 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoSynth: Automated Workflow Optimization for High-Quality Synthetic Dataset Generation via Monte Carlo Tree Search
Nov 12, 2025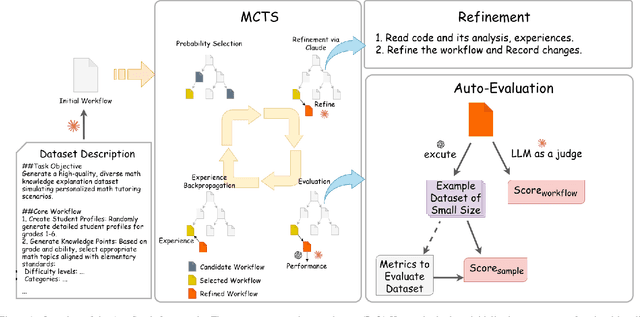


Supervised fine-tuning (SFT) of large language models (LLMs) for specialized tasks requires high-quality datasets, but manual curation is prohibitively expensive. Synthetic data generation offers scalability, but its effectiveness relies on complex, multi-stage workflows, integrating prompt engineering and model orchestration. Existing automated workflow methods face a cold start problem: they require labeled datasets for reward modeling, which is especially problematic for subjective, open-ended tasks with no objective ground truth. We introduce AutoSynth, a framework that automates workflow discovery and optimization without reference datasets by reframing the problem as a Monte Carlo Tree Search guided by a novel dataset-free hybrid reward. This reward enables meta-learning through two LLM-as-judge components: one evaluates sample quality using dynamically generated task-specific metrics, and another assesses workflow code and prompt quality. Experiments on subjective educational tasks show that while expert-designed workflows achieve higher human preference rates (96-99% win rates vs. AutoSynth's 40-51%), models trained on AutoSynth-generated data dramatically outperform baselines (40-51% vs. 2-5%) and match or surpass expert workflows on certain metrics, suggesting discovery of quality dimensions beyond human intuition. These results are achieved while reducing human effort from 5-7 hours to just 30 minutes (>90% reduction). AutoSynth tackles the cold start issue in data-centric AI, offering a scalable, cost-effective method for subjective LLM tasks. Code: https://github.com/bisz9918-maker/AutoSynth.
A Layer-wise Adversarial-aware Quantization Optimization for Improving Robustness
Oct 23, 2021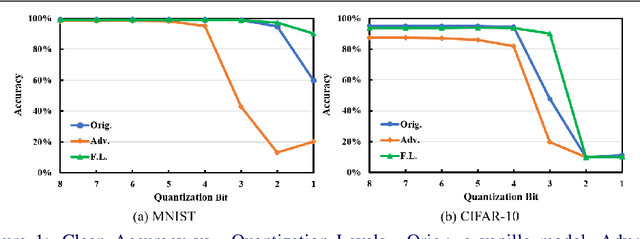
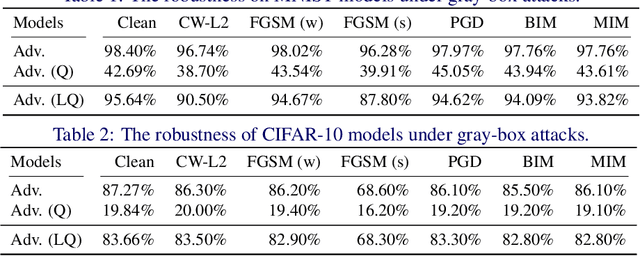

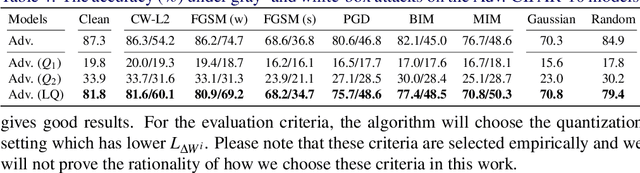
Neural networks are getting better accuracy with higher energy and computational cost. After quantization, the cost can be greatly saved, and the quantized models are more hardware friendly with acceptable accuracy loss. On the other hand, recent research has found that neural networks are vulnerable to adversarial attacks, and the robustness of a neural network model can only be improved with defense methods, such as adversarial training. In this work, we find that adversarially-trained neural networks are more vulnerable to quantization loss than plain models. To minimize both the adversarial and the quantization losses simultaneously and to make the quantized model robust, we propose a layer-wise adversarial-aware quantization method, using the Lipschitz constant to choose the best quantization parameter settings for a neural network. We theoretically derive the losses and prove the consistency of our metric selection. The experiment results show that our method can effectively and efficiently improve the robustness of quantized adversarially-trained neural networks.
Two-stream Convolutional Networks for Multi-frame Face Anti-spoofing
Aug 09, 2021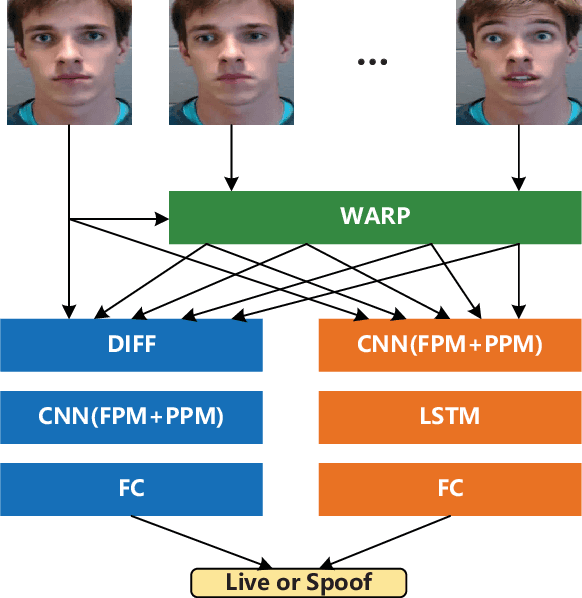
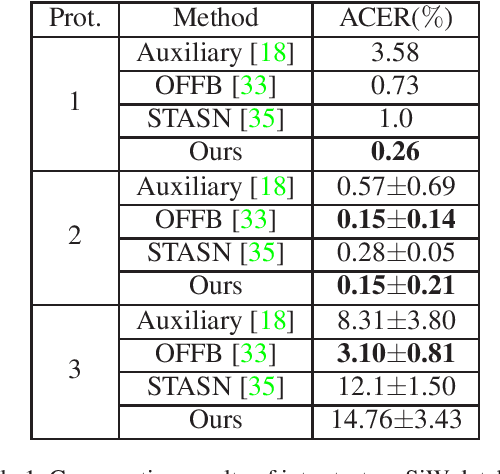
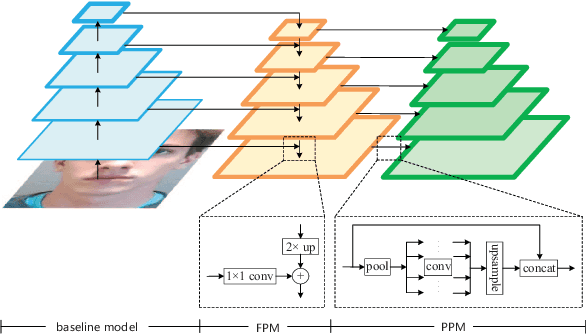
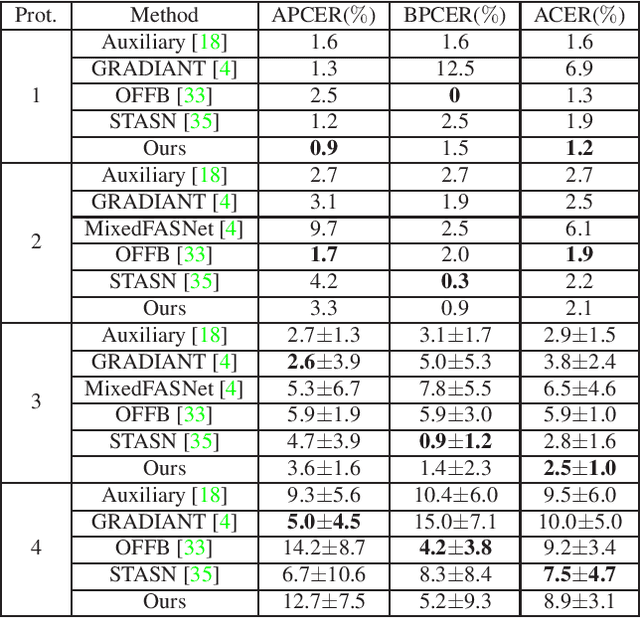
Face anti-spoofing is an important task to protect the security of face recognition. Most of previous work either struggle to capture discriminative and generalizable feature or rely on auxiliary information which is unavailable for most of industrial product. Inspired by the video classification work, we propose an efficient two-stream model to capture the key differences between live and spoof faces, which takes multi-frames and RGB difference as input respectively. Feature pyramid modules with two opposite fusion directions and pyramid pooling modules are applied to enhance feature representation. We evaluate the proposed method on the datasets of Siw, Oulu-NPU, CASIA-MFSD and Replay-Attack. The results show that our model achieves the state-of-the-art results on most of datasets' protocol with much less parameter size.
Improving Adversarial Robustness in Weight-quantized Neural Networks
Jan 23, 2021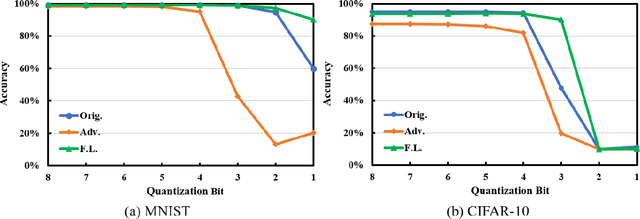
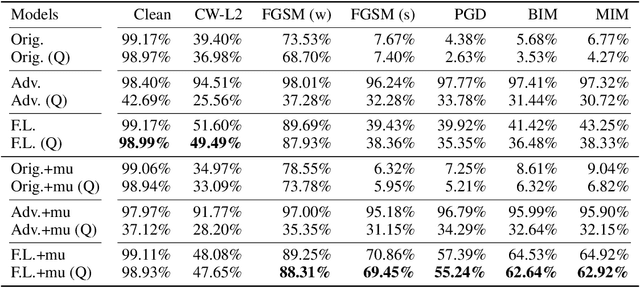
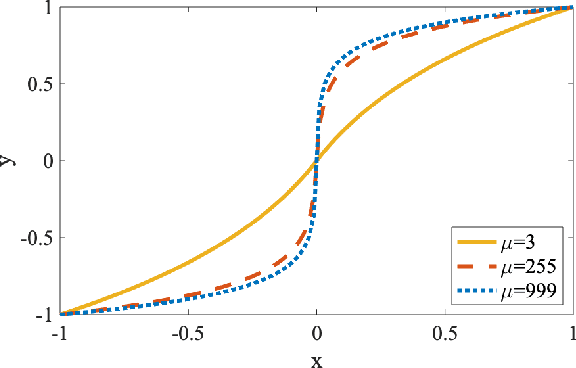
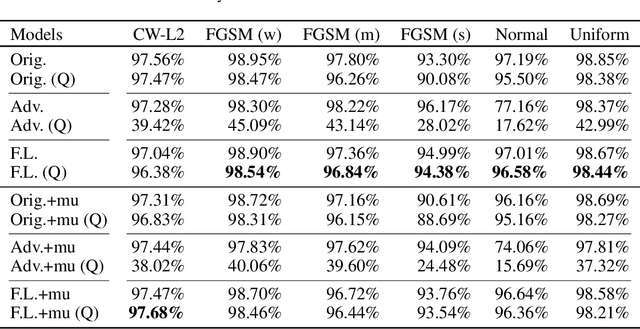
Neural networks are getting deeper and more computation-intensive nowadays. Quantization is a useful technique in deploying neural networks on hardware platforms and saving computation costs with negligible performance loss. However, recent research reveals that neural network models, no matter full-precision or quantized, are vulnerable to adversarial attacks. In this work, we analyze both adversarial and quantization losses and then introduce criteria to evaluate them. We propose a boundary-based retraining method to mitigate adversarial and quantization losses together and adopt a nonlinear mapping method to defend against white-box gradient-based adversarial attacks. The evaluations demonstrate that our method can better restore accuracy after quantization than other baseline methods on both black-box and white-box adversarial attacks. The results also show that adversarial training suffers quantization loss and does not cooperate well with other training methods.
Feedback Learning for Improving the Robustness of Neural Networks
Sep 12, 2019
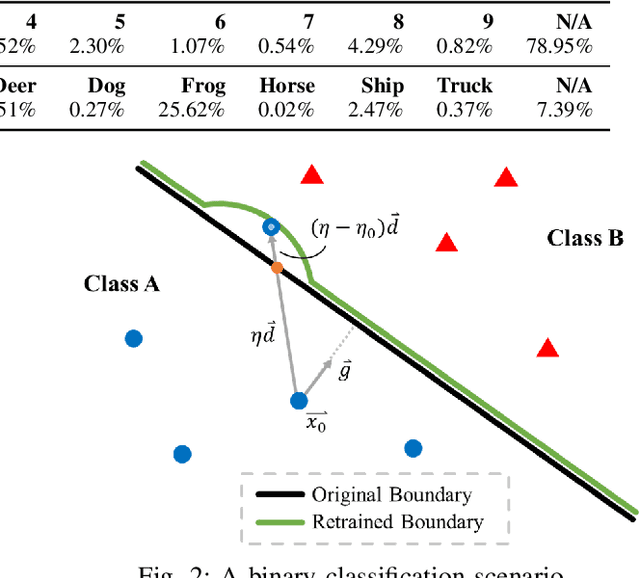
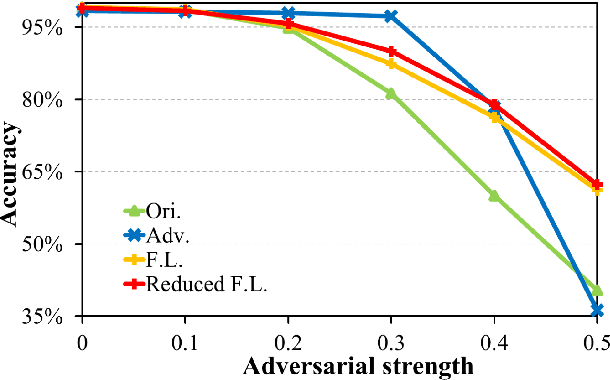
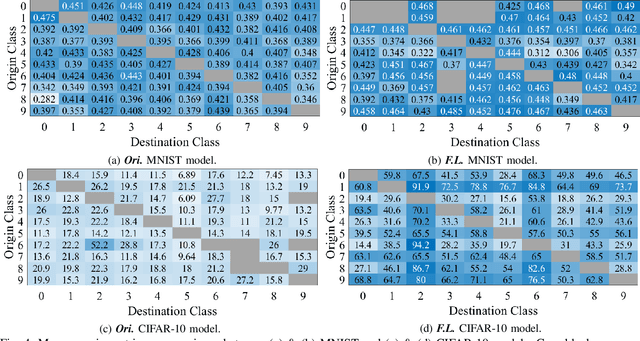
Recent research studies revealed that neural networks are vulnerable to adversarial attacks. State-of-the-art defensive techniques add various adversarial examples in training to improve models' adversarial robustness. However, these methods are not universal and can't defend unknown or non-adversarial evasion attacks. In this paper, we analyze the model robustness in the decision space. A feedback learning method is then proposed, to understand how well a model learns and to facilitate the retraining process of remedying the defects. The evaluations according to a set of distance-based criteria show that our method can significantly improve models' accuracy and robustness against different types of evasion attacks. Moreover, we observe the existence of inter-class inequality and propose to compensate it by changing the proportions of examples generated in different classes.
MAT: A Multi-strength Adversarial Training Method to Mitigate Adversarial Attacks
May 11, 2018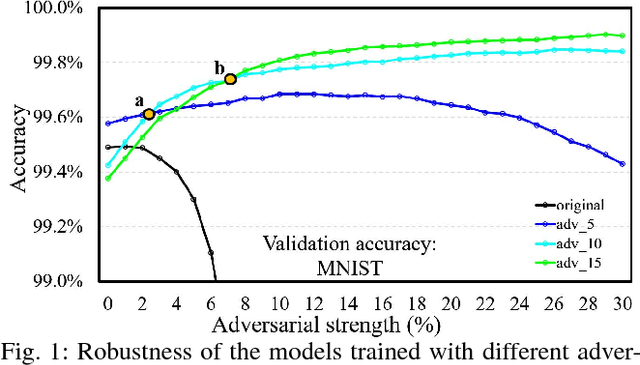
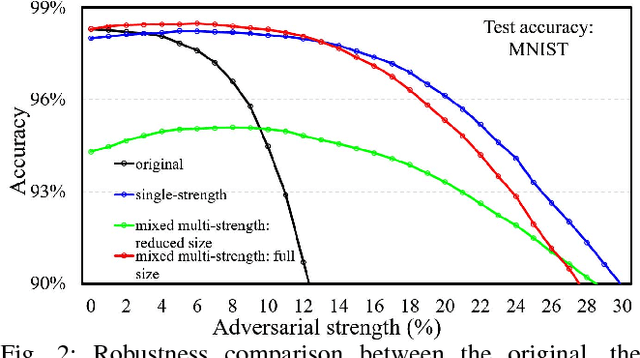
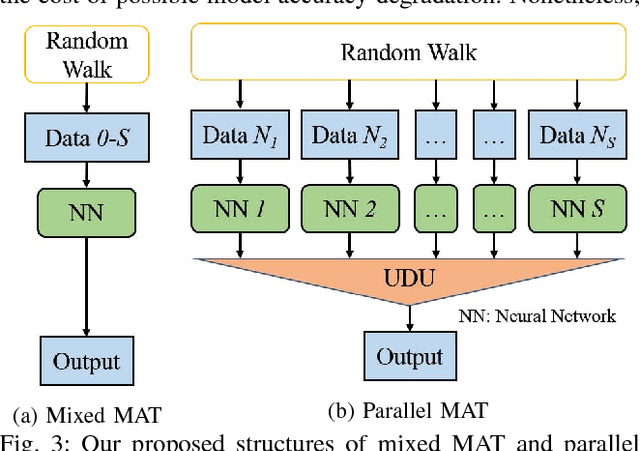
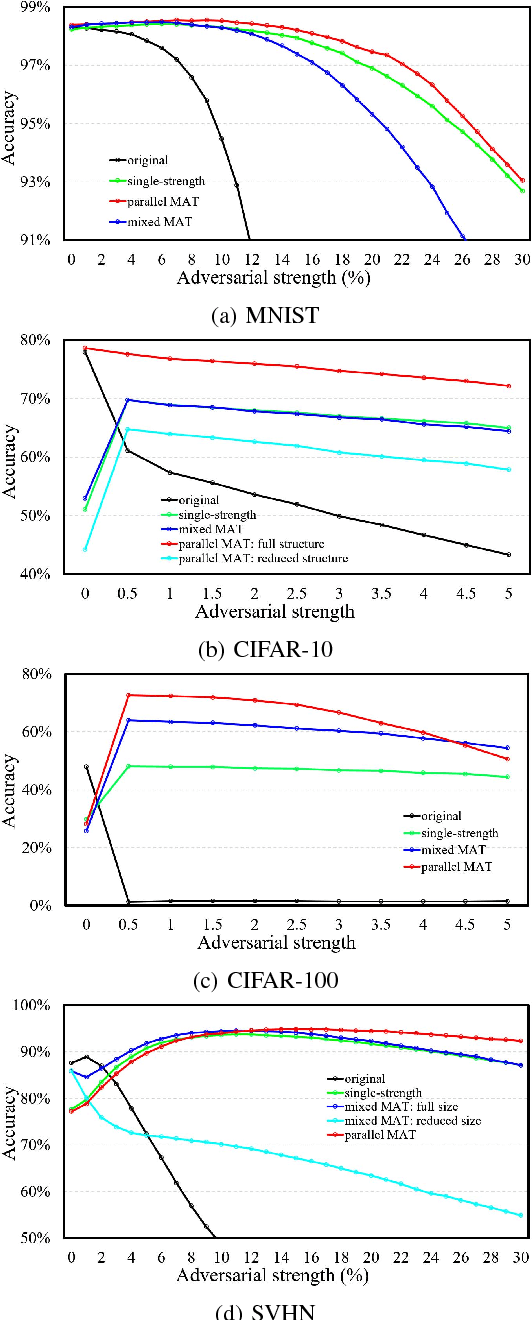
Some recent works revealed that deep neural networks (DNNs) are vulnerable to so-called adversarial attacks where input examples are intentionally perturbed to fool DNNs. In this work, we revisit the DNN training process that includes adversarial examples into the training dataset so as to improve DNN's resilience to adversarial attacks, namely, adversarial training. Our experiments show that different adversarial strengths, i.e., perturbation levels of adversarial examples, have different working zones to resist the attack. Based on the observation, we propose a multi-strength adversarial training method (MAT) that combines the adversarial training examples with different adversarial strengths to defend adversarial attacks. Two training structures - mixed MAT and parallel MAT - are developed to facilitate the tradeoffs between training time and memory occupation. Our results show that MAT can substantially minimize the accuracy degradation of deep learning systems to adversarial attacks on MNIST, CIFAR-10, CIFAR-100, and SVHN.