 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAE MobiLLM: Privacy-Aware and Efficient LLM Fine-Tuning on the Mobile Device via Additive Side-Tuning
Jul 01, 2025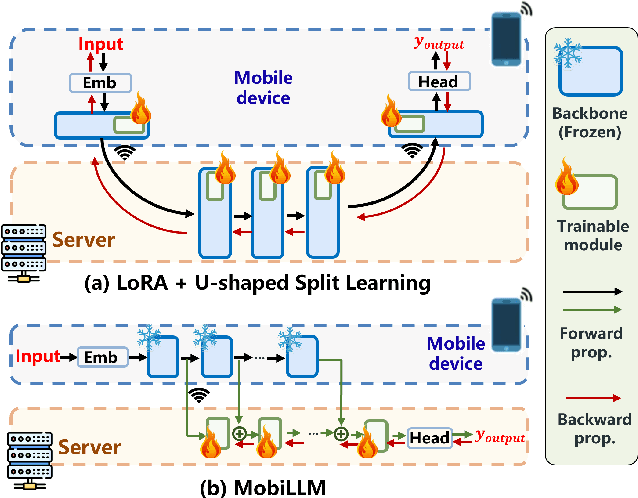
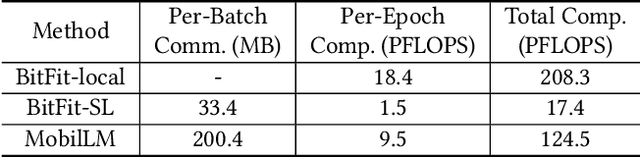
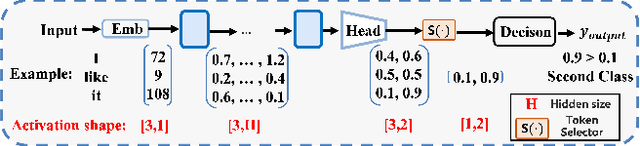
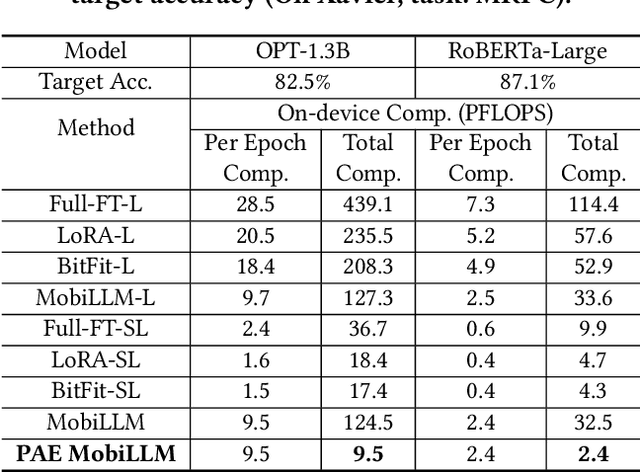
There is a huge gap between numerous intriguing applications fostered by on-device large language model (LLM) fine-tuning (FT) from fresh mobile data and the limited resources of a mobile device. While existing server-assisted methods (e.g., split learning or side-tuning) may enable LLM FT on the local mobile device, they suffer from heavy communication burdens of activation transmissions, and may disclose data, labels or fine-tuned models to the server. To address those issues, we develop PAE MobiLLM, a privacy-aware and efficient LLM FT method which can be deployed on the mobile device via server-assisted additive side-tuning. To further accelerate FT convergence and improve computing efficiency, PAE MobiLLM integrates activation caching on the server side, which allows the server to reuse historical activations and saves the mobile device from repeatedly computing forward passes for the recurring data samples. Besides, to reduce communication cost, PAE MobiLLM develops a one-token (i.e., ``pivot'' token) activation shortcut that transmits only a single activation dimension instead of full activation matrices to guide the side network tuning. Last but not least, PAE MobiLLM introduces the additive adapter side-network design which makes the server train the adapter modules based on device-defined prediction differences rather than raw ground-truth labels. In this way, the server can only assist device-defined side-network computing, and learn nothing about data, labels or fine-tuned models.
MobiLLM: Enabling LLM Fine-Tuning on the Mobile Device via Server Assisted Side Tuning
Feb 27, 2025
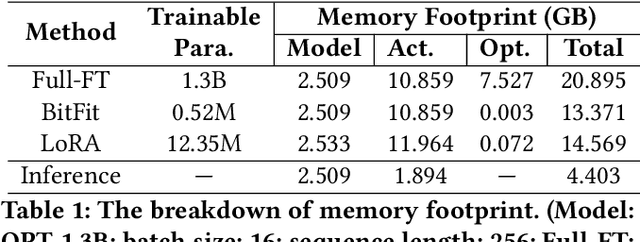
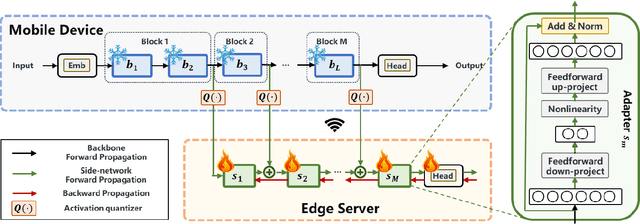
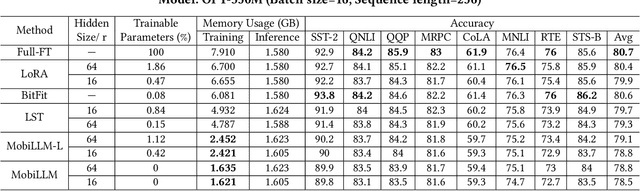
Large Language Model (LLM) at mobile devices and its potential applications never fail to fascinate. However, on-device LLM fine-tuning poses great challenges due to extremely high memory requirements and slow training speeds. Even with parameter-efficient fine-tuning (PEFT) methods that update only a small subset of parameters, resource-constrained mobile devices cannot afford them. In this paper, we propose MobiLLM to enable memory-efficient transformer LLM fine-tuning on a mobile device via server-assisted side-tuning. Particularly, MobiLLM allows the resource-constrained mobile device to retain merely a frozen backbone model, while offloading the memory and computation-intensive backpropagation of a trainable side-network to a high-performance server. Unlike existing fine-tuning methods that keep trainable parameters inside the frozen backbone, MobiLLM separates a set of parallel adapters from the backbone to create a backpropagation bypass, involving only one-way activation transfers from the mobile device to the server with low-width quantization during forward propagation. In this way, the data never leaves the mobile device while the device can remove backpropagation through the local backbone model and its forward propagation can be paralyzed with the server-side execution. Thus, MobiLLM preserves data privacy while significantly reducing the memory and computational burdens for LLM fine-tuning. Through extensive experiments, we demonstrate that MobiLLM can enable a resource-constrained mobile device, even a CPU-only one, to fine-tune LLMs and significantly reduce convergence time and memory usage.