 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboBrain 2.0 Technical Report
Jul 02, 2025We introduce RoboBrain 2.0, our latest generation of embodied vision-language foundation models, designed to unify perception, reasoning, and planning for complex embodied tasks in physical environments. It comes in two variants: a lightweight 7B model and a full-scale 32B model, featuring a heterogeneous architecture with a vision encoder and a language model. Despite its compact size, RoboBrain 2.0 achieves strong performance across a wide spectrum of embodied reasoning tasks. On both spatial and temporal benchmarks, the 32B variant achieves leading results, surpassing prior open-source and proprietary models. In particular, it supports key real-world embodied AI capabilities, including spatial understanding (e.g., affordance prediction, spatial referring, trajectory forecasting) and temporal decision-making (e.g., closed-loop interaction, multi-agent long-horizon planning, and scene graph updating). This report details the model architecture, data construction, multi-stage training strategies, infrastructure and practical applications. We hope RoboBrain 2.0 advances embodied AI research and serves as a practical step toward building generalist embodied agents. The code, checkpoint and benchmark are available at https://superrobobrain.github.io.
Tady: A Neural Disassembler without Structural Constraint Violations
Jun 16, 2025



Disassembly is a crucial yet challenging step in binary analysis. While emerging neural disassemblers show promise for efficiency and accuracy, they frequently generate outputs violating fundamental structural constraints, which significantly compromise their practical usability. To address this critical problem, we regularize the disassembly solution space by formalizing and applying key structural constraints based on post-dominance relations. This approach systematically detects widespread errors in existing neural disassemblers' outputs. These errors often originate from models' limited context modeling and instruction-level decoding that neglect global structural integrity. We introduce Tady, a novel neural disassembler featuring an improved model architecture and a dedicated post-processing algorithm, specifically engineered to address these deficiencies. Comprehensive evaluations on diverse binaries demonstrate that Tady effectively eliminates structural constraint violations and functions with high efficiency, while maintaining instruction-level accuracy.
DecompileBench: A Comprehensive Benchmark for Evaluating Decompilers in Real-World Scenarios
May 16, 2025Decompilers are fundamental tools for critical security tasks, from vulnerability discovery to malware analysis, yet their evaluation remains fragmented. Existing approaches primarily focus on syntactic correctness through synthetic micro-benchmarks or subjective human ratings, failing to address real-world requirements for semantic fidelity and analyst usability. We present DecompileBench, the first comprehensive framework that enables effective evaluation of decompilers in reverse engineering workflows through three key components: \textit{real-world function extraction} (comprising 23,400 functions from 130 real-world programs), \textit{runtime-aware validation}, and \textit{automated human-centric assessment} using LLM-as-Judge to quantify the effectiveness of decompilers in reverse engineering workflows. Through a systematic comparison between six industrial-strength decompilers and six recent LLM-powered approaches, we demonstrate that LLM-based methods surpass commercial tools in code understandability despite 52.2% lower functionality correctness. These findings highlight the potential of LLM-based approaches to transform human-centric reverse engineering. We open source \href{https://github.com/Jennieett/DecompileBench}{DecompileBench} to provide a framework to advance research on decompilers and assist security experts in making informed tool selections based on their specific requirements.
A Hybrid Quantum-Classical Autoencoder Framework for End-to-End Communication Systems
Dec 28, 2024
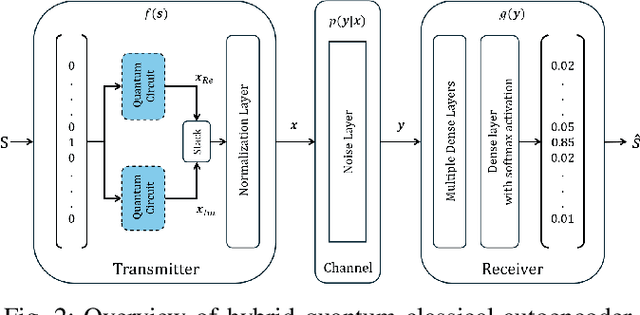
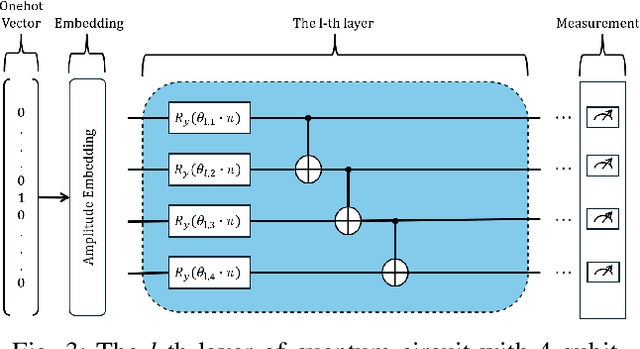
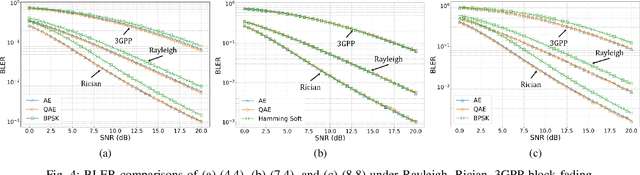
This paper investigates the application of quantum machine learning to End-to-End (E2E) communication systems in wireless fading scenarios. We introduce a novel hybrid quantum-classical autoencoder architecture that combines parameterized quantum circuits with classical deep neural networks (DNNs). Specifically, we propose a hybrid quantum-classical autoencoder (QAE) framework to optimize the E2E communication system. Our results demonstrate the feasibility of the proposed hybrid system, and reveal that it is the first work that can achieve comparable block error rate (BLER) performance to classical DNN-based and conventional channel coding schemes, while significantly reducing the number of trainable parameters. Additionally, the proposed QAE exhibits steady and superior BLER convergence over the classical autoencoder baseline.
Dynamic Spectrum Access for Ambient Backscatter Communication-assisted D2D Systems with Quantum Reinforcement Learning
Oct 23, 2024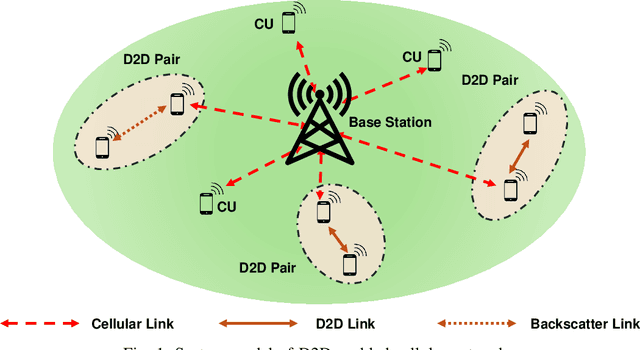
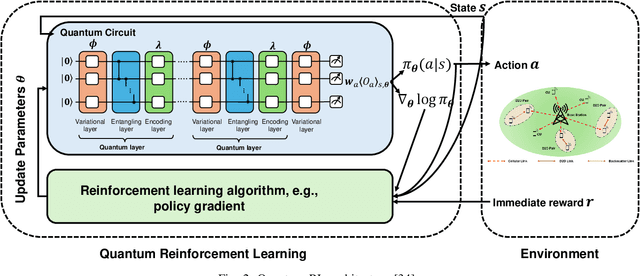
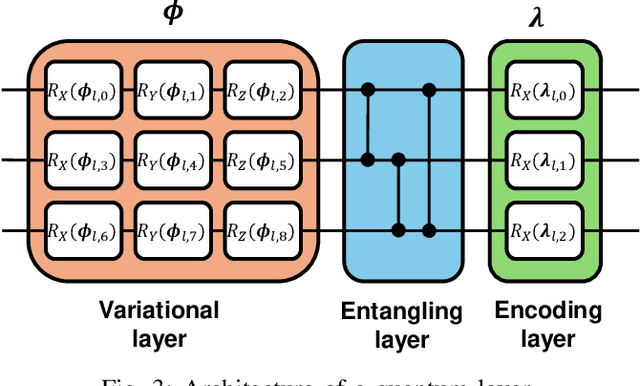
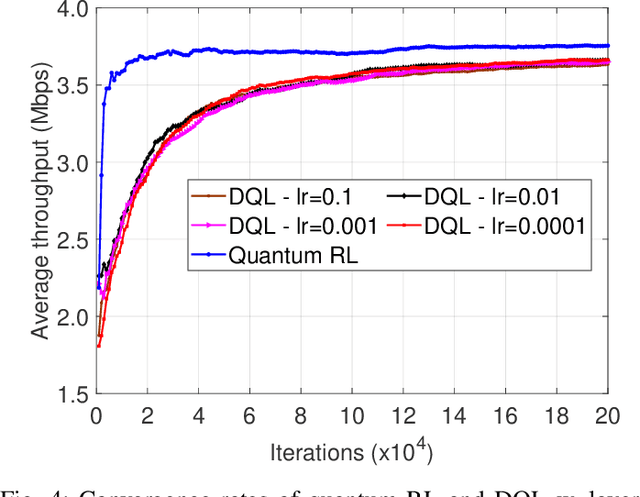
Spectrum access is an essential problem in device-to-device (D2D) communications. However, with the recent growth in the number of mobile devices, the wireless spectrum is becoming scarce, resulting in low spectral efficiency for D2D communications. To address this problem, this paper aims to integrate the ambient backscatter communication technology into D2D devices to allow them to backscatter ambient RF signals to transmit their data when the shared spectrum is occupied by mobile users. To obtain the optimal spectrum access policy, i.e., stay idle or access the shared spectrum and perform active transmissions or backscattering ambient RF signals for transmissions, to maximize the average throughput for D2D users, deep reinforcement learning (DRL) can be adopted. However, DRL-based solutions may require long training time due to the curse of dimensionality issue as well as complex deep neural network architectures. For that, we develop a novel quantum reinforcement learning (RL) algorithm that can achieve a faster convergence rate with fewer training parameters compared to DRL thanks to the quantum superposition and quantum entanglement principles. Specifically, instead of using conventional deep neural networks, the proposed quantum RL algorithm uses a parametrized quantum circuit to approximate an optimal policy. Extensive simulations then demonstrate that the proposed solution not only can significantly improve the average throughput of D2D devices when the shared spectrum is busy but also can achieve much better performance in terms of convergence rate and learning complexity compared to existing DRL-based methods.
Self-Alignment of Large Language Models via Monopolylogue-based Social Scene Simulation
Feb 08, 2024



Aligning large language models (LLMs) with human values is imperative to mitigate potential adverse effects resulting from their misuse. Drawing from the sociological insight that acknowledging all parties' concerns is a key factor in shaping human values, this paper proposes a novel direction to align LLMs by themselves: social scene simulation. To achieve this, we present MATRIX, a novel social scene simulator that emulates realistic scenes around a user's input query, enabling the LLM to take social consequences into account before responding. MATRIX serves as a virtual rehearsal space, akin to a Monopolylogue, where the LLM performs diverse roles related to the query and practice by itself. To inject this alignment, we fine-tune the LLM with MATRIX-simulated data, ensuring adherence to human values without compromising inference speed. We theoretically show that the LLM with MATRIX outperforms Constitutional AI under mild assumptions. Finally, extensive experiments validate that our method outperforms over 10 baselines across 4 benchmarks. As evidenced by 875 user ratings, our tuned 13B-size LLM exceeds GPT-4 in aligning with human values. Code is available at https://github.com/pangxianghe/MATRIX.
Deep Deterministic Policy Gradient for End-to-End Communication Systems without Prior Channel Knowledge
May 12, 2023



End-to-End (E2E) learning-based concept has been recently introduced to jointly optimize both the transmitter and the receiver in wireless communication systems. Unfortunately, this E2E learning architecture requires a prior differentiable channel model to jointly train the deep neural networks (DNNs) at the transceivers, which is hardly obtained in practice. This paper aims to solve this issue by developing a deep deterministic policy gradient (DDPG)-based framework. In particular, the proposed solution uses the loss value of the receiver DNN as the reward to train the transmitter DNN. The simulation results then show that our proposed solution can jointly train the transmitter and the receiver without requiring the prior channel model. In addition, we demonstrate that the proposed DDPG-based solution can achieve better detection performance compared to the state-of-the-art solutions.
Recognizing Orientation Slip in Human Demonstrations
Aug 10, 2021

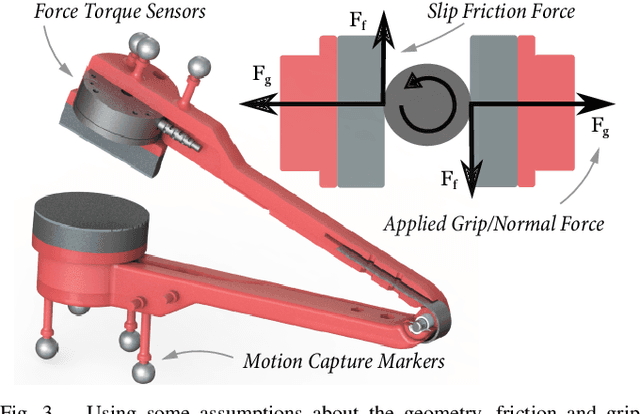
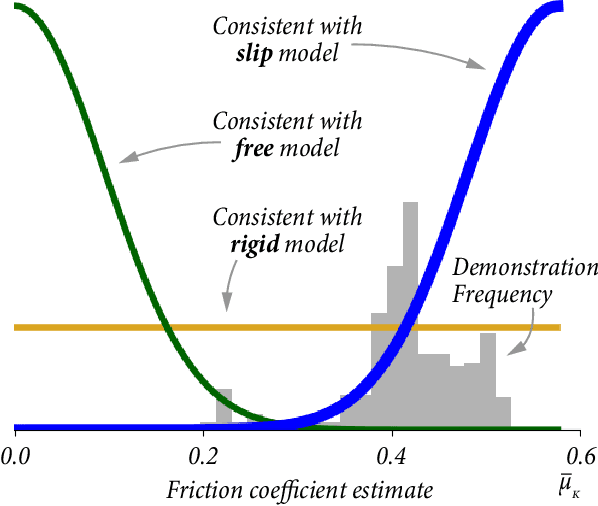
Manipulations of a constrained object often use a non-rigid grasp that allows the object to rotate relative to the end effector. This orientation slip strategy is often present in natural human demonstrations, yet it is generally overlooked in methods to identify constraints from such demonstrations. In this paper, we present a method to model and recognize prehensile orientation slip in human demonstrations of constrained interactions. Using only observations of an end effector, we can detect the type of constraint, parameters of the constraint, and orientation slip properties. Our method uses a novel hierarchical model selection method that is informed by multiple origins of physics-based evidence. A study with eight participants shows that orientation slip occurs in natural demonstrations and confirms that it can be detected by our method.