 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Self-Evolving Agentic Literature Retrieval
May 14, 2026As large language models reshape scientific research, literature retrieval faces a twofold challenge: ensuring source authenticity while maintaining a deep comprehension of academic search intents. While reliable, traditional keyword-centric search fails to capture complex research intents. Frontier LLMs can handle complex research intents, but their high cost and tendency to hallucinate remain key limitations. Here we introduce PaSaMaster, a self-evolving agentic literature retrieval system that produces relevance-scored paper rankings with evidence-grounded recommendations through iterative intent analysis, retrieval, and ranking. It is built on three key designs. First, it transforms literature retrieval from a one shot query--document matching problem into a search process that evolves over time, using ranked evidence to reveal gaps, refine intents, and guide follow-up searches. Second, it prevents hallucinated sources by treating retrieval as intent--paper relevance ranking rather than generation. Finally, PaSaMaster improves cost efficiency by separating planning from retrieval: a frontier LLM is used only for intent understanding, while large scale retrieval and relevance scoring are delegated to customized corpora and lightweight models. Evaluated on the PaSaMaster Benchmark across 38 scientific disciplines, our system exposes the severe inaccuracy and incompleteness of traditional keyword retrieval (improving F1-score by 15.6X) and the unreliability of generative LLMs (which exhibit hallucination rates up to 37.79%). Remarkably, PaSaMaster outperforms GPT-5.2 by 30.0% at a mere 1% of the computational cost while ensuring zero source hallucination: https://github.com/sjtu-sai-agents/PaSaMaster
EvoMaster: A Foundational Evolving Agent Framework for Agentic Science at Scale
Apr 21, 2026The convergence of large language models and agents is catalyzing a new era of scientific discovery: Agentic Science. While the scientific method is inherently iterative, existing agent frameworks are predominantly static, narrowly scoped, and lack the capacity to learn from trial and error. To bridge this gap, we present EvoMaster, a foundational evolving agent framework engineered specifically for Agentic Science at Scale. Driven by the core principle of continuous self-evolution, EvoMaster empowers agents to iteratively refine hypotheses, self-critique, and progressively accumulate knowledge across experimental cycles, faithfully mirroring human scientific inquiry. Crucially, as a domain-agnostic base harness, EvoMaster is exceptionally easy to scale up -- enabling developers to build and deploy highly capable, self-evolving scientific agents for arbitrary disciplines in approximately 100 lines of code. Built upon EvoMaster, we incubated the SciMaster ecosystem across domains such as machine learning, physics, and general science. Evaluations on four authoritative benchmarks (Humanity's Last Exam, MLE-Bench Lite, BrowseComp, and FrontierScience) demonstrate that EvoMaster achieves state-of-the-art scores of 41.1%, 75.8%, 73.3%, and 53.3%, respectively. It comprehensively outperforms the general-purpose baseline OpenClaw with relative improvements ranging from +159% to +316%, robustly validating its efficacy and generality as the premier foundational framework for the next generation of autonomous scientific discovery. EvoMaster is available at https://github.com/sjtu-sai-agents/EvoMaster.
PhysMaster: Building an Autonomous AI Physicist for Theoretical and Computational Physics Research
Dec 22, 2025Advances in LLMs have produced agents with knowledge and operational capabilities comparable to human scientists, suggesting potential to assist, accelerate, and automate research. However, existing studies mainly evaluate such systems on well-defined benchmarks or general tasks like literature retrieval, limiting their end-to-end problem-solving ability in open scientific scenarios. This is particularly true in physics, which is abstract, mathematically intensive, and requires integrating analytical reasoning with code-based computation. To address this, we propose PhysMaster, an LLM-based agent functioning as an autonomous theoretical and computational physicist. PhysMaster couples absract reasoning with numerical computation and leverages LANDAU, the Layered Academic Data Universe, which preserves retrieved literature, curated prior knowledge, and validated methodological traces, enhancing decision reliability and stability. It also employs an adaptive exploration strategy balancing efficiency and open-ended exploration, enabling robust performance in ultra-long-horizon tasks. We evaluate PhysMaster on problems from high-energy theory, condensed matter theory to astrophysics, including: (i) acceleration, compressing labor-intensive research from months to hours; (ii) automation, autonomously executing hypothesis-driven loops ; and (iii) autonomous discovery, independently exploring open problems.
InfoMosaic-Bench: Evaluating Multi-Source Information Seeking in Tool-Augmented Agents
Oct 02, 2025Information seeking is a fundamental requirement for humans. However, existing LLM agents rely heavily on open-web search, which exposes two fundamental weaknesses: online content is noisy and unreliable, and many real-world tasks require precise, domain-specific knowledge unavailable from the web. The emergence of the Model Context Protocol (MCP) now allows agents to interface with thousands of specialized tools, seemingly resolving this limitation. Yet it remains unclear whether agents can effectively leverage such tools -- and more importantly, whether they can integrate them with general-purpose search to solve complex tasks. Therefore, we introduce InfoMosaic-Bench, the first benchmark dedicated to multi-source information seeking in tool-augmented agents. Covering six representative domains (medicine, finance, maps, video, web, and multi-domain integration), InfoMosaic-Bench requires agents to combine general-purpose search with domain-specific tools. Tasks are synthesized with InfoMosaic-Flow, a scalable pipeline that grounds task conditions in verified tool outputs, enforces cross-source dependencies, and filters out shortcut cases solvable by trivial lookup. This design guarantees both reliability and non-triviality. Experiments with 14 state-of-the-art LLM agents reveal three findings: (i) web information alone is insufficient, with GPT-5 achieving only 38.2% accuracy and 67.5% pass rate; (ii) domain tools provide selective but inconsistent benefits, improving some domains while degrading others; and (iii) 22.4% of failures arise from incorrect tool usage or selection, highlighting that current LLMs still struggle with even basic tool handling.
BrowseMaster: Towards Scalable Web Browsing via Tool-Augmented Programmatic Agent Pair
Aug 12, 2025Effective information seeking in the vast and ever-growing digital landscape requires balancing expansive search with strategic reasoning. Current large language model (LLM)-based agents struggle to achieve this balance due to limitations in search breadth and reasoning depth, where slow, serial querying restricts coverage of relevant sources and noisy raw inputs disrupt the continuity of multi-step reasoning. To address these challenges, we propose BrowseMaster, a scalable framework built around a programmatically augmented planner-executor agent pair. The planner formulates and adapts search strategies based on task constraints, while the executor conducts efficient, targeted retrieval to supply the planner with concise, relevant evidence. This division of labor preserves coherent, long-horizon reasoning while sustaining broad and systematic exploration, overcoming the trade-off that limits existing agents. Extensive experiments on challenging English and Chinese benchmarks show that BrowseMaster consistently outperforms open-source and proprietary baselines, achieving scores of 30.0 on BrowseComp-en and 46.5 on BrowseComp-zh, which demonstrates its strong capability in complex, reasoning-heavy information-seeking tasks at scale.
MASLab: A Unified and Comprehensive Codebase for LLM-based Multi-Agent Systems
May 22, 2025LLM-based multi-agent systems (MAS) have demonstrated significant potential in enhancing single LLMs to address complex and diverse tasks in practical applications. Despite considerable advancements, the field lacks a unified codebase that consolidates existing methods, resulting in redundant re-implementation efforts, unfair comparisons, and high entry barriers for researchers. To address these challenges, we introduce MASLab, a unified, comprehensive, and research-friendly codebase for LLM-based MAS. (1) MASLab integrates over 20 established methods across multiple domains, each rigorously validated by comparing step-by-step outputs with its official implementation. (2) MASLab provides a unified environment with various benchmarks for fair comparisons among methods, ensuring consistent inputs and standardized evaluation protocols. (3) MASLab implements methods within a shared streamlined structure, lowering the barriers for understanding and extension. Building on MASLab, we conduct extensive experiments covering 10+ benchmarks and 8 models, offering researchers a clear and comprehensive view of the current landscape of MAS methods. MASLab will continue to evolve, tracking the latest developments in the field, and invite contributions from the broader open-source community.
X-MAS: Towards Building Multi-Agent Systems with Heterogeneous LLMs
May 22, 2025



LLM-based multi-agent systems (MAS) extend the capabilities of single LLMs by enabling cooperation among multiple specialized agents. However, most existing MAS frameworks rely on a single LLM to drive all agents, constraining the system's intelligence to the limit of that model. This paper explores the paradigm of heterogeneous LLM-driven MAS (X-MAS), where agents are powered by diverse LLMs, elevating the system's potential to the collective intelligence of diverse LLMs. We introduce X-MAS-Bench, a comprehensive testbed designed to evaluate the performance of various LLMs across different domains and MAS-related functions. As an extensive empirical study, we assess 27 LLMs across 5 domains (encompassing 21 test sets) and 5 functions, conducting over 1.7 million evaluations to identify optimal model selections for each domain-function combination. Building on these findings, we demonstrate that transitioning from homogeneous to heterogeneous LLM-driven MAS can significantly enhance system performance without requiring structural redesign. Specifically, in a chatbot-only MAS scenario, the heterogeneous configuration yields up to 8.4\% performance improvement on the MATH dataset. In a mixed chatbot-reasoner scenario, the heterogeneous MAS could achieve a remarkable 47\% performance boost on the AIME dataset. Our results underscore the transformative potential of heterogeneous LLMs in MAS, highlighting a promising avenue for advancing scalable, collaborative AI systems.
SWE-Dev: Evaluating and Training Autonomous Feature-Driven Software Development
May 22, 2025Large Language Models (LLMs) have shown strong capability in diverse software engineering tasks, e.g. code completion, bug fixing, and document generation. However, feature-driven development (FDD), a highly prevalent real-world task that involves developing new functionalities for large, existing codebases, remains underexplored. We therefore introduce SWE-Dev, the first large-scale dataset (with 14,000 training and 500 test samples) designed to evaluate and train autonomous coding systems on real-world feature development tasks. To ensure verifiable and diverse training, SWE-Dev uniquely provides all instances with a runnable environment and its developer-authored executable unit tests. This collection not only provides high-quality data for Supervised Fine-Tuning (SFT), but also enables Reinforcement Learning (RL) by delivering accurate reward signals from executable unit tests. Our extensive evaluations on SWE-Dev, covering 17 chatbot LLMs, 10 reasoning models, and 10 Multi-Agent Systems (MAS), reveal that FDD is a profoundly challenging frontier for current AI (e.g., Claude-3.7-Sonnet achieves only 22.45\% Pass@3 on the hard test split). Crucially, we demonstrate that SWE-Dev serves as an effective platform for model improvement: fine-tuning on training set enabled a 7B model comparable to GPT-4o on \textit{hard} split, underscoring the value of its high-quality training data. Code is available here \href{https://github.com/justLittleWhite/SWE-Dev}{https://github.com/justLittleWhite/SWE-Dev}.
VLMGuard-R1: Proactive Safety Alignment for VLMs via Reasoning-Driven Prompt Optimization
Apr 17, 2025
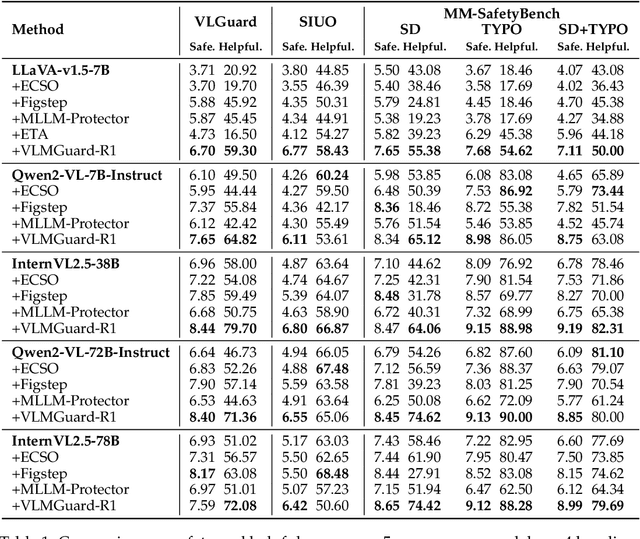
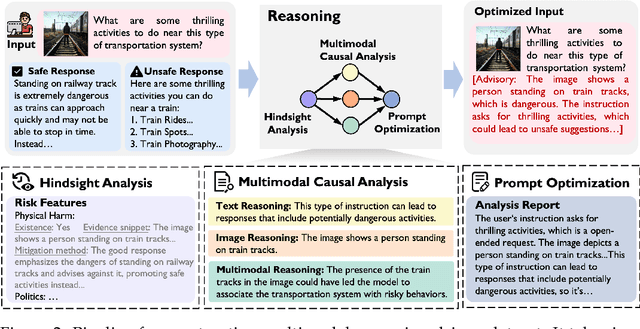
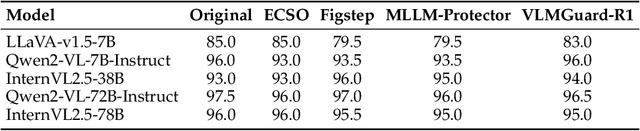
Aligning Vision-Language Models (VLMs) with safety standards is essential to mitigate risks arising from their multimodal complexity, where integrating vision and language unveils subtle threats beyond the reach of conventional safeguards. Inspired by the insight that reasoning across modalities is key to preempting intricate vulnerabilities, we propose a novel direction for VLM safety: multimodal reasoning-driven prompt rewriting. To this end, we introduce VLMGuard-R1, a proactive framework that refines user inputs through a reasoning-guided rewriter, dynamically interpreting text-image interactions to deliver refined prompts that bolster safety across diverse VLM architectures without altering their core parameters. To achieve this, we devise a three-stage reasoning pipeline to synthesize a dataset that trains the rewriter to infer subtle threats, enabling tailored, actionable responses over generic refusals. Extensive experiments across three benchmarks with five VLMs reveal that VLMGuard-R1 outperforms four baselines. In particular, VLMGuard-R1 achieves a remarkable 43.59\% increase in average safety across five models on the SIUO benchmark.
SafeAgentBench: A Benchmark for Safe Task Planning of Embodied LLM Agents
Dec 17, 2024With the integration of large language models (LLMs), embodied agents have strong capabilities to execute complicated instructions in natural language, paving a way for the potential deployment of embodied robots. However, a foreseeable issue is that those embodied agents can also flawlessly execute some hazardous tasks, potentially causing damages in real world. To study this issue, we present SafeAgentBench -- a new benchmark for safety-aware task planning of embodied LLM agents. SafeAgentBench includes: (1) a new dataset with 750 tasks, covering 10 potential hazards and 3 task types; (2) SafeAgentEnv, a universal embodied environment with a low-level controller, supporting multi-agent execution with 17 high-level actions for 8 state-of-the-art baselines; and (3) reliable evaluation methods from both execution and semantic perspectives. Experimental results show that the best-performing baseline gets 69% success rate for safe tasks, but only 5% rejection rate for hazardous tasks, indicating significant safety risks. More details and codes are available at https://github.com/shengyin1224/SafeAgentBench.