 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlending Optimal Control and Biologically Plausible Learning for Noise-Robust Physical Neural Networks
Feb 26, 2025The rapidly increasing computational demands for artificial intelligence (AI) have spurred the exploration of computing principles beyond conventional digital computers. Physical neural networks (PNNs) offer efficient neuromorphic information processing by harnessing the innate computational power of physical processes; however, training their weight parameters is computationally expensive. We propose a training approach for substantially reducing this training cost. Our training approach merges an optimal control method for continuous-time dynamical systems with a biologically plausible training method--direct feedback alignment. In addition to the reduction of training time, this approach achieves robust processing even under measurement errors and noise without requiring detailed system information. The effectiveness was numerically and experimentally verified in an optoelectronic delay system. Our approach significantly extends the range of physical systems practically usable as PNNs.
* 28 pages, 10 figures
Asymmetric leader-laggard cluster synchronization for collective decision-making with laser network
Dec 05, 2023Photonic accelerators have recently attracted soaring interest, harnessing the ultimate nature of light for information processing. Collective decision-making with a laser network, employing the chaotic and synchronous dynamics of optically interconnected lasers to address the competitive multi-armed bandit (CMAB) problem, is a highly compelling approach due to its scalability and experimental feasibility. We investigated essential network structures for collective decision-making through quantitative stability analysis. Moreover, we demonstrated the asymmetric preferences of players in the CMAB problem, extending its functionality to more practical applications. Our study highlights the capability and significance of machine learning built upon chaotic lasers and photonic devices.
Asymmetric quantum decision-making
May 03, 2023Collective decision-making is crucial to information and communication systems. Decision conflicts among agents hinder the maximization of potential utilities of the entire system. Quantum processes can realize conflict-free joint decisions among two agents using the entanglement of photons or quantum interference of orbital angular momentum (OAM). However, previous studies have always presented symmetric resultant joint decisions. Although this property helps maintain and preserve equality, it cannot resolve disparities. Global challenges, such as ethics and equity, are recognized in the field of responsible artificial intelligence as responsible research and innovation paradigm. Thus, decision-making systems must not only preserve existing equality but also tackle disparities. This study theoretically and numerically investigates asymmetric collective decision-making using quantum interference of photons carrying OAM or entangled photons. Although asymmetry is successfully realized, a photon loss is inevitable in the proposed models. The available range of asymmetry and method for obtaining the desired degree of asymmetry are analytically formulated.
Bandit Algorithm Driven by a Classical Random Walk and a Quantum Walk
Apr 20, 2023Quantum walks (QWs) have the property that classical random walks (RWs) do not possess -- coexistence of linear spreading and localization -- and this property is utilized to implement various kinds of applications. This paper proposes a quantum-walk-based algorithm for multi-armed-bandit (MAB) problems by associating the two operations that make MAB problems difficult -- exploration and exploitation -- with these two behaviors of QWs. We show that this new policy based on the QWs realizes high performance compared with the corresponding RW-based one.
Bandit approach to conflict-free multi-agent Q-learning in view of photonic implementation
Dec 20, 2022Recently, extensive studies on photonic reinforcement learning to accelerate the process of calculation by exploiting the physical nature of light have been conducted. Previous studies utilized quantum interference of photons to achieve collective decision-making without choice conflicts when solving the competitive multi-armed bandit problem, a fundamental example of reinforcement learning. However, the bandit problem deals with a static environment where the agent's action does not influence the reward probabilities. This study aims to extend the conventional approach to a more general multi-agent reinforcement learning targeting the grid world problem. Unlike the conventional approach, the proposed scheme deals with a dynamic environment where the reward changes because of agents' actions. A successful photonic reinforcement learning scheme requires both a photonic system that contributes to the quality of learning and a suitable algorithm. This study proposes a novel learning algorithm, discontinuous bandit Q-learning, in view of a potential photonic implementation. Here, state-action pairs in the environment are regarded as slot machines in the context of the bandit problem and an updated amount of Q-value is regarded as the reward of the bandit problem. We perform numerical simulations to validate the effectiveness of the bandit algorithm. In addition, we propose a multi-agent architecture in which agents are indirectly connected through quantum interference of light and quantum principles ensure the conflict-free property of state-action pair selections among agents. We demonstrate that multi-agent reinforcement learning can be accelerated owing to conflict avoidance among multiple agents.
Conflict-free joint sampling for preference satisfaction through quantum interference
Aug 05, 2022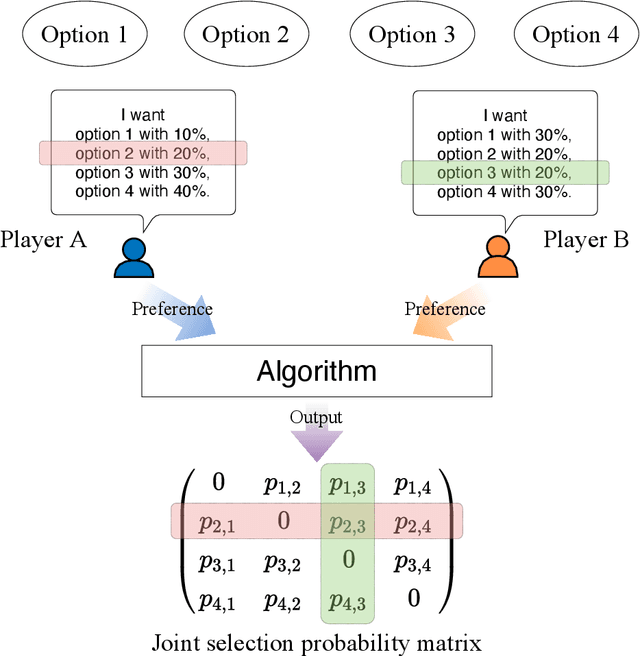
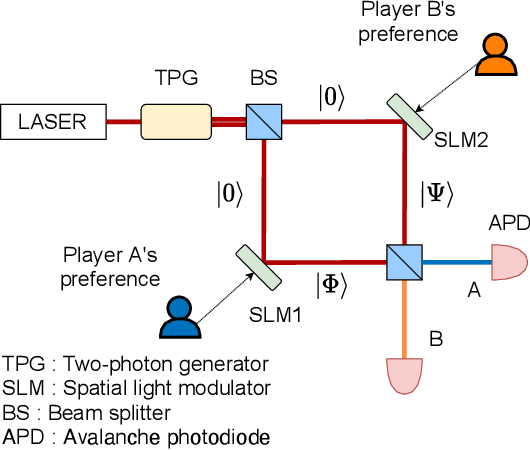
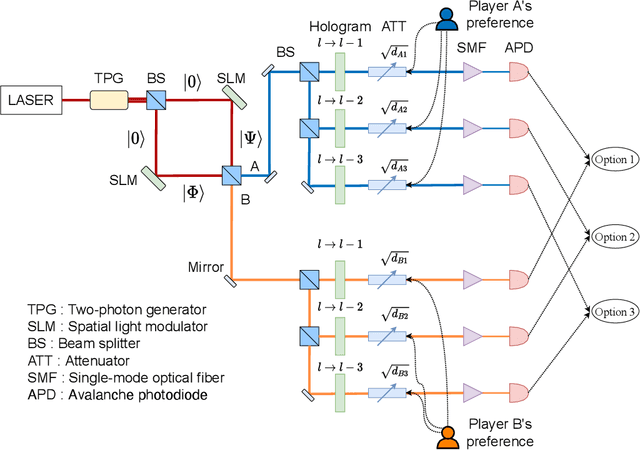
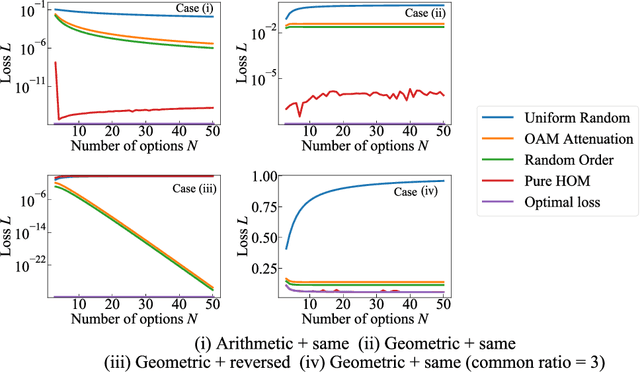
Collective decision-making is vital for recent information and communications technologies. In our previous research, we mathematically derived conflict-free joint decision-making that optimally satisfies players' probabilistic preference profiles. However, two problems exist regarding the optimal joint decision-making method. First, as the number of choices increases, the computational cost of calculating the optimal joint selection probability matrix explodes. Second, to derive the optimal joint selection probability matrix, all players must disclose their probabilistic preferences. Now, it is noteworthy that explicit calculation of the joint probability distribution is not necessarily needed; what is necessary for collective decisions is sampling. This study examines several sampling methods that converge to heuristic joint selection probability matrices that satisfy players' preferences. We show that they can significantly reduce the above problems of computational cost and confidentiality. We analyze the probability distribution each of the sampling methods converges to, as well as the computational cost required and the confidentiality secured. In particular, we introduce two conflict-free joint sampling methods through quantum interference of photons. The first system allows the players to hide their choices while satisfying the players' preferences almost perfectly when they have the same preferences. The second system, where the physical nature of light replaces the expensive computational cost, also conceals their choices under the assumption that they have a trusted third party.
Learning unseen coexisting attractors
Jul 28, 2022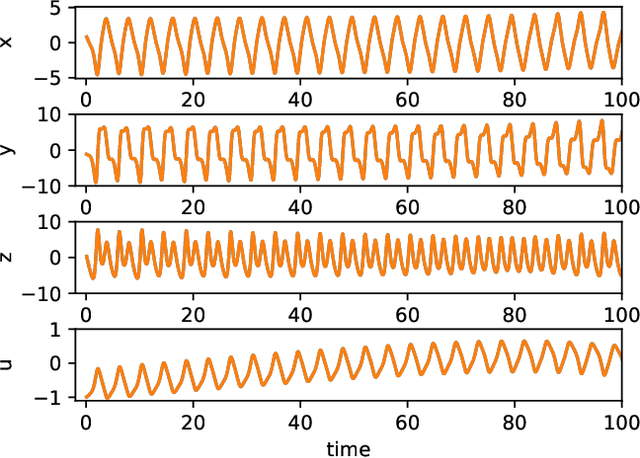
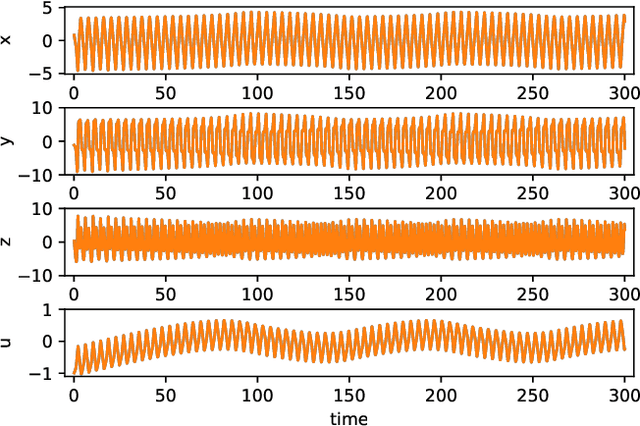

Reservoir computing is a machine learning approach that can generate a surrogate model of a dynamical system. It can learn the underlying dynamical system using fewer trainable parameters and hence smaller training data sets than competing approaches. Recently, a simpler formulation, known as next-generation reservoir computing, removes many algorithm metaparameters and identifies a well-performing traditional reservoir computer, thus simplifying training even further. Here, we study a particularly challenging problem of learning a dynamical system that has both disparate time scales and multiple co-existing dynamical states (attractors). We compare the next-generation and traditional reservoir computer using metrics quantifying the geometry of the ground-truth and forecasted attractors. For the studied four-dimensional system, the next-generation reservoir computing approach uses $\sim 1.7 \times$ less training data, requires $10^3 \times$ shorter `warm up' time, has fewer metaparameters, and has an $\sim 100\times$ higher accuracy in predicting the co-existing attractor characteristics in comparison to a traditional reservoir computer. Furthermore, we demonstrate that it predicts the basin of attraction with high accuracy. This work lends further support to the superior learning ability of this new machine learning algorithm for dynamical systems.
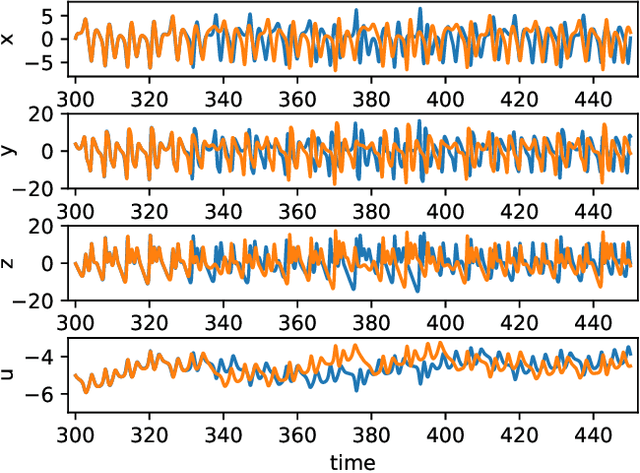
Model-free inference of unseen attractors: Reconstructing phase space features from a single noisy trajectory using reservoir computing
Aug 06, 2021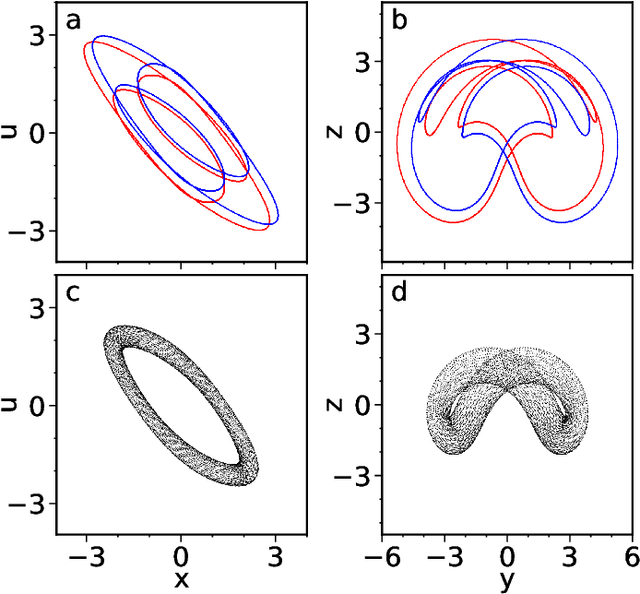
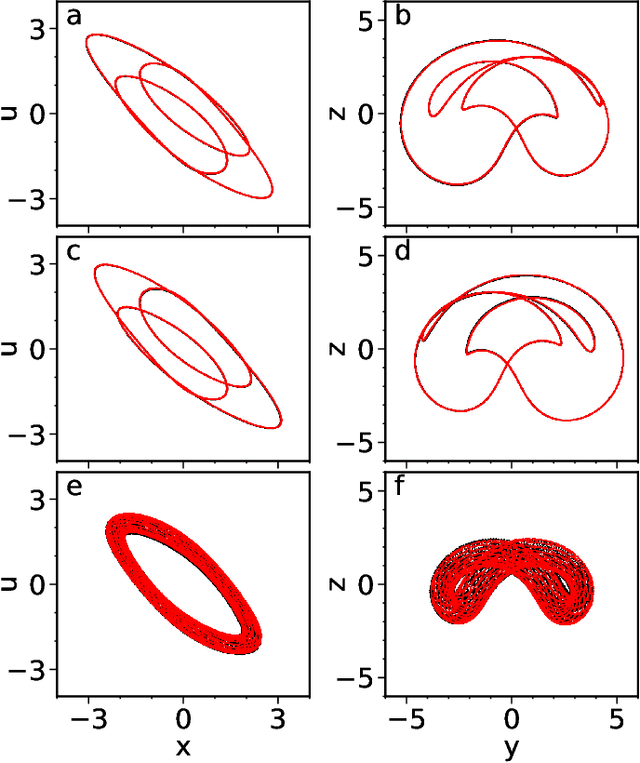
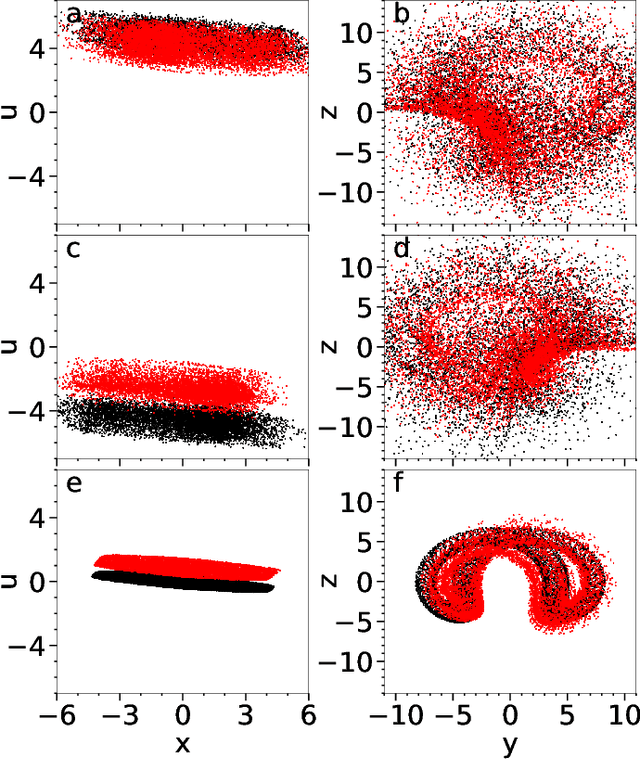
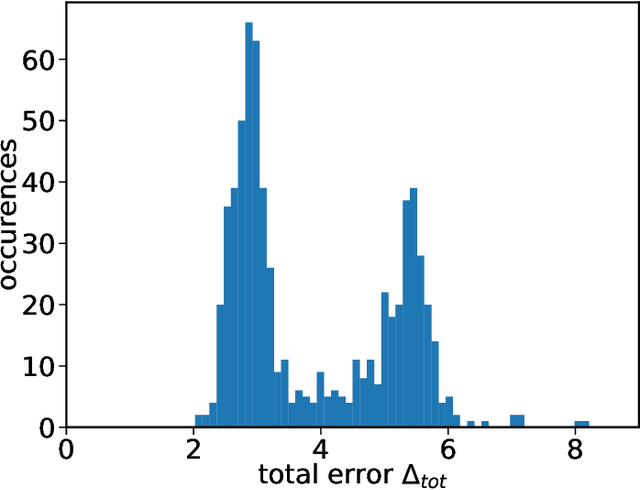
Reservoir computers are powerful tools for chaotic time series prediction. They can be trained to approximate phase space flows and can thus both predict future values to a high accuracy, as well as reconstruct the general properties of a chaotic attractor without requiring a model. In this work, we show that the ability to learn the dynamics of a complex system can be extended to systems with co-existing attractors, here a 4-dimensional extension of the well-known Lorenz chaotic system. We demonstrate that a reservoir computer can infer entirely unexplored parts of the phase space: a properly trained reservoir computer can predict the existence of attractors that were never approached during training and therefore are labelled as unseen. We provide examples where attractor inference is achieved after training solely on a single noisy trajectory.
Deep Learning with a Single Neuron: Folding a Deep Neural Network in Time using Feedback-Modulated Delay Loops
Nov 19, 2020
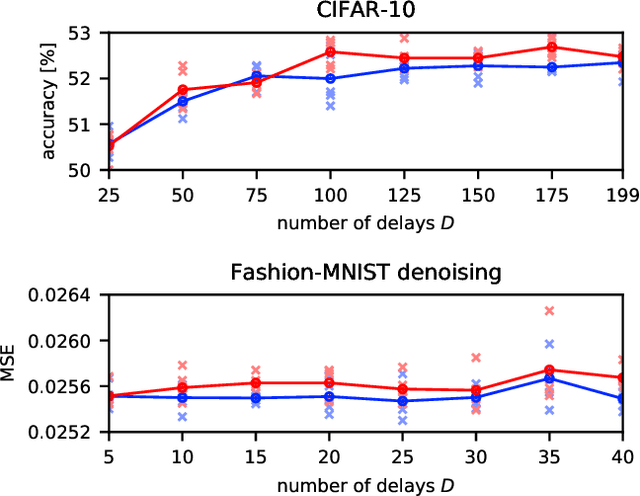
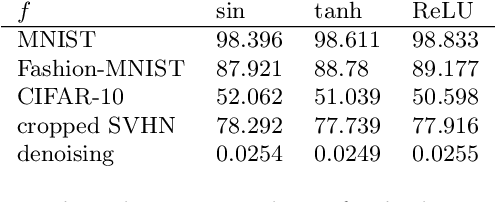
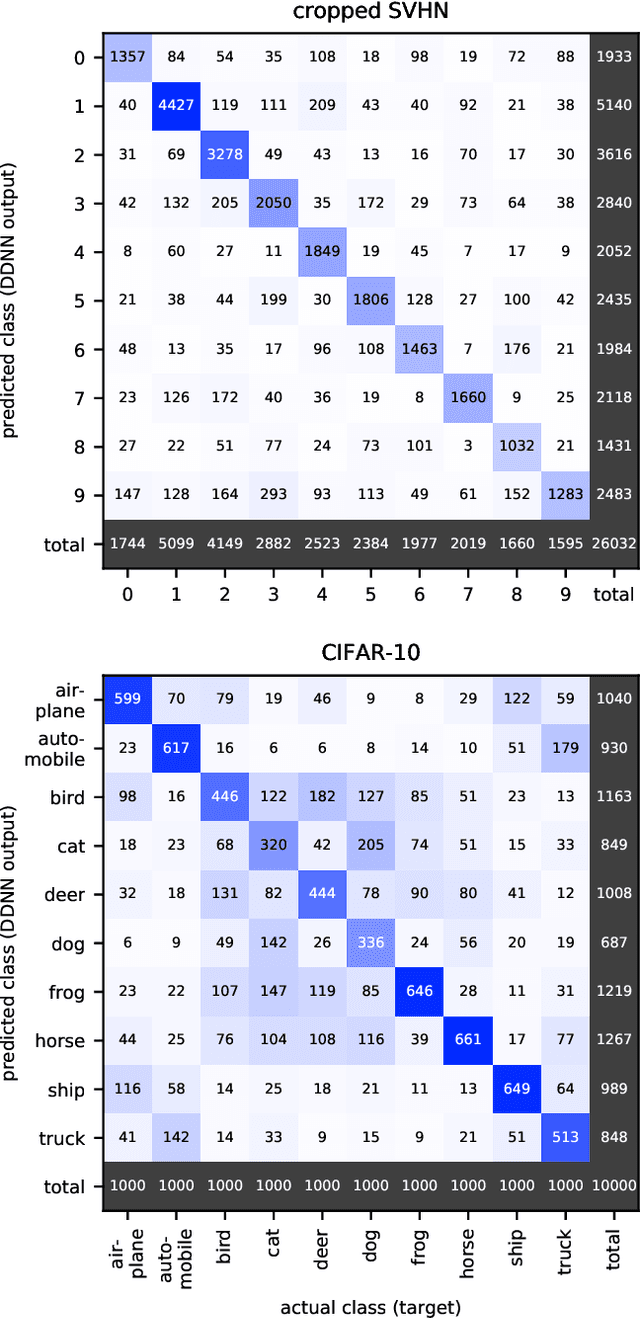
Deep neural networks are among the most widely applied machine learning tools showing outstanding performance in a broad range of tasks. We present a method for folding a deep neural network of arbitrary size into a single neuron with multiple time-delayed feedback loops. This single-neuron deep neural network comprises only a single nonlinearity and appropriately adjusted modulations of the feedback signals. The network states emerge in time as a temporal unfolding of the neuron's dynamics. By adjusting the feedback-modulation within the loops, we adapt the network's connection weights. These connection weights are determined via a modified back-propagation algorithm that we designed for such types of networks. Our approach fully recovers standard Deep Neural Networks (DNN), encompasses sparse DNNs, and extends the DNN concept toward dynamical systems implementations. The new method, which we call Folded-in-time DNN (Fit-DNN), exhibits promising performance in a set of benchmark tasks.
Performance boost of time-delay reservoir computing by non-resonant clock cycle
May 07, 2019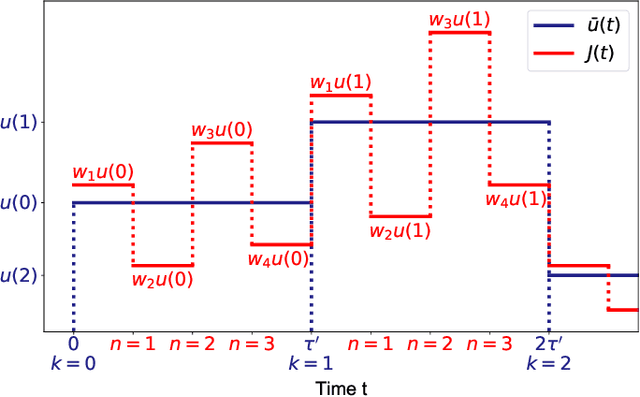

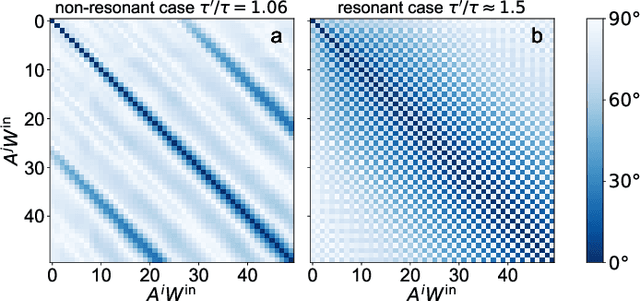

The time-delay-based reservoir computing setup has seen tremendous success in both experiment and simulation. It allows for the construction of large neuromorphic computing systems with only few components. However, until now the interplay of the different timescales has not been investigated thoroughly. In this manuscript, we investigate the effects of a mismatch between the time-delay and the clock cycle for a general model. Typically, these two time scales are considered to be equal. Here we show that the case of equal or rationally related time-delay and clock cycle could be actively detrimental and leads to an increase of the approximation error of the reservoir. In particular, we can show that non-resonant ratios of these time scales have maximal memory capacities. We achieve this by translating the periodically driven delay-dynamical system into an equivalent network. Networks that originate from a system with resonant delay-times and clock cycles fail to utilize all of their degrees of freedom, which causes the degradation of their performance.