 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Annealing-Based Sum Rate Maximization for Multi-UAV-Aided Wireless Networks
Feb 25, 2025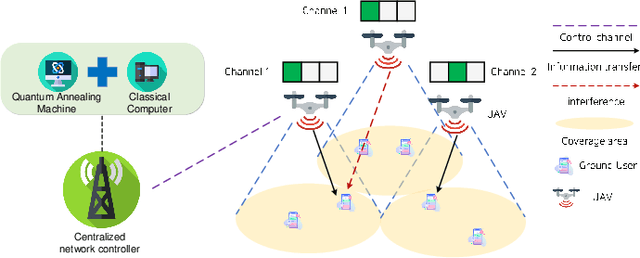
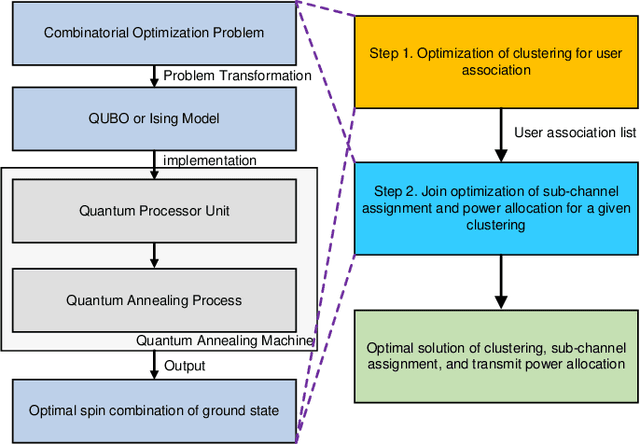
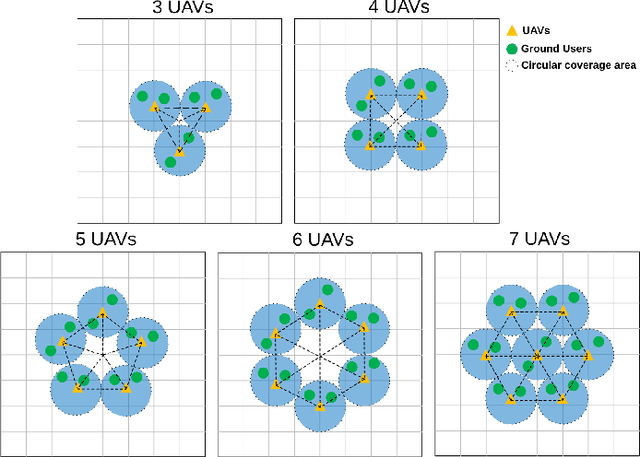
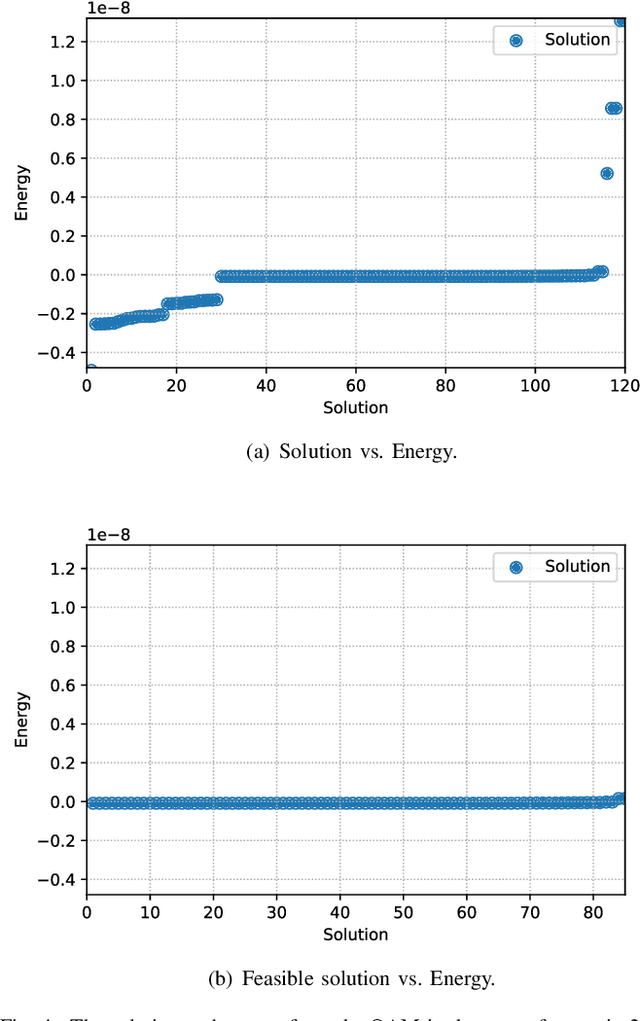
In wireless communication networks, it is difficult to solve many NP-hard problems owing to computational complexity and high cost. Recently, quantum annealing (QA) based on quantum physics was introduced as a key enabler for solving optimization problems quickly. However, only some studies consider quantum-based approaches in wireless communications. Therefore, we investigate the performance of a QA solution to an optimization problem in wireless networks. Specifically, we aim to maximize the sum rate by jointly optimizing clustering, sub-channel assignment, and power allocation in a multi-unmanned aerial vehicle-aided wireless network. We formulate the sum rate maximization problem as a combinatorial optimization problem. Then, we divide it into two sub-problems: 1) a QA-based clustering and 2) sub-channel assignment and power allocation for a given clustering configuration. Subsequently, we obtain an optimized solution for the joint optimization problem by solving these two sub-problems. For the first sub-problem, we convert the problem into a simplified quadratic unconstrained binary optimization (QUBO) model. As for the second sub-problem, we introduce a novel QA algorithm with optimal scaling parameters to address it. Simulation results demonstrate the effectiveness of the proposed algorithm in terms of the sum rate and running time.
Energy Efficient Transmission Parameters Selection Method Using Reinforcement Learning in Distributed LoRa Networks
Oct 15, 2024



With the increase in demand for Internet of Things (IoT) applications, the number of IoT devices has drastically grown, making spectrum resources seriously insufficient. Transmission collisions and retransmissions increase power consumption. Therefore, even in long-range (LoRa) networks, selecting appropriate transmission parameters, such as channel and transmission power, is essential to improve energy efficiency. However, due to the limited computational ability and memory, traditional transmission parameter selection methods for LoRa networks are challenging to implement on LoRa devices. To solve this problem, a distributed reinforcement learning-based channel and transmission power selection method is proposed, which can be implemented on the LoRa devices to improve energy efficiency in this paper. Specifically, the channel and transmission power selection problem in LoRa networks is first mapped to the multi-armed-bandit (MAB) problem. Then, an MAB-based method is introduced to solve the formulated transmission parameter selection problem based on the acknowledgment (ACK) packet and the power consumption for data transmission of the LoRa device. The performance of the proposed method is evaluated by the constructed actual LoRa network. Experimental results show that the proposed method performs better than fixed assignment, adaptive data rate low-complexity (ADR-Lite), and $\epsilon$-greedy-based methods in terms of both transmission success rate and energy efficiency.
A Lightweight Transmission Parameter Selection Scheme Using Reinforcement Learning for LoRaWAN
Aug 03, 2022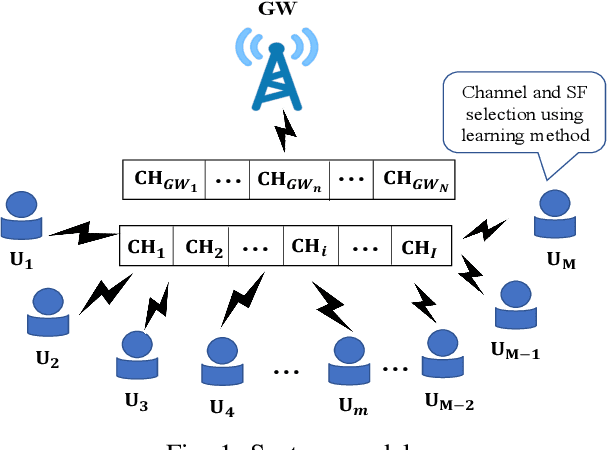
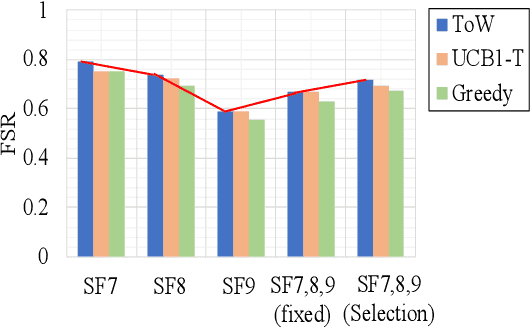
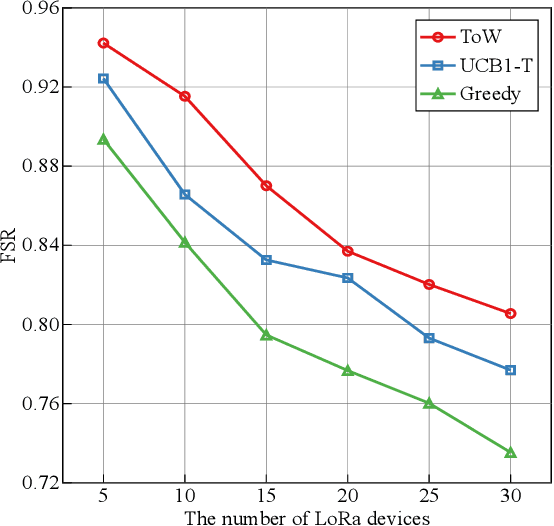
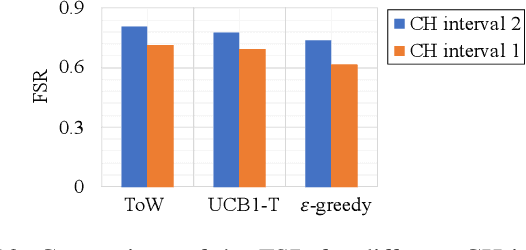
The number of IoT devices is predicted to reach 125 billion by 2023. The growth of IoT devices will intensify the collisions between devices, degrading communication performance. Selecting appropriate transmission parameters, such as channel and spreading factor (SF), can effectively reduce the collisions between long-range (LoRa) devices. However, most of the schemes proposed in the current literature are not easy to implement on an IoT device with limited computational complexity and memory. To solve this issue, we propose a lightweight transmission-parameter selection scheme, i.e., a joint channel and SF selection scheme using reinforcement learning for low-power wide area networking (LoRaWAN). In the proposed scheme, appropriate transmission parameters can be selected by simple four arithmetic operations using only Acknowledge (ACK) information. Additionally, we theoretically analyze the computational complexity and memory requirement of our proposed scheme, which verified that our proposed scheme could select transmission parameters with extremely low computational complexity and memory requirement. Moreover, a large number of experiments were implemented on the LoRa devices in the real world to evaluate the effectiveness of our proposed scheme. The experimental results demonstrate the following main phenomena. (1) Compared to other lightweight transmission-parameter selection schemes, collisions between LoRa devices can be efficiently avoided by our proposed scheme in LoRaWAN irrespective of changes in the available channels. (2) The frame success rate (FSR) can be improved by selecting access channels and using SFs as opposed to only selecting access channels. (3) Since interference exists between adjacent channels, FSR and fairness can be improved by increasing the interval of adjacent available channels.
Theory of Acceleration of Decision Making by Correlated Times Sequences
Mar 30, 2022



Photonic accelerators have been intensively studied to provide enhanced information processing capability to benefit from the unique attributes of physical processes. Recently, it has been reported that chaotically oscillating ultrafast time series from a laser, called laser chaos, provides the ability to solve multi-armed bandit (MAB) problems or decision-making problems at GHz order. Furthermore, it has been confirmed that the negatively correlated time-domain structure of laser chaos contributes to the acceleration of decision-making. However, the underlying mechanism of why decision-making is accelerated by correlated time series is unknown. In this paper, we demonstrate a theoretical model to account for the acceleration of decision-making by correlated time sequence. We first confirm the effectiveness of the negative autocorrelation inherent in time series for solving two-armed bandit problems using Fourier transform surrogate methods. We propose a theoretical model that concerns the correlated time series subjected to the decision-making system and the internal status of the system therein in a unified manner, inspired by correlated random walks. We demonstrate that the performance derived analytically by the theory agrees well with the numerical simulations, which confirms the validity of the proposed model and leads to optimal system design. The present study paves the new way for the effectiveness of correlated time series for decision-making, impacting artificial intelligence and other applications.
Resource allocation method using tug-of-war-based synchronization
Aug 19, 2021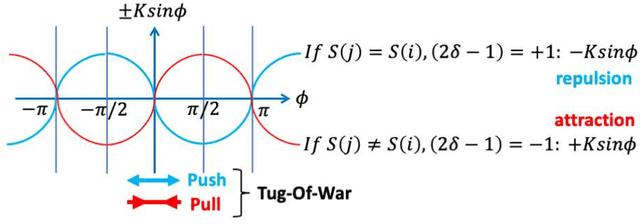
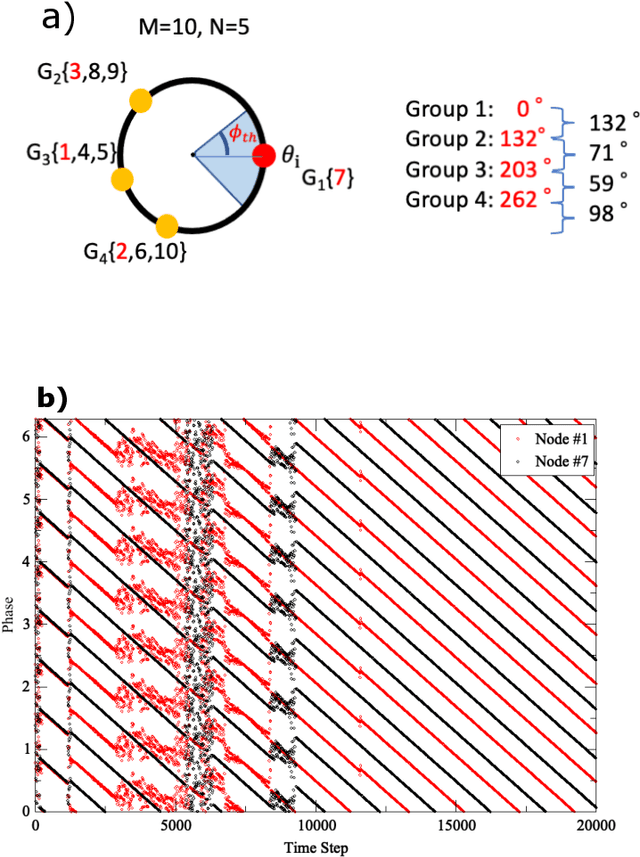
We propose a simple channel-allocation method based on tug-of-war (TOW) dynamics, combined with the time scheduling based on nonlinear oscillator synchronization to efficiently use of the space (channel) and time resources in wireless communications. This study demonstrates that synchronization groups, where each node selects a different channel, are non-uniformly distributed in phase space such that every distance between groups is larger than the area of influence. New type of self-organized spatiotemporal patterns can be formed for resource allocation according to channel rewards.
Arm order recognition in multi-armed bandit problem with laser chaos time series
May 26, 2020



By exploiting ultrafast and irregular time series generated by lasers with delayed feedback, we have previously demonstrated a scalable algorithm to solve multi-armed bandit (MAB) problems utilizing the time-division multiplexing of laser chaos time series. Although the algorithm detects the arm with the highest reward expectation, the correct recognition of the order of arms in terms of reward expectations is not achievable. Here, we present an algorithm where the degree of exploration is adaptively controlled based on confidence intervals that represent the estimation accuracy of reward expectations. We have demonstrated numerically that our approach did improve arm order recognition accuracy significantly, along with reduced dependence on reward environments, and the total reward is almost maintained compared with conventional MAB methods. This study applies to sectors where the order information is critical, such as efficient allocation of resources in information and communications technology.
Scalable photonic reinforcement learning by time-division multiplexing of laser chaos
Mar 26, 2018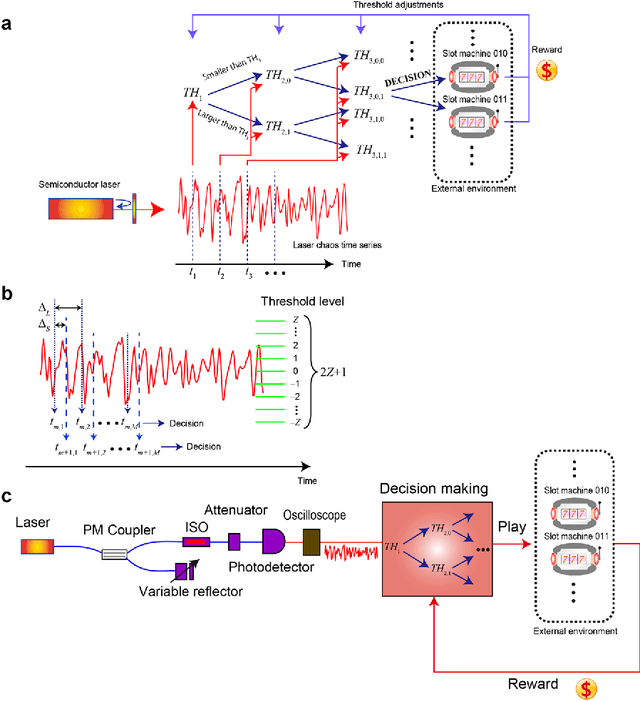

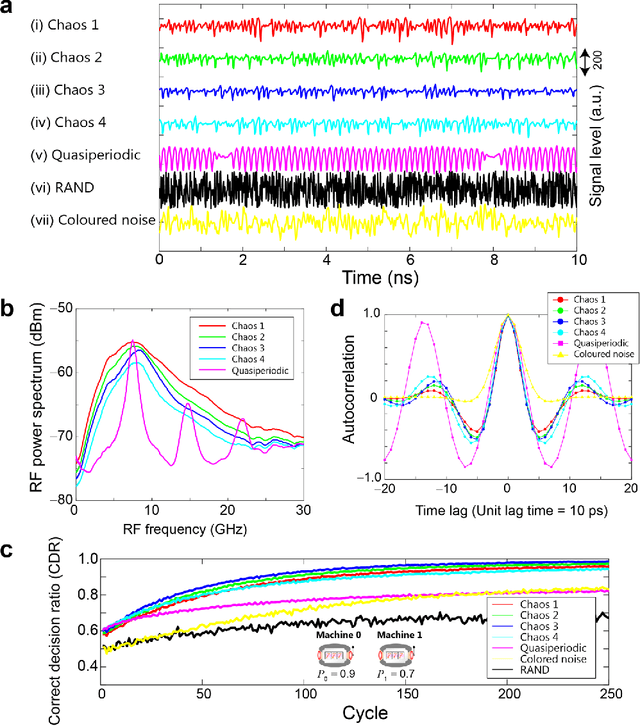
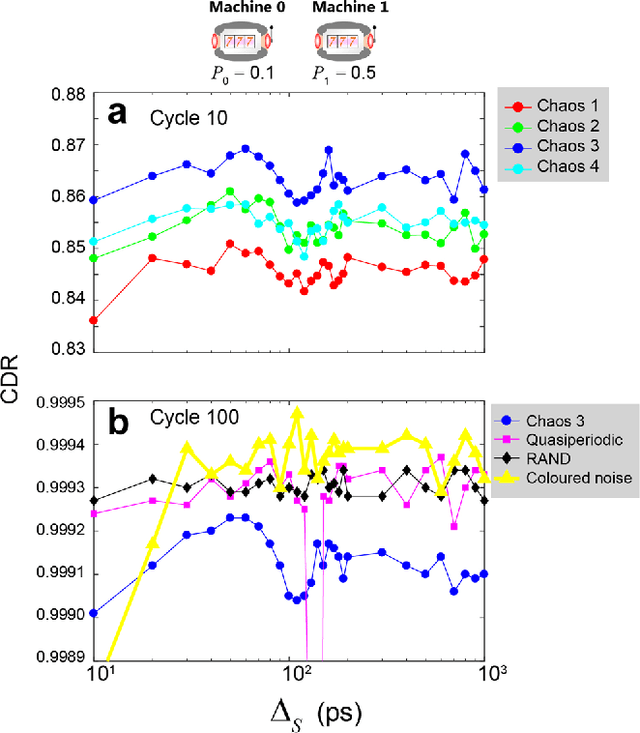
Reinforcement learning involves decision making in dynamic and uncertain environments and constitutes a crucial element of artificial intelligence. In our previous work, we experimentally demonstrated that the ultrafast chaotic oscillatory dynamics of lasers can be used to solve the two-armed bandit problem efficiently, which requires decision making concerning a class of difficult trade-offs called the exploration-exploitation dilemma. However, only two selections were employed in that research; thus, the scalability of the laser-chaos-based reinforcement learning should be clarified. In this study, we demonstrated a scalable, pipelined principle of resolving the multi-armed bandit problem by introducing time-division multiplexing of chaotically oscillated ultrafast time-series. The experimental demonstrations in which bandit problems with up to 64 arms were successfully solved are presented in this report. Detailed analyses are also provided that include performance comparisons among laser chaos signals generated in different physical conditions, which coincide with the diffusivity inherent in the time series. This study paves the way for ultrafast reinforcement learning by taking advantage of the ultrahigh bandwidths of light wave and practical enabling technologies.