 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinity-MM: Scaling Multimodal Performance with Large-Scale and High-Quality Instruction Data
Oct 24, 2024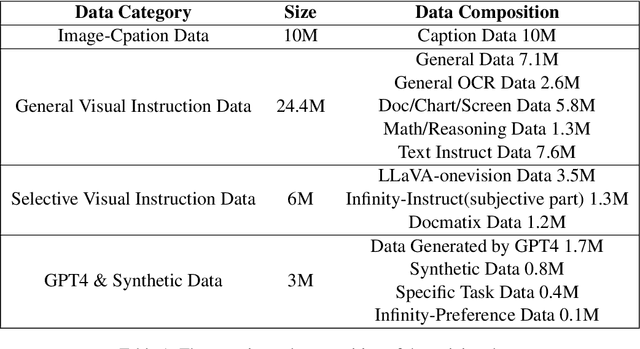
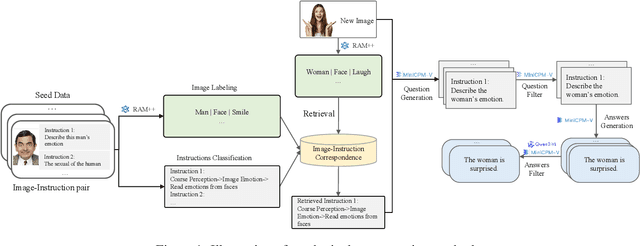
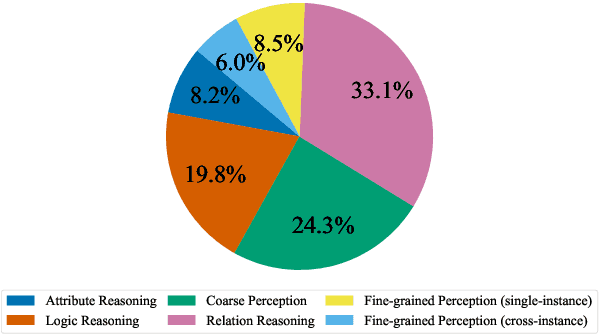
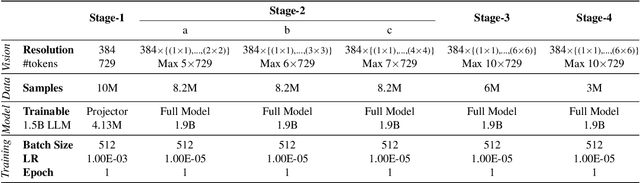
Vision-Language Models (VLMs) have recently made significant progress, but the limited scale and quality of open-source instruction data hinder their performance compared to closed-source models. In this work, we address this limitation by introducing Infinity-MM, a large-scale multimodal instruction dataset with 40 million samples, enhanced through rigorous quality filtering and deduplication. We also propose a synthetic instruction generation method based on open-source VLMs, using detailed image annotations and diverse question generation. Using this data, we trained a 2-billion-parameter VLM, Aquila-VL-2B, achieving state-of-the-art (SOTA) performance for models of similar scale. This demonstrates that expanding instruction data and generating synthetic data can significantly improve the performance of open-source models.
Two-stream Convolutional Networks for Multi-frame Face Anti-spoofing
Aug 09, 2021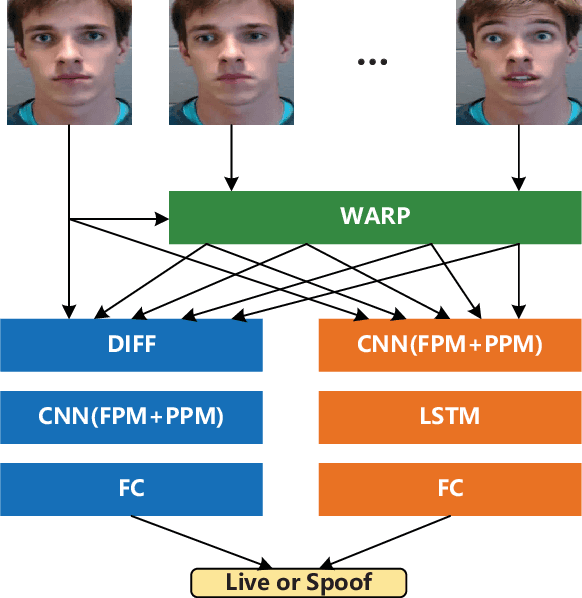
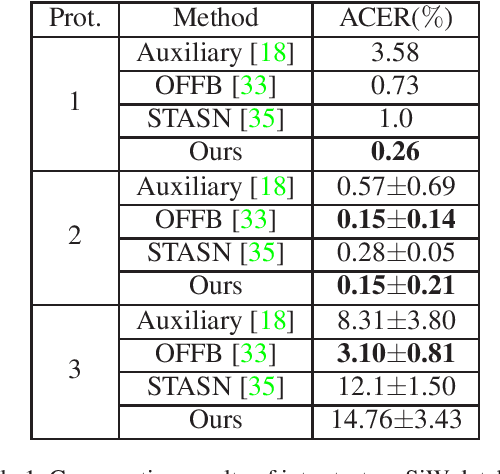
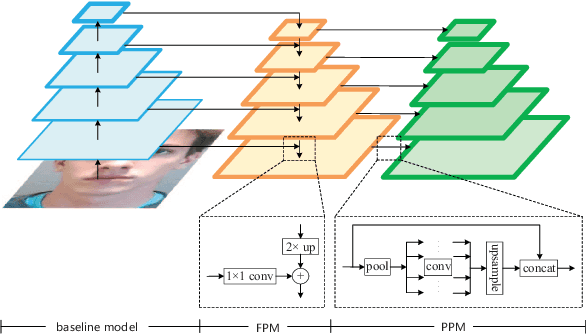
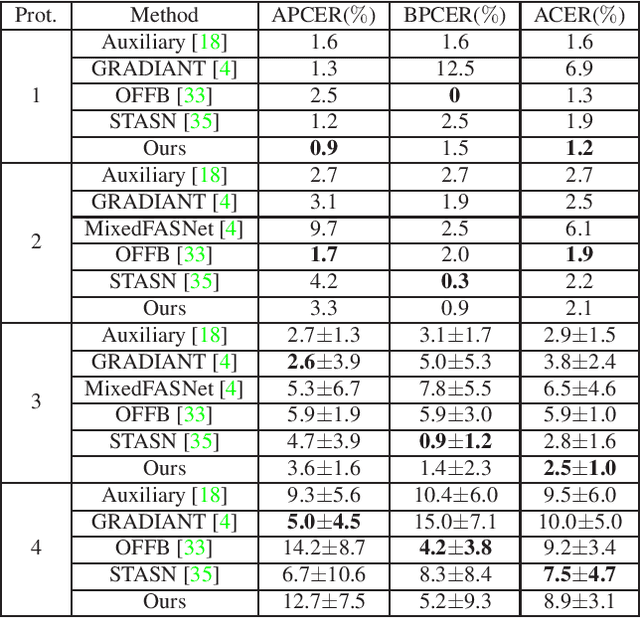
Face anti-spoofing is an important task to protect the security of face recognition. Most of previous work either struggle to capture discriminative and generalizable feature or rely on auxiliary information which is unavailable for most of industrial product. Inspired by the video classification work, we propose an efficient two-stream model to capture the key differences between live and spoof faces, which takes multi-frames and RGB difference as input respectively. Feature pyramid modules with two opposite fusion directions and pyramid pooling modules are applied to enhance feature representation. We evaluate the proposed method on the datasets of Siw, Oulu-NPU, CASIA-MFSD and Replay-Attack. The results show that our model achieves the state-of-the-art results on most of datasets' protocol with much less parameter size.