 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric leader-laggard cluster synchronization for collective decision-making with laser network
Dec 05, 2023Photonic accelerators have recently attracted soaring interest, harnessing the ultimate nature of light for information processing. Collective decision-making with a laser network, employing the chaotic and synchronous dynamics of optically interconnected lasers to address the competitive multi-armed bandit (CMAB) problem, is a highly compelling approach due to its scalability and experimental feasibility. We investigated essential network structures for collective decision-making through quantitative stability analysis. Moreover, we demonstrated the asymmetric preferences of players in the CMAB problem, extending its functionality to more practical applications. Our study highlights the capability and significance of machine learning built upon chaotic lasers and photonic devices.
Conflict-free joint decision by lag and zero-lag synchronization in laser network
Jul 28, 2023With the end of Moore's Law and the increasing demand for computing, photonic accelerators are garnering considerable attention. This is due to the physical characteristics of light, such as high bandwidth and multiplicity, and the various synchronization phenomena that emerge in the realm of laser physics. These factors come into play as computer performance approaches its limits. In this study, we explore the application of a laser network, acting as a photonic accelerator, to the competitive multi-armed bandit problem. In this context, conflict avoidance is key to maximizing environmental rewards. We experimentally demonstrate cooperative decision-making using zero-lag and lag synchronization within a network of four semiconductor lasers. Lag synchronization of chaos realizes effective decision-making and zero-delay synchronization is responsible for the realization of the collision avoidance function. We experimentally verified a low collision rate and high reward in a fundamental 2-player, 2-slot scenario, and showed the scalability of this system. This system architecture opens up new possibilities for intelligent functionalities in laser dynamics.
Bandit Algorithm Driven by a Classical Random Walk and a Quantum Walk
Apr 20, 2023Quantum walks (QWs) have the property that classical random walks (RWs) do not possess -- coexistence of linear spreading and localization -- and this property is utilized to implement various kinds of applications. This paper proposes a quantum-walk-based algorithm for multi-armed-bandit (MAB) problems by associating the two operations that make MAB problems difficult -- exploration and exploitation -- with these two behaviors of QWs. We show that this new policy based on the QWs realizes high performance compared with the corresponding RW-based one.
Bandit approach to conflict-free multi-agent Q-learning in view of photonic implementation
Dec 20, 2022Recently, extensive studies on photonic reinforcement learning to accelerate the process of calculation by exploiting the physical nature of light have been conducted. Previous studies utilized quantum interference of photons to achieve collective decision-making without choice conflicts when solving the competitive multi-armed bandit problem, a fundamental example of reinforcement learning. However, the bandit problem deals with a static environment where the agent's action does not influence the reward probabilities. This study aims to extend the conventional approach to a more general multi-agent reinforcement learning targeting the grid world problem. Unlike the conventional approach, the proposed scheme deals with a dynamic environment where the reward changes because of agents' actions. A successful photonic reinforcement learning scheme requires both a photonic system that contributes to the quality of learning and a suitable algorithm. This study proposes a novel learning algorithm, discontinuous bandit Q-learning, in view of a potential photonic implementation. Here, state-action pairs in the environment are regarded as slot machines in the context of the bandit problem and an updated amount of Q-value is regarded as the reward of the bandit problem. We perform numerical simulations to validate the effectiveness of the bandit algorithm. In addition, we propose a multi-agent architecture in which agents are indirectly connected through quantum interference of light and quantum principles ensure the conflict-free property of state-action pair selections among agents. We demonstrate that multi-agent reinforcement learning can be accelerated owing to conflict avoidance among multiple agents.
Parallel photonic accelerator for decision making using optical spatiotemporal chaos
Oct 12, 2022

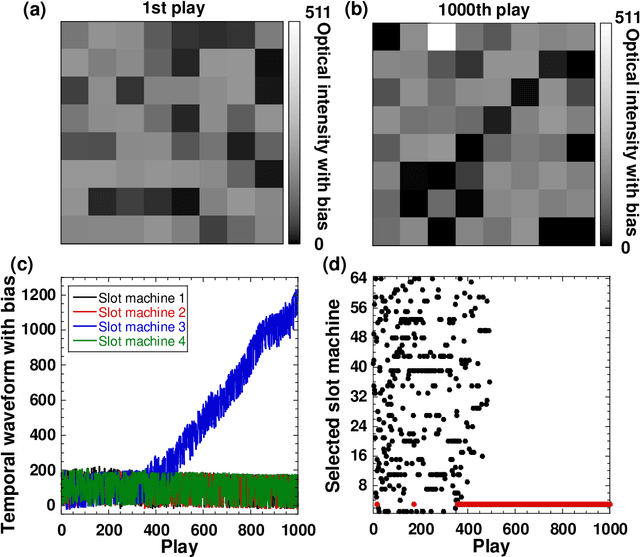
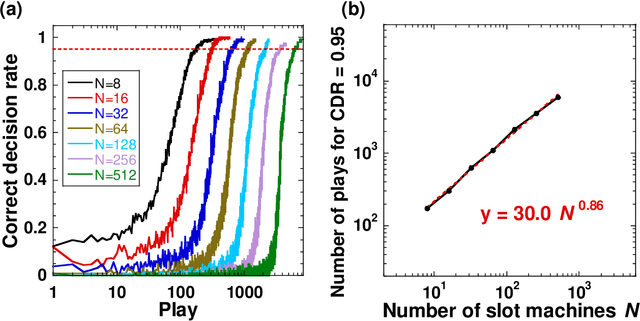
Photonic accelerators have attracted increasing attention in artificial intelligence applications. The multi-armed bandit problem is a fundamental problem of decision making using reinforcement learning. However, the scalability of photonic decision making has not yet been demonstrated in experiments, owing to technical difficulties in physical realization. We propose a parallel photonic decision-making system for solving large-scale multi-armed bandit problems using optical spatiotemporal chaos. We solve a 512-armed bandit problem online, which is much larger than previous experiments by two orders of magnitude. The scaling property for correct decision making is examined as a function of the number of slot machines, evaluated as an exponent of 0.86. This exponent is smaller than that in previous work, indicating the superiority of the proposed parallel principle. This experimental demonstration facilitates photonic decision making to solve large-scale multi-armed bandit problems for future photonic accelerators.
Conflict-free joint sampling for preference satisfaction through quantum interference
Aug 05, 2022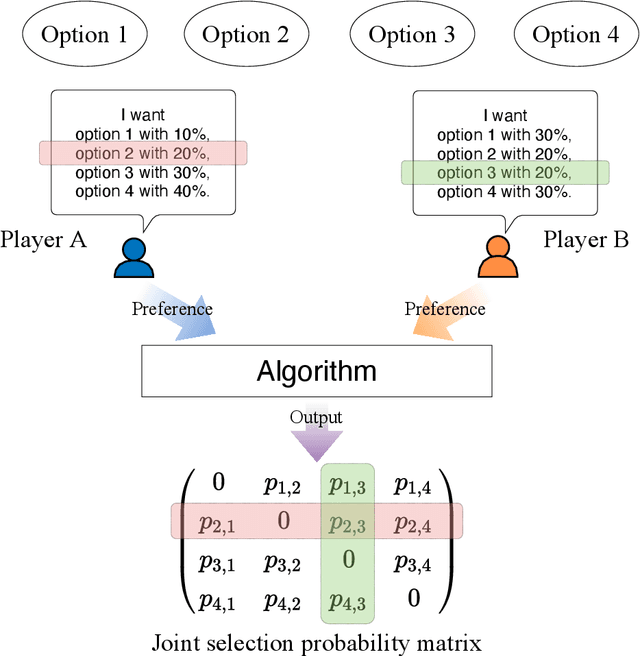
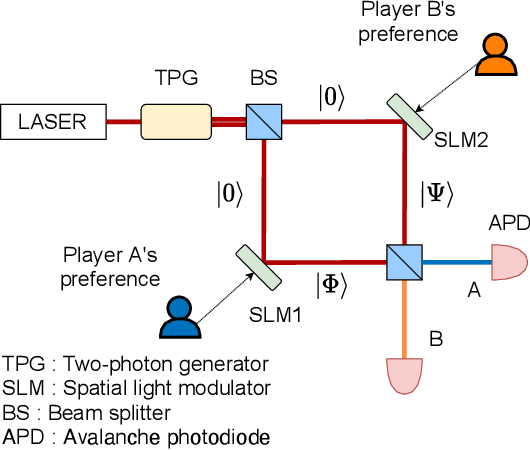
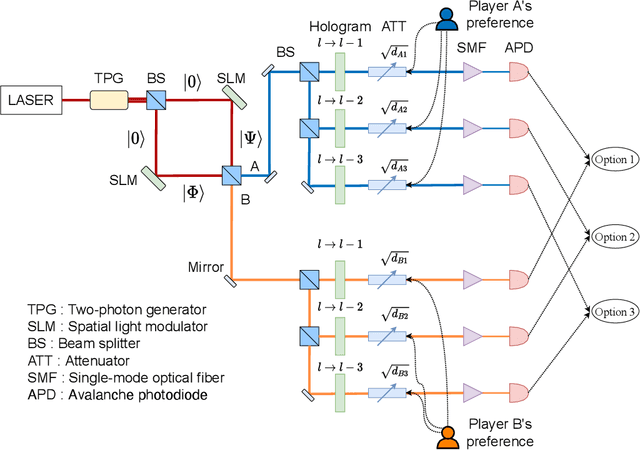
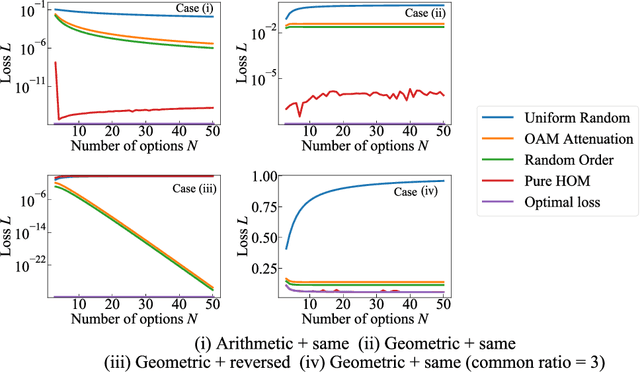
Collective decision-making is vital for recent information and communications technologies. In our previous research, we mathematically derived conflict-free joint decision-making that optimally satisfies players' probabilistic preference profiles. However, two problems exist regarding the optimal joint decision-making method. First, as the number of choices increases, the computational cost of calculating the optimal joint selection probability matrix explodes. Second, to derive the optimal joint selection probability matrix, all players must disclose their probabilistic preferences. Now, it is noteworthy that explicit calculation of the joint probability distribution is not necessarily needed; what is necessary for collective decisions is sampling. This study examines several sampling methods that converge to heuristic joint selection probability matrices that satisfy players' preferences. We show that they can significantly reduce the above problems of computational cost and confidentiality. We analyze the probability distribution each of the sampling methods converges to, as well as the computational cost required and the confidentiality secured. In particular, we introduce two conflict-free joint sampling methods through quantum interference of photons. The first system allows the players to hide their choices while satisfying the players' preferences almost perfectly when they have the same preferences. The second system, where the physical nature of light replaces the expensive computational cost, also conceals their choices under the assumption that they have a trusted third party.
Controlling chaotic itinerancy in laser dynamics for reinforcement learning
May 12, 2022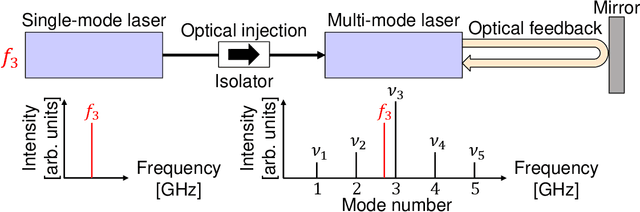
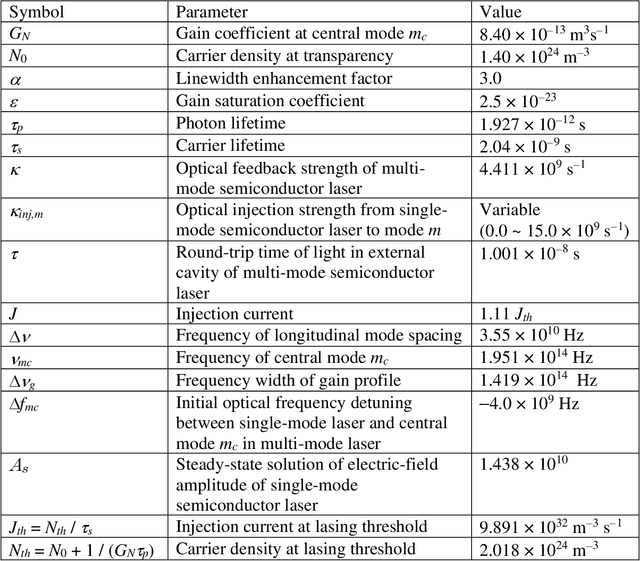
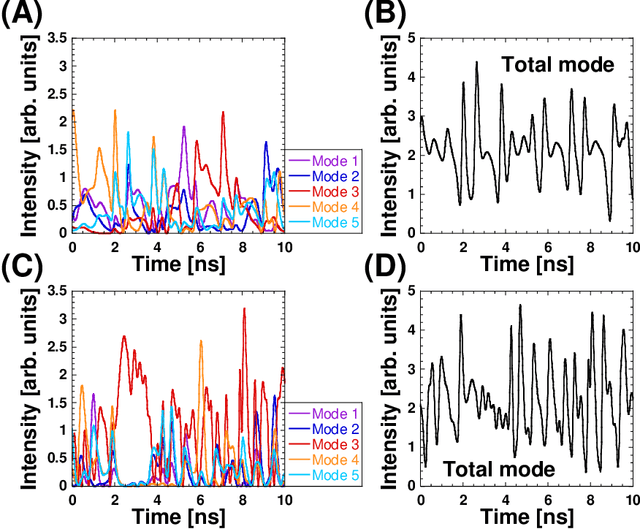
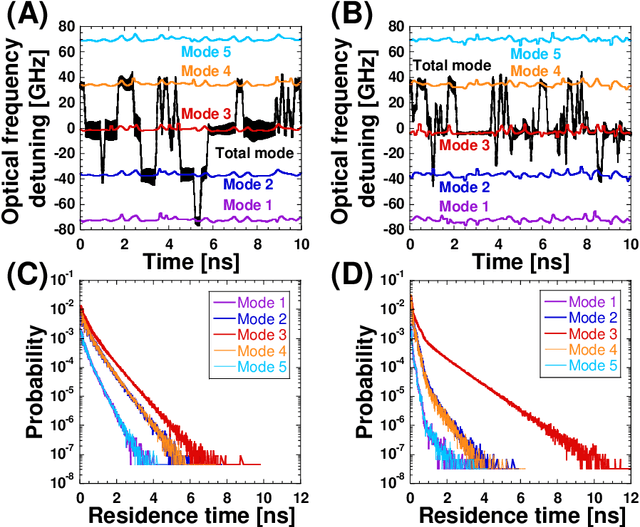
Photonic artificial intelligence has attracted considerable interest in accelerating machine learning; however, the unique optical properties have not been fully utilized for achieving higher-order functionalities. Chaotic itinerancy, with its spontaneous transient dynamics among multiple quasi-attractors, can be employed to realize brain-like functionalities. In this paper, we propose a method for controlling the chaotic itinerancy in a multi-mode semiconductor laser to solve a machine learning task, known as the multi-armed bandit problem, which is fundamental to reinforcement learning. The proposed method utilizes ultrafast chaotic itinerant motion in mode competition dynamics controlled via optical injection. We found that the exploration mechanism is completely different from a conventional searching algorithm and is highly scalable, outperforming the conventional approaches for large-scale bandit problems. This study paves the way to utilize chaotic itinerancy for effectively solving complex machine learning tasks as photonic hardware accelerators.
Scalable photonic reinforcement learning by time-division multiplexing of laser chaos
Mar 26, 2018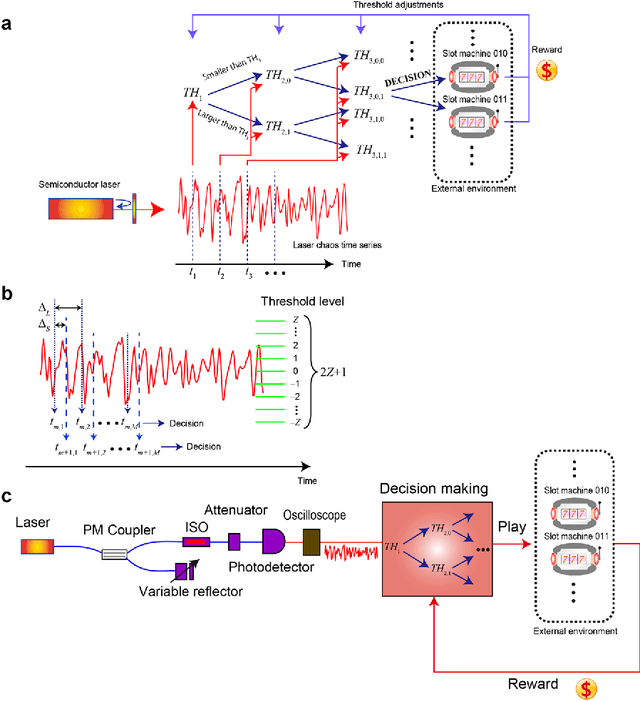

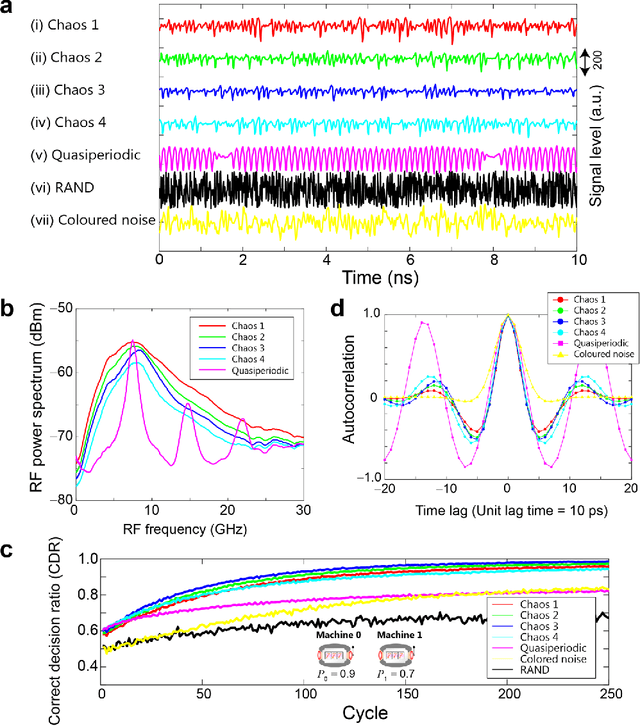
Reinforcement learning involves decision making in dynamic and uncertain environments and constitutes a crucial element of artificial intelligence. In our previous work, we experimentally demonstrated that the ultrafast chaotic oscillatory dynamics of lasers can be used to solve the two-armed bandit problem efficiently, which requires decision making concerning a class of difficult trade-offs called the exploration-exploitation dilemma. However, only two selections were employed in that research; thus, the scalability of the laser-chaos-based reinforcement learning should be clarified. In this study, we demonstrated a scalable, pipelined principle of resolving the multi-armed bandit problem by introducing time-division multiplexing of chaotically oscillated ultrafast time-series. The experimental demonstrations in which bandit problems with up to 64 arms were successfully solved are presented in this report. Detailed analyses are also provided that include performance comparisons among laser chaos signals generated in different physical conditions, which coincide with the diffusivity inherent in the time series. This study paves the way for ultrafast reinforcement learning by taking advantage of the ultrahigh bandwidths of light wave and practical enabling technologies.