 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinity-MM: Scaling Multimodal Performance with Large-Scale and High-Quality Instruction Data
Paper and Code
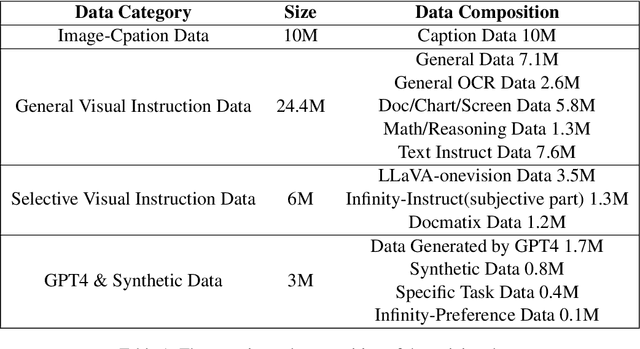
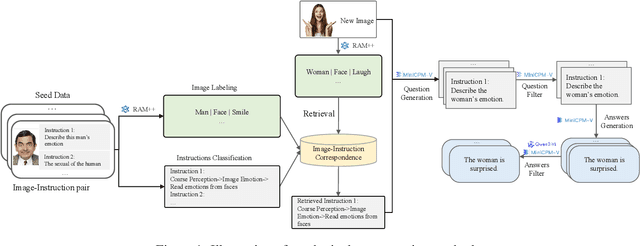
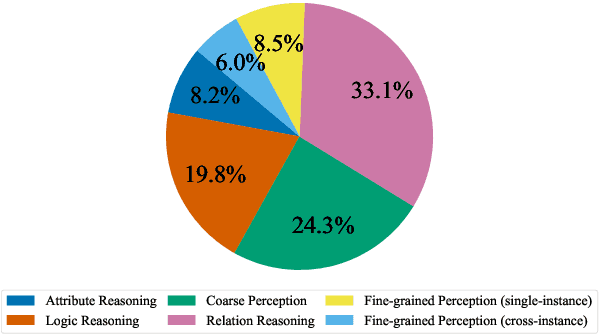
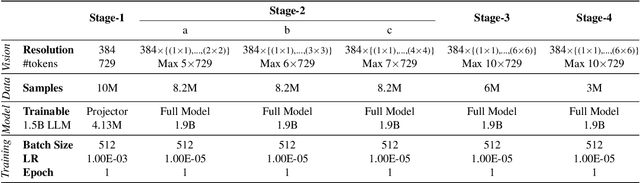
Vision-Language Models (VLMs) have recently made significant progress, but the limited scale and quality of open-source instruction data hinder their performance compared to closed-source models. In this work, we address this limitation by introducing Infinity-MM, a large-scale multimodal instruction dataset with 40 million samples, enhanced through rigorous quality filtering and deduplication. We also propose a synthetic instruction generation method based on open-source VLMs, using detailed image annotations and diverse question generation. Using this data, we trained a 2-billion-parameter VLM, Aquila-VL-2B, achieving state-of-the-art (SOTA) performance for models of similar scale. This demonstrates that expanding instruction data and generating synthetic data can significantly improve the performance of open-source models.