 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHCFL: A High Compression Approach for Communication-Efficient Federated Learning in Very Large Scale IoT Networks
Apr 14, 2022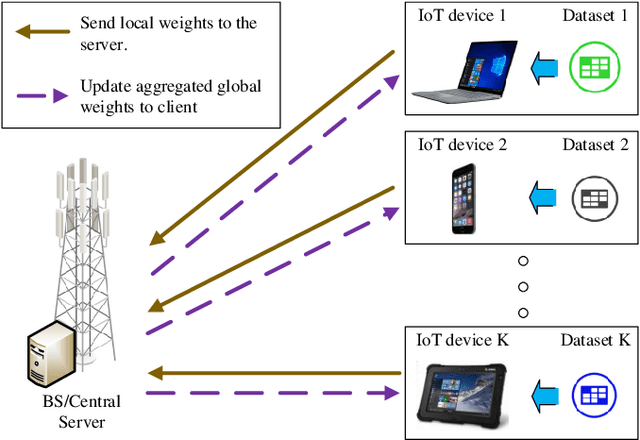
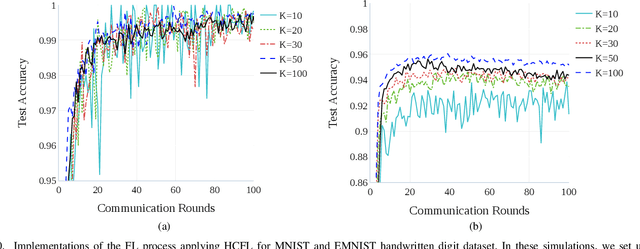
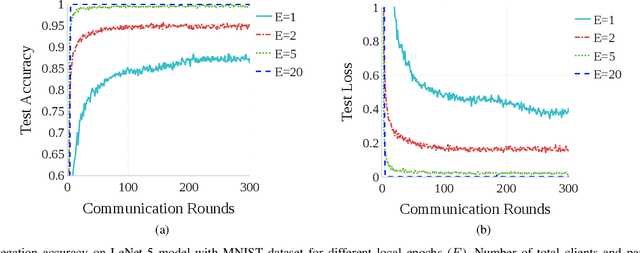
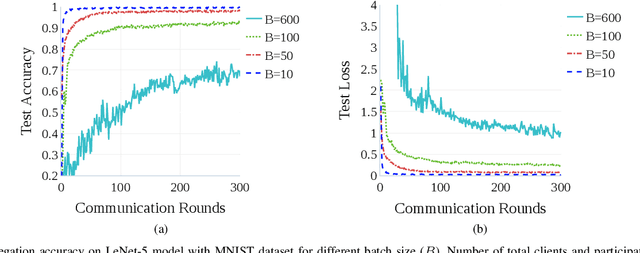
Federated learning (FL) is a new artificial intelligence concept that enables Internet-of-Things (IoT) devices to learn a collaborative model without sending the raw data to centralized nodes for processing. Despite numerous advantages, low computing resources at IoT devices and high communication costs for exchanging model parameters make applications of FL in massive IoT networks very limited. In this work, we develop a novel compression scheme for FL, called high-compression federated learning (HCFL), for very large scale IoT networks. HCFL can reduce the data load for FL processes without changing their structure and hyperparameters. In this way, we not only can significantly reduce communication costs, but also make intensive learning processes more adaptable on low-computing resource IoT devices. Furthermore, we investigate a relationship between the number of IoT devices and the convergence level of the FL model and thereby better assess the quality of the FL process. We demonstrate our HCFL scheme in both simulations and mathematical analyses. Our proposed theoretical research can be used as a minimum level of satisfaction, proving that the FL process can achieve good performance when a determined configuration is met. Therefore, we show that HCFL is applicable in any FL-integrated networks with numerous IoT devices.