 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboBrain 2.0 Technical Report
Jul 02, 2025We introduce RoboBrain 2.0, our latest generation of embodied vision-language foundation models, designed to unify perception, reasoning, and planning for complex embodied tasks in physical environments. It comes in two variants: a lightweight 7B model and a full-scale 32B model, featuring a heterogeneous architecture with a vision encoder and a language model. Despite its compact size, RoboBrain 2.0 achieves strong performance across a wide spectrum of embodied reasoning tasks. On both spatial and temporal benchmarks, the 32B variant achieves leading results, surpassing prior open-source and proprietary models. In particular, it supports key real-world embodied AI capabilities, including spatial understanding (e.g., affordance prediction, spatial referring, trajectory forecasting) and temporal decision-making (e.g., closed-loop interaction, multi-agent long-horizon planning, and scene graph updating). This report details the model architecture, data construction, multi-stage training strategies, infrastructure and practical applications. We hope RoboBrain 2.0 advances embodied AI research and serves as a practical step toward building generalist embodied agents. The code, checkpoint and benchmark are available at https://superrobobrain.github.io.
Infinity-MM: Scaling Multimodal Performance with Large-Scale and High-Quality Instruction Data
Oct 24, 2024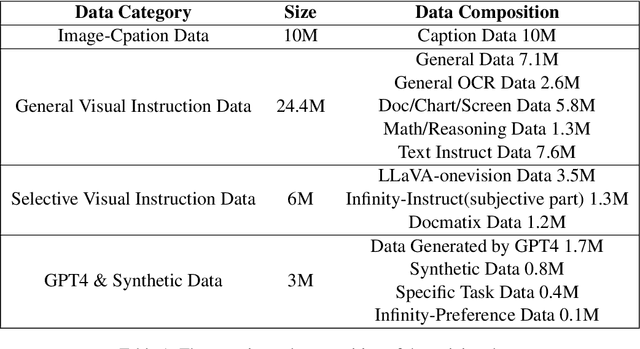
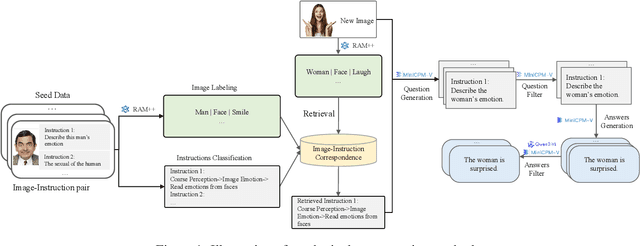
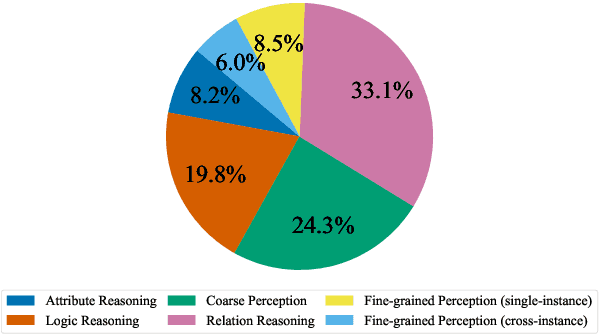
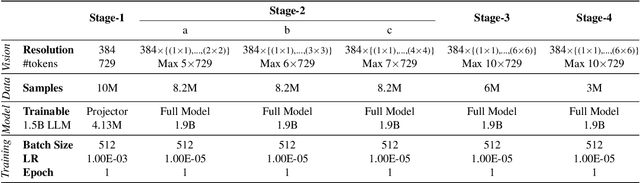
Vision-Language Models (VLMs) have recently made significant progress, but the limited scale and quality of open-source instruction data hinder their performance compared to closed-source models. In this work, we address this limitation by introducing Infinity-MM, a large-scale multimodal instruction dataset with 40 million samples, enhanced through rigorous quality filtering and deduplication. We also propose a synthetic instruction generation method based on open-source VLMs, using detailed image annotations and diverse question generation. Using this data, we trained a 2-billion-parameter VLM, Aquila-VL-2B, achieving state-of-the-art (SOTA) performance for models of similar scale. This demonstrates that expanding instruction data and generating synthetic data can significantly improve the performance of open-source models.
AquilaMoE: Efficient Training for MoE Models with Scale-Up and Scale-Out Strategies
Aug 13, 2024In recent years, with the rapid application of large language models across various fields, the scale of these models has gradually increased, and the resources required for their pre-training have grown exponentially. Training an LLM from scratch will cost a lot of computation resources while scaling up from a smaller model is a more efficient approach and has thus attracted significant attention. In this paper, we present AquilaMoE, a cutting-edge bilingual 8*16B Mixture of Experts (MoE) language model that has 8 experts with 16 billion parameters each and is developed using an innovative training methodology called EfficientScale. This approach optimizes performance while minimizing data requirements through a two-stage process. The first stage, termed Scale-Up, initializes the larger model with weights from a pre-trained smaller model, enabling substantial knowledge transfer and continuous pretraining with significantly less data. The second stage, Scale-Out, uses a pre-trained dense model to initialize the MoE experts, further enhancing knowledge transfer and performance. Extensive validation experiments on 1.8B and 7B models compared various initialization schemes, achieving models that maintain and reduce loss during continuous pretraining. Utilizing the optimal scheme, we successfully trained a 16B model and subsequently the 8*16B AquilaMoE model, demonstrating significant improvements in performance and training efficiency.