 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Transmission Parameter Selection Scheme Using Reinforcement Learning for LoRaWAN
Aug 03, 2022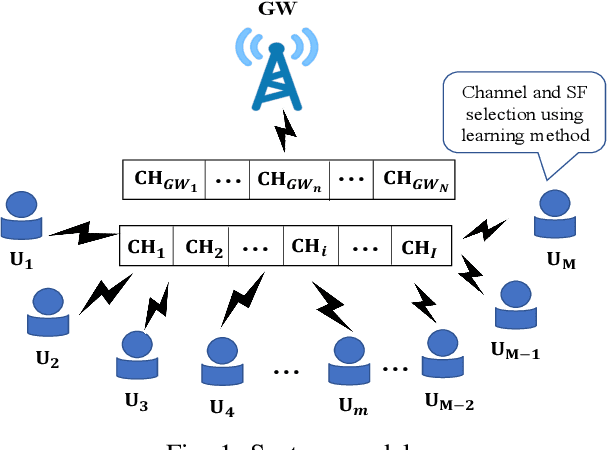
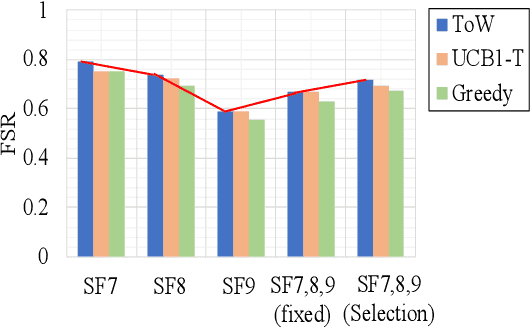
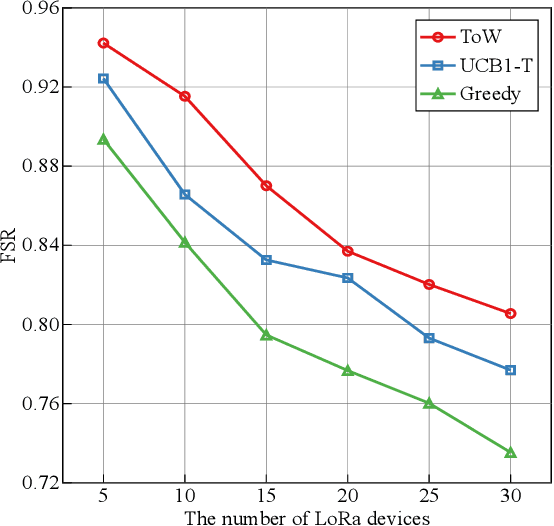
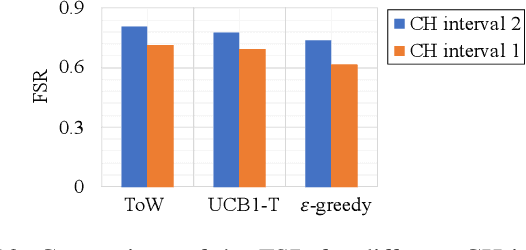
The number of IoT devices is predicted to reach 125 billion by 2023. The growth of IoT devices will intensify the collisions between devices, degrading communication performance. Selecting appropriate transmission parameters, such as channel and spreading factor (SF), can effectively reduce the collisions between long-range (LoRa) devices. However, most of the schemes proposed in the current literature are not easy to implement on an IoT device with limited computational complexity and memory. To solve this issue, we propose a lightweight transmission-parameter selection scheme, i.e., a joint channel and SF selection scheme using reinforcement learning for low-power wide area networking (LoRaWAN). In the proposed scheme, appropriate transmission parameters can be selected by simple four arithmetic operations using only Acknowledge (ACK) information. Additionally, we theoretically analyze the computational complexity and memory requirement of our proposed scheme, which verified that our proposed scheme could select transmission parameters with extremely low computational complexity and memory requirement. Moreover, a large number of experiments were implemented on the LoRa devices in the real world to evaluate the effectiveness of our proposed scheme. The experimental results demonstrate the following main phenomena. (1) Compared to other lightweight transmission-parameter selection schemes, collisions between LoRa devices can be efficiently avoided by our proposed scheme in LoRaWAN irrespective of changes in the available channels. (2) The frame success rate (FSR) can be improved by selecting access channels and using SFs as opposed to only selecting access channels. (3) Since interference exists between adjacent channels, FSR and fairness can be improved by increasing the interval of adjacent available channels.
Resource allocation method using tug-of-war-based synchronization
Aug 19, 2021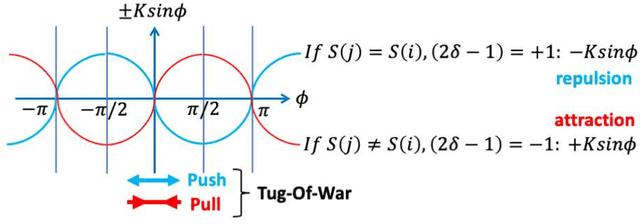
We propose a simple channel-allocation method based on tug-of-war (TOW) dynamics, combined with the time scheduling based on nonlinear oscillator synchronization to efficiently use of the space (channel) and time resources in wireless communications. This study demonstrates that synchronization groups, where each node selects a different channel, are non-uniformly distributed in phase space such that every distance between groups is larger than the area of influence. New type of self-organized spatiotemporal patterns can be formed for resource allocation according to channel rewards.
A Balance for Fairness: Fair Distribution Utilising Physics in Games of Characteristic Function Form
Feb 05, 2021



In chaotic modern society, there is an increasing demand for the realization of true 'fairness'. In Greek mythology, Themis, the 'goddess of justice', has a sword in her right hand to protect society from vices, and a 'balance of judgment' in her left hand that measures good and evil. In this study, we propose a fair distribution method 'utilising physics' for the profit in games of characteristic function form. Specifically, we show that the linear programming problem for calculating 'nucleolus' can be efficiently solved by considering it as a physical system in which gravity works. In addition to being able to significantly reduce computational complexity thereby, we believe that this system could have flexibility necessary to respond to real-time changes in the parameter.
Category Theoretic Analysis of Photon-based Decision Making
May 09, 2018Decision making is a vital function in this age of machine learning and artificial intelligence, yet its physical realization and theoretical fundamentals are still not completely understood. In our former study, we demonstrated that single-photons can be used to make decisions in uncertain, dynamically changing environments. The two-armed bandit problem was successfully solved using the dual probabilistic and particle attributes of single photons. In this study, we present a category theoretic modeling and analysis of single-photon-based decision making, including a quantitative analysis that is in agreement with the experimental results. A category theoretic model reveals the complex interdependencies of subject matter entities in a simplified manner, even in dynamically changing environments. In particular, the octahedral and braid structures in triangulated categories provide a better understanding and quantitative metrics of the underlying mechanisms of a single-photon decision maker. This study provides both insight and a foundation for analyzing more complex and uncertain problems, to further machine learning and artificial intelligence.
Ultrafast photonic reinforcement learning based on laser chaos
Apr 14, 2017


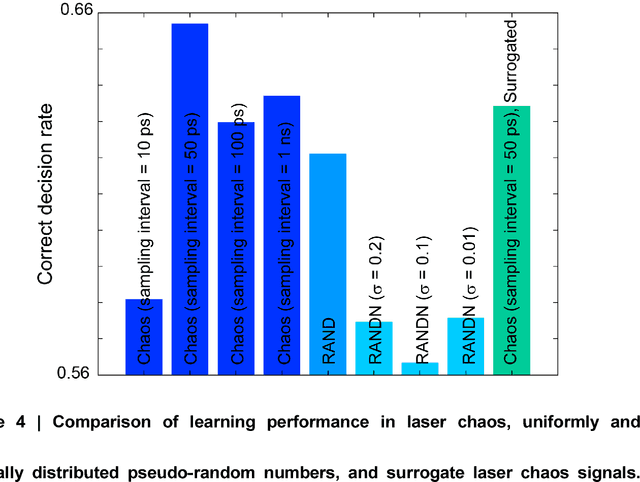
Reinforcement learning involves decision making in dynamic and uncertain environments, and constitutes one important element of artificial intelligence (AI). In this paper, we experimentally demonstrate that the ultrafast chaotic oscillatory dynamics of lasers efficiently solve the multi-armed bandit problem (MAB), which requires decision making concerning a class of difficult trade-offs called the exploration-exploitation dilemma. To solve the MAB, a certain degree of randomness is required for exploration purposes. However, pseudo-random numbers generated using conventional electronic circuitry encounter severe limitations in terms of their data rate and the quality of randomness due to their algorithmic foundations. We generate laser chaos signals using a semiconductor laser sampled at a maximum rate of 100 GSample/s, and combine it with a simple decision-making principle called tug-of-war with a variable threshold, to ensure ultrafast, adaptive and accurate decision making at a maximum adaptation speed of 1 GHz. We found that decision-making performance was maximized with an optimal sampling interval, and we highlight the exact coincidence between the negative autocorrelation inherent in laser chaos and decision-making performance. This study paves the way for a new realm of ultrafast photonics in the age of AI, where the ultrahigh bandwidth of photons can provide new value.
Single photon in hierarchical architecture for physical reinforcement learning: Photon intelligence
Sep 01, 2016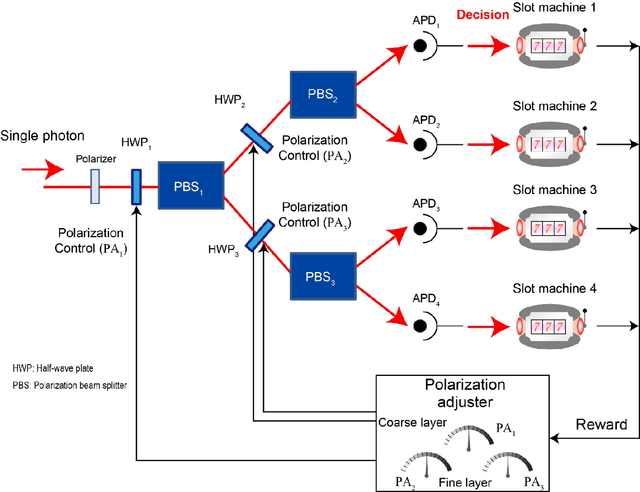



Understanding and using natural processes for intelligent functionalities, referred to as natural intelligence, has recently attracted interest from a variety of fields, including post-silicon computing for artificial intelligence and decision making in the behavioural sciences. In a past study, we successfully used the wave-particle duality of single photons to solve the two-armed bandit problem, which constitutes the foundation of reinforcement learning and decision making. In this study, we propose and confirm a hierarchical architecture for single-photon-based reinforcement learning and decision making that verifies the scalability of the principle. Specifically, the four-armed bandit problem is solved given zero prior knowledge in a two-layer hierarchical architecture, where polarization is autonomously adapted in order to effect adequate decision making using single-photon measurements. In the hierarchical structure, the notion of layer-dependent decisions emerges. The optimal solutions in the coarse layer and in the fine layer, however, conflict with each other in some contradictive problems. We show that while what we call a tournament strategy resolves such contradictions, the probabilistic nature of single photons allows for the direct location of the optimal solution even for contradictive problems, hence manifesting the exploration ability of single photons. This study provides insights into photon intelligence in hierarchical architectures for future artificial intelligence as well as the potential of natural processes for intelligent functionalities.
Decision Maker based on Atomic Switches
Jul 21, 2015



We propose a simple model for an atomic switch-based decision maker (ASDM), and show that, as long as its total volume of precipitated Ag atoms is conserved when coupled with suitable operations, an atomic switch system provides a sophisticated "decision-making" capability that is known to be one of the most important intellectual abilities in human beings. We considered the multi-armed bandit problem (MAB); the problem of finding, as accurately and quickly as possible, the most profitable option from a set of options that gives stochastic rewards. These decisions are made as dictated by each volume of precipitated Ag atoms, which is moved in a manner similar to the fluctuations of a rigid body in a tug-of-war game. The "tug-of-war (TOW) dynamics" of the ASDM exhibits higher efficiency than conventional MAB solvers. We show analytical calculations that validate the statistical reasons for the ASDM dynamics to produce such high performance, despite its simplicity. These results imply that various physical systems, in which some conservation law holds, can be used to implement efficient "decision-making objects." Efficient MAB solvers are useful for many practical applications, because MAB abstracts a variety of decision-making problems in real- world situations where an efficient trial-and-error is required. The proposed scheme will introduce a new physics-based analog computing paradigm, which will include such things as "intelligent nano devices" and "intelligent information networks" based on self-detection and self-judgment.
Harnessing Natural Fluctuations: Analogue Computer for Efficient Socially Maximal Decision Making
Apr 14, 2015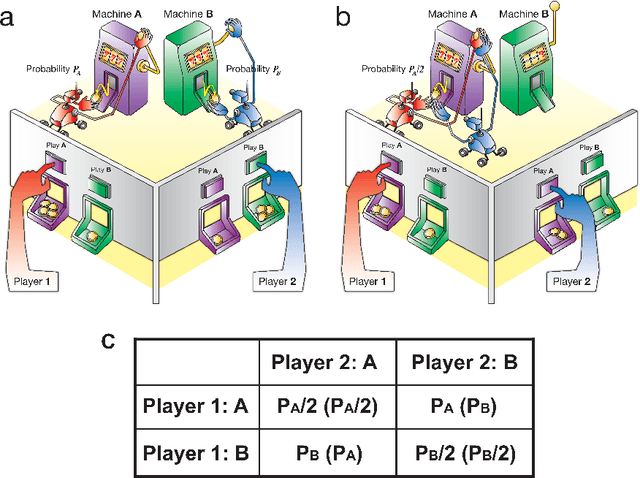

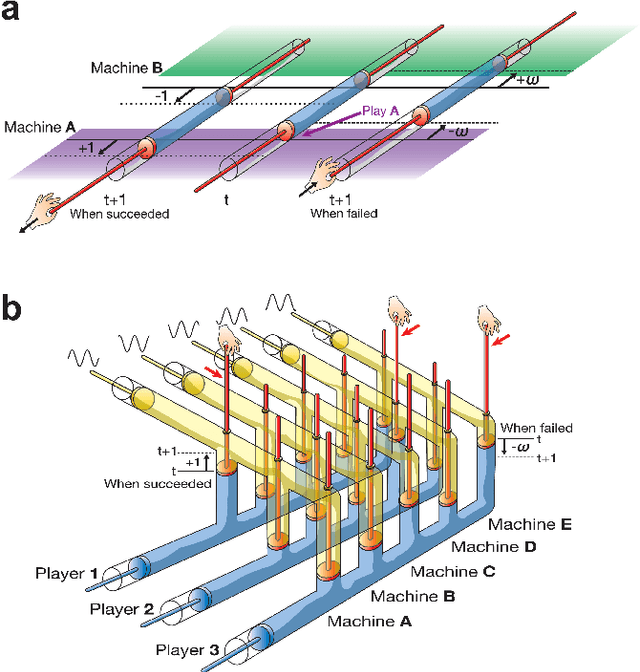

Each individual handles many tasks of finding the most profitable option from a set of options that stochastically provide rewards. Our society comprises a collection of such individuals, and the society is expected to maximise the total rewards, while the individuals compete for common rewards. Such collective decision making is formulated as the `competitive multi-armed bandit problem (CBP)', requiring a huge computational cost. Herein, we demonstrate a prototype of an analog computer that efficiently solves CBPs by exploiting the physical dynamics of numerous fluids in coupled cylinders. This device enables the maximisation of the total rewards for the society without paying the conventionally required computational cost; this is because the fluids estimate the reward probabilities of the options for the exploitation of past knowledge and generate random fluctuations for the exploration of new knowledge. Our results suggest that to optimise the social rewards, the utilisation of fluid-derived natural fluctuations is more advantageous than applying artificial external fluctuations. Our analog computing scheme is expected to trigger further studies for harnessing the huge computational power of natural phenomena for resolving a wide variety of complex problems in modern information society.
Decision Maker using Coupled Incompressible-Fluid Cylinders
Feb 13, 2015

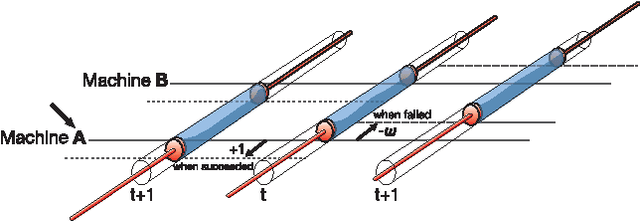

The multi-armed bandit problem (MBP) is the problem of finding, as accurately and quickly as possible, the most profitable option from a set of options that gives stochastic rewards by referring to past experiences. Inspired by fluctuated movements of a rigid body in a tug-of-war game, we formulated a unique search algorithm that we call the `tug-of-war (TOW) dynamics' for solving the MBP efficiently. The cognitive medium access, which refers to multi-user channel allocations in cognitive radio, can be interpreted as the competitive multi-armed bandit problem (CMBP); the problem is to determine the optimal strategy for allocating channels to users which yields maximum total rewards gained by all users. Here we show that it is possible to construct a physical device for solving the CMBP, which we call the `TOW Bombe', by exploiting the TOW dynamics existed in coupled incompressible-fluid cylinders. This analog computing device achieves the `socially-maximum' resource allocation that maximizes the total rewards in cognitive medium access without paying a huge computational cost that grows exponentially as a function of the problem size.
Efficient Decision-Making by Volume-Conserving Physical Object
Oct 30, 2014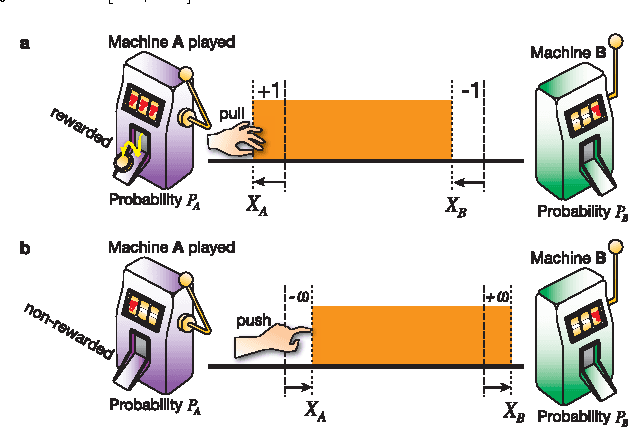
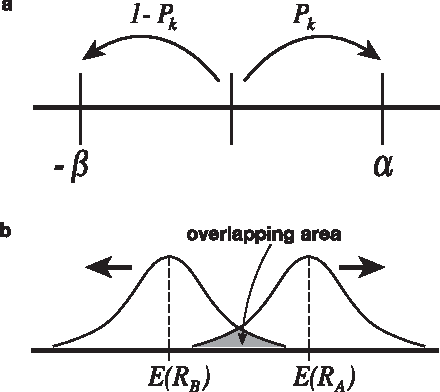
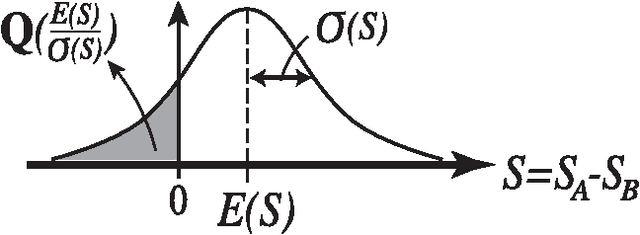
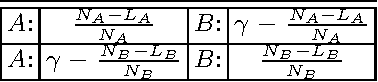
We demonstrate that any physical object, as long as its volume is conserved when coupled with suitable operations, provides a sophisticated decision-making capability. We consider the problem of finding, as accurately and quickly as possible, the most profitable option from a set of options that gives stochastic rewards. These decisions are made as dictated by a physical object, which is moved in a manner similar to the fluctuations of a rigid body in a tug-of-war game. Our analytical calculations validate statistical reasons why our method exhibits higher efficiency than conventional algorithms.