 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAE MobiLLM: Privacy-Aware and Efficient LLM Fine-Tuning on the Mobile Device via Additive Side-Tuning
Jul 01, 2025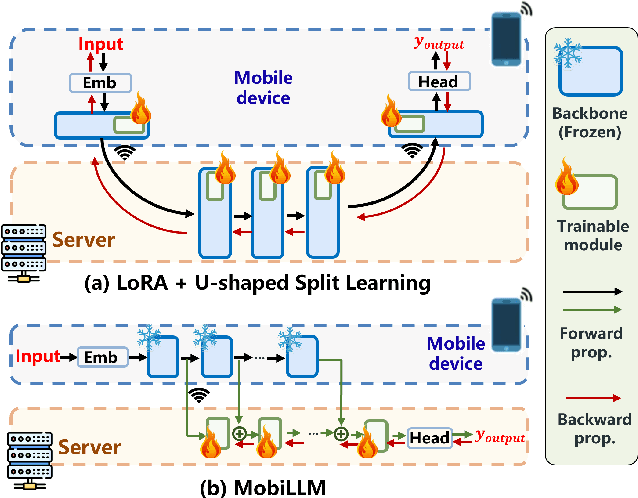
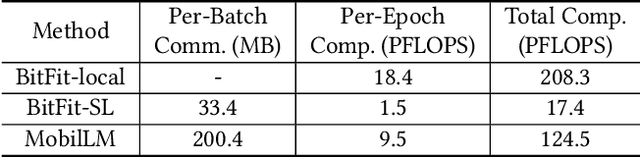
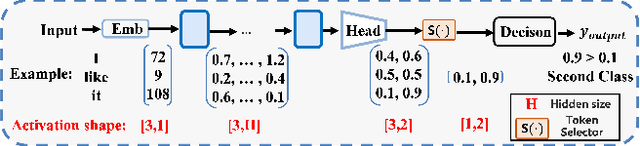
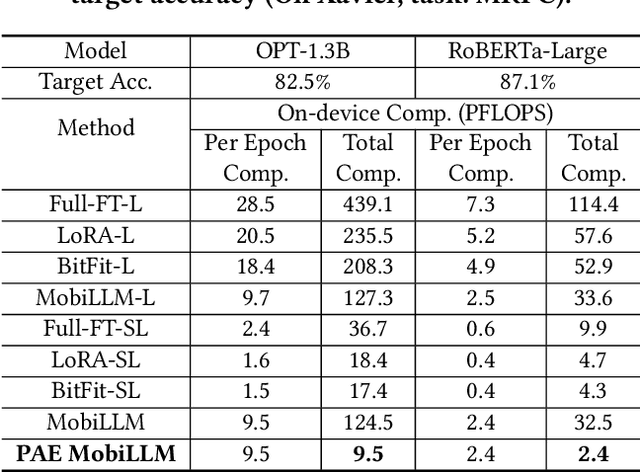
There is a huge gap between numerous intriguing applications fostered by on-device large language model (LLM) fine-tuning (FT) from fresh mobile data and the limited resources of a mobile device. While existing server-assisted methods (e.g., split learning or side-tuning) may enable LLM FT on the local mobile device, they suffer from heavy communication burdens of activation transmissions, and may disclose data, labels or fine-tuned models to the server. To address those issues, we develop PAE MobiLLM, a privacy-aware and efficient LLM FT method which can be deployed on the mobile device via server-assisted additive side-tuning. To further accelerate FT convergence and improve computing efficiency, PAE MobiLLM integrates activation caching on the server side, which allows the server to reuse historical activations and saves the mobile device from repeatedly computing forward passes for the recurring data samples. Besides, to reduce communication cost, PAE MobiLLM develops a one-token (i.e., ``pivot'' token) activation shortcut that transmits only a single activation dimension instead of full activation matrices to guide the side network tuning. Last but not least, PAE MobiLLM introduces the additive adapter side-network design which makes the server train the adapter modules based on device-defined prediction differences rather than raw ground-truth labels. In this way, the server can only assist device-defined side-network computing, and learn nothing about data, labels or fine-tuned models.
MobiLLM: Enabling LLM Fine-Tuning on the Mobile Device via Server Assisted Side Tuning
Feb 27, 2025
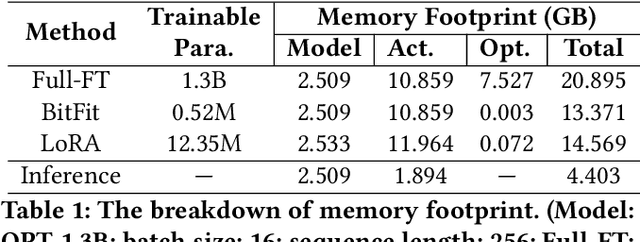
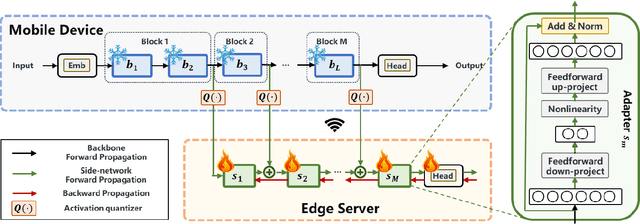
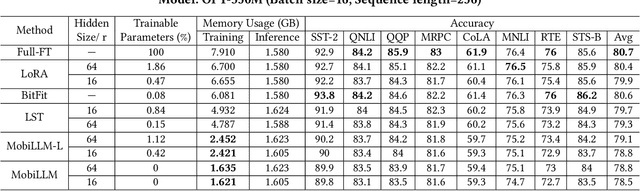
Large Language Model (LLM) at mobile devices and its potential applications never fail to fascinate. However, on-device LLM fine-tuning poses great challenges due to extremely high memory requirements and slow training speeds. Even with parameter-efficient fine-tuning (PEFT) methods that update only a small subset of parameters, resource-constrained mobile devices cannot afford them. In this paper, we propose MobiLLM to enable memory-efficient transformer LLM fine-tuning on a mobile device via server-assisted side-tuning. Particularly, MobiLLM allows the resource-constrained mobile device to retain merely a frozen backbone model, while offloading the memory and computation-intensive backpropagation of a trainable side-network to a high-performance server. Unlike existing fine-tuning methods that keep trainable parameters inside the frozen backbone, MobiLLM separates a set of parallel adapters from the backbone to create a backpropagation bypass, involving only one-way activation transfers from the mobile device to the server with low-width quantization during forward propagation. In this way, the data never leaves the mobile device while the device can remove backpropagation through the local backbone model and its forward propagation can be paralyzed with the server-side execution. Thus, MobiLLM preserves data privacy while significantly reducing the memory and computational burdens for LLM fine-tuning. Through extensive experiments, we demonstrate that MobiLLM can enable a resource-constrained mobile device, even a CPU-only one, to fine-tune LLMs and significantly reduce convergence time and memory usage.
Energy Efficient Transmission Parameters Selection Method Using Reinforcement Learning in Distributed LoRa Networks
Oct 15, 2024



With the increase in demand for Internet of Things (IoT) applications, the number of IoT devices has drastically grown, making spectrum resources seriously insufficient. Transmission collisions and retransmissions increase power consumption. Therefore, even in long-range (LoRa) networks, selecting appropriate transmission parameters, such as channel and transmission power, is essential to improve energy efficiency. However, due to the limited computational ability and memory, traditional transmission parameter selection methods for LoRa networks are challenging to implement on LoRa devices. To solve this problem, a distributed reinforcement learning-based channel and transmission power selection method is proposed, which can be implemented on the LoRa devices to improve energy efficiency in this paper. Specifically, the channel and transmission power selection problem in LoRa networks is first mapped to the multi-armed-bandit (MAB) problem. Then, an MAB-based method is introduced to solve the formulated transmission parameter selection problem based on the acknowledgment (ACK) packet and the power consumption for data transmission of the LoRa device. The performance of the proposed method is evaluated by the constructed actual LoRa network. Experimental results show that the proposed method performs better than fixed assignment, adaptive data rate low-complexity (ADR-Lite), and $\epsilon$-greedy-based methods in terms of both transmission success rate and energy efficiency.
Deep Learning and Image Super-Resolution-Guided Beam and Power Allocation for mmWave Networks
May 08, 2023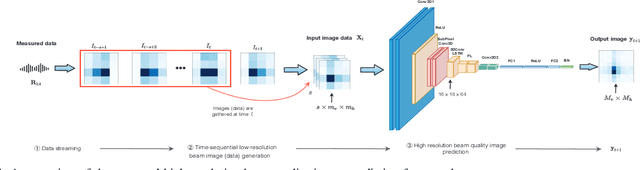
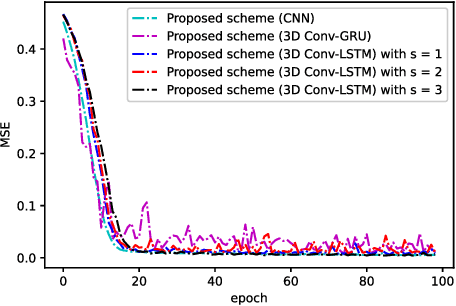
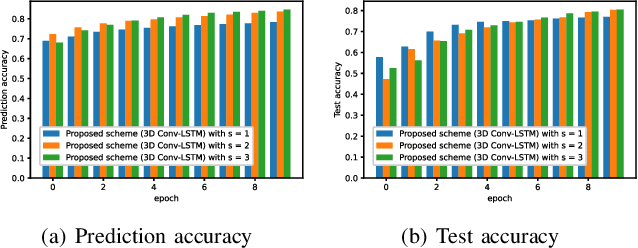
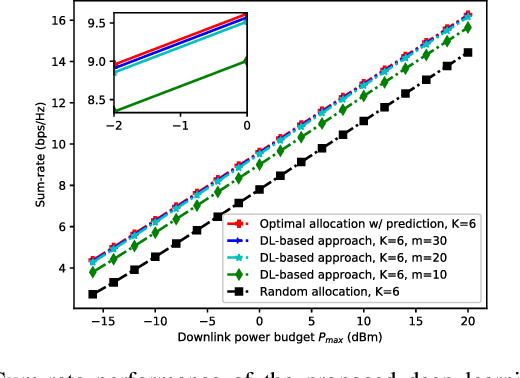
In this paper, we develop a deep learning (DL)-guided hybrid beam and power allocation approach for multiuser millimeter-wave (mmWave) networks, which facilitates swift beamforming at the base station (BS). The following persisting challenges motivated our research: (i) User and vehicular mobility, as well as redundant beam-reselections in mmWave networks, degrade the efficiency; (ii) Due to the large beamforming dimension at the BS, the beamforming weights predicted by the cutting-edge DL-based methods often do not suit the channel distributions; (iii) Co-located user devices may cause a severe beam conflict, thus deteriorating system performance. To address the aforementioned challenges, we exploit the synergy of supervised learning and super-resolution technology to enable low-overhead beam- and power allocation. In the first step, we propose a method for beam-quality prediction. It is based on deep learning and explores the relationship between high- and low-resolution beam images (energy). Afterward, we develop a DL-based allocation approach, which enables high-accuracy beam and power allocation with only a portion of the available time-sequential low-resolution images. Theoretical and numerical results verify the effectiveness of our proposed