domains, including 5G/6G networks, Industry 5.0, question answering, and social and cultural settings, are also investigated, demonstrating their wider adoption and broader impacts. Finally, we identify key lessons learned, open challenges, and potential research directions of MASs towards artificial collective intelligence.
Applications of Generative AI for Mobile and Wireless Networking: A Survey
May 30, 2024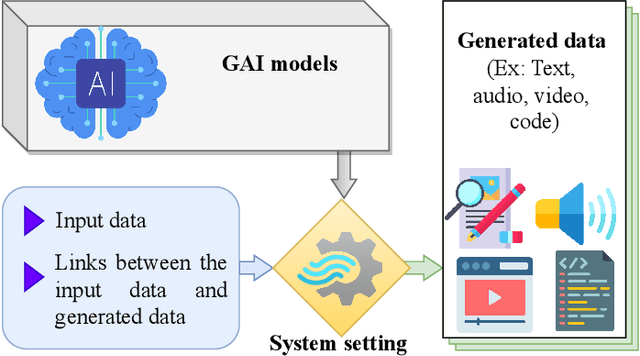
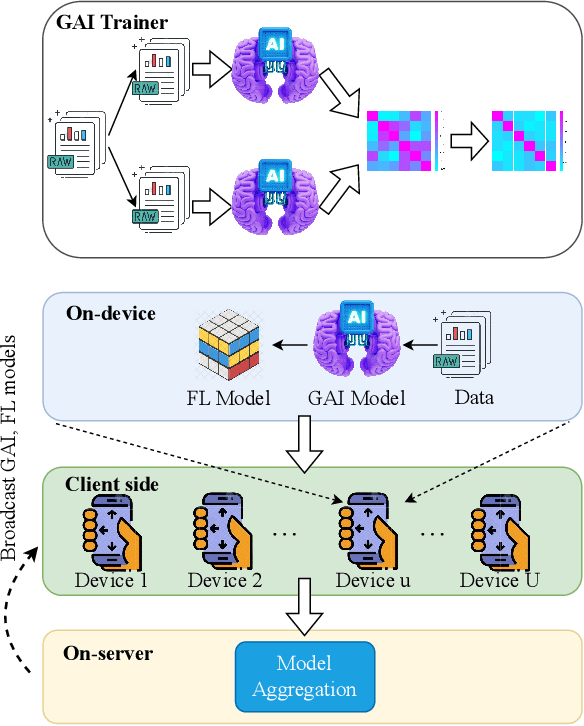
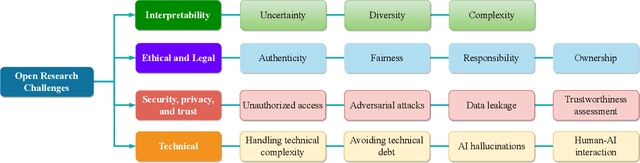
The success of Artificial Intelligence (AI) in multiple disciplines and vertical domains in recent years has promoted the evolution of mobile networking and the future Internet toward an AI-integrated Internet-of-Things (IoT) era. Nevertheless, most AI techniques rely on data generated by physical devices (e.g., mobile devices and network nodes) or specific applications (e.g., fitness trackers and mobile gaming). To bypass this circumvent, Generative AI (GAI), a.k.a. AI-generated content (AIGC), has emerged as a powerful AI paradigm; thanks to its ability to efficiently learn complex data distributions and generate synthetic data to represent the original data in various forms. This impressive feature is projected to transform the management of mobile networking and diversify the current services and applications provided. On this basis, this work presents a concise tutorial on the role of GAIs in mobile and wireless networking. In particular, this survey first provides the fundamentals of GAI and representative GAI models, serving as an essential preliminary to the understanding of the applications of GAI in mobile and wireless networking. Then, this work provides a comprehensive review of state-of-the-art studies and GAI applications in network management, wireless security, semantic communication, and lessons learned from the open literature. Finally, this work summarizes the current research on GAI for mobile and wireless networking by outlining important challenges that need to be resolved to facilitate the development and applicability of GAI in this edge-cutting area.
Sample-Driven Federated Learning for Energy-Efficient and Real-Time IoT Sensing
Oct 11, 2023In the domain of Federated Learning (FL) systems, recent cutting-edge methods heavily rely on ideal conditions convergence analysis. Specifically, these approaches assume that the training datasets on IoT devices possess similar attributes to the global data distribution. However, this approach fails to capture the full spectrum of data characteristics in real-time sensing FL systems. In order to overcome this limitation, we suggest a new approach system specifically designed for IoT networks with real-time sensing capabilities. Our approach takes into account the generalization gap due to the user's data sampling process. By effectively controlling this sampling process, we can mitigate the overfitting issue and improve overall accuracy. In particular, We first formulate an optimization problem that harnesses the sampling process to concurrently reduce overfitting while maximizing accuracy. In pursuit of this objective, our surrogate optimization problem is adept at handling energy efficiency while optimizing the accuracy with high generalization. To solve the optimization problem with high complexity, we introduce an online reinforcement learning algorithm, named Sample-driven Control for Federated Learning (SCFL) built on the Soft Actor-Critic (A2C) framework. This enables the agent to dynamically adapt and find the global optima even in changing environments. By leveraging the capabilities of SCFL, our system offers a promising solution for resource allocation in FL systems with real-time sensing capabilities.
Joint Communication and Computation Framework for Goal-Oriented Semantic Communication with Distortion Rate Resilience
Sep 26, 2023Recent research efforts on semantic communication have mostly considered accuracy as a main problem for optimizing goal-oriented communication systems. However, these approaches introduce a paradox: the accuracy of artificial intelligence (AI) tasks should naturally emerge through training rather than being dictated by network constraints. Acknowledging this dilemma, this work introduces an innovative approach that leverages the rate-distortion theory to analyze distortions induced by communication and semantic compression, thereby analyzing the learning process. Specifically, we examine the distribution shift between the original data and the distorted data, thus assessing its impact on the AI model's performance. Founding upon this analysis, we can preemptively estimate the empirical accuracy of AI tasks, making the goal-oriented semantic communication problem feasible. To achieve this objective, we present the theoretical foundation of our approach, accompanied by simulations and experiments that demonstrate its effectiveness. The experimental results indicate that our proposed method enables accurate AI task performance while adhering to network constraints, establishing it as a valuable contribution to the field of signal processing. Furthermore, this work advances research in goal-oriented semantic communication and highlights the significance of data-driven approaches in optimizing the performance of intelligent systems.
Label driven Knowledge Distillation for Federated Learning with non-IID Data
Sep 30, 2022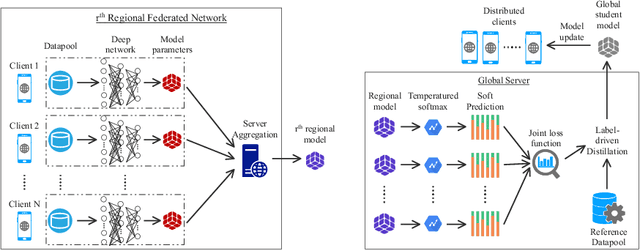
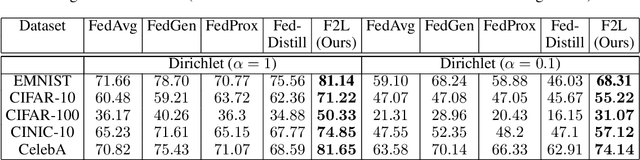
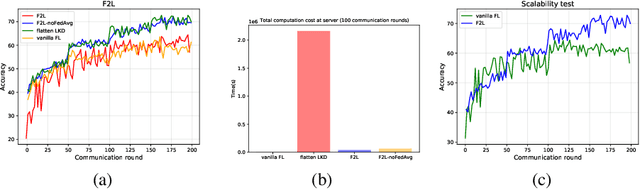
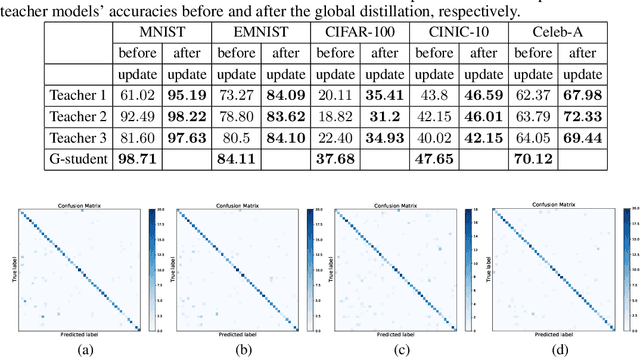
In real-world applications, Federated Learning (FL) meets two challenges: (1) scalability, especially when applied to massive IoT networks; and (2) how to be robust against an environment with heterogeneous data. Realizing the first problem, we aim to design a novel FL framework named Full-stack FL (F2L). More specifically, F2L utilizes a hierarchical network architecture, making extending the FL network accessible without reconstructing the whole network system. Moreover, leveraging the advantages of hierarchical network design, we propose a new label-driven knowledge distillation (LKD) technique at the global server to address the second problem. As opposed to current knowledge distillation techniques, LKD is capable of training a student model, which consists of good knowledge from all teachers' models. Therefore, our proposed algorithm can effectively extract the knowledge of the regions' data distribution (i.e., the regional aggregated models) to reduce the divergence between clients' models when operating under the FL system with non-independent identically distributed data. Extensive experiment results reveal that: (i) our F2L method can significantly improve the overall FL efficiency in all global distillations, and (ii) F2L rapidly achieves convergence as global distillation stages occur instead of increasing on each communication cycle.
HCFL: A High Compression Approach for Communication-Efficient Federated Learning in Very Large Scale IoT Networks
Apr 14, 2022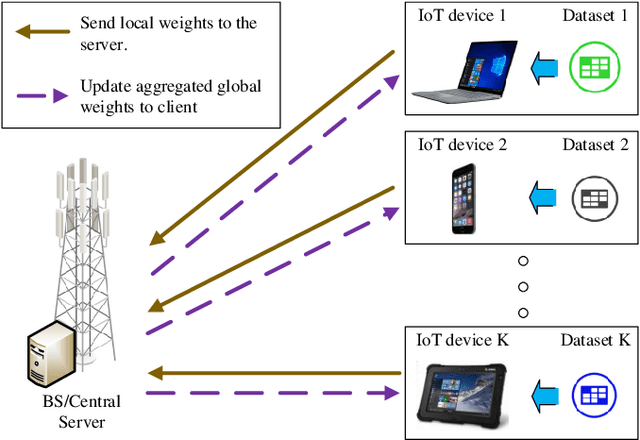
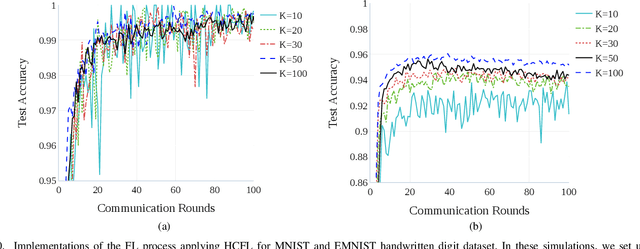
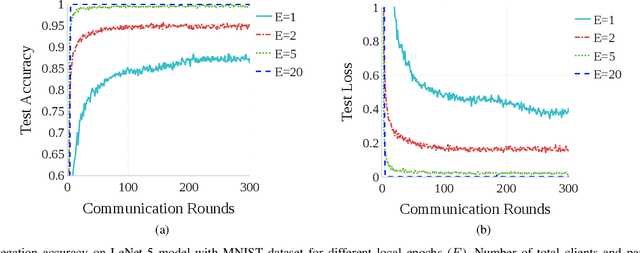
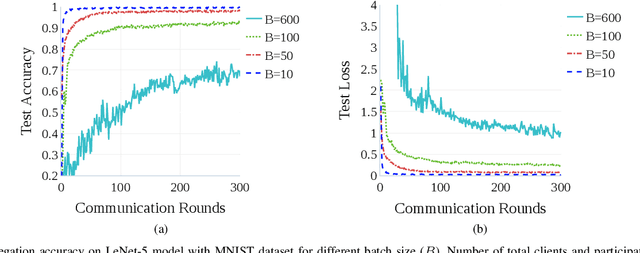
Federated learning (FL) is a new artificial intelligence concept that enables Internet-of-Things (IoT) devices to learn a collaborative model without sending the raw data to centralized nodes for processing. Despite numerous advantages, low computing resources at IoT devices and high communication costs for exchanging model parameters make applications of FL in massive IoT networks very limited. In this work, we develop a novel compression scheme for FL, called high-compression federated learning (HCFL), for very large scale IoT networks. HCFL can reduce the data load for FL processes without changing their structure and hyperparameters. In this way, we not only can significantly reduce communication costs, but also make intensive learning processes more adaptable on low-computing resource IoT devices. Furthermore, we investigate a relationship between the number of IoT devices and the convergence level of the FL model and thereby better assess the quality of the FL process. We demonstrate our HCFL scheme in both simulations and mathematical analyses. Our proposed theoretical research can be used as a minimum level of satisfaction, proving that the FL process can achieve good performance when a determined configuration is met. Therefore, we show that HCFL is applicable in any FL-integrated networks with numerous IoT devices.