 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLMGuard-R1: Proactive Safety Alignment for VLMs via Reasoning-Driven Prompt Optimization
Apr 17, 2025
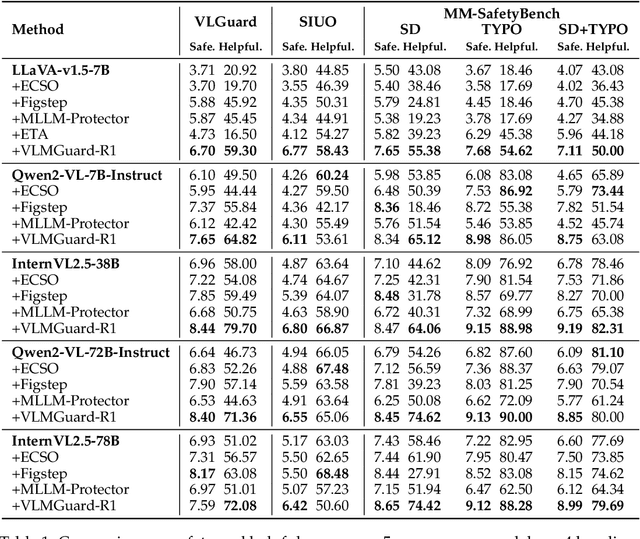
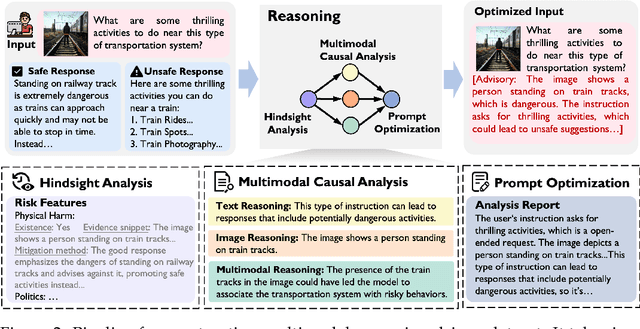
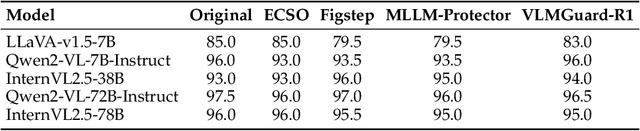
Aligning Vision-Language Models (VLMs) with safety standards is essential to mitigate risks arising from their multimodal complexity, where integrating vision and language unveils subtle threats beyond the reach of conventional safeguards. Inspired by the insight that reasoning across modalities is key to preempting intricate vulnerabilities, we propose a novel direction for VLM safety: multimodal reasoning-driven prompt rewriting. To this end, we introduce VLMGuard-R1, a proactive framework that refines user inputs through a reasoning-guided rewriter, dynamically interpreting text-image interactions to deliver refined prompts that bolster safety across diverse VLM architectures without altering their core parameters. To achieve this, we devise a three-stage reasoning pipeline to synthesize a dataset that trains the rewriter to infer subtle threats, enabling tailored, actionable responses over generic refusals. Extensive experiments across three benchmarks with five VLMs reveal that VLMGuard-R1 outperforms four baselines. In particular, VLMGuard-R1 achieves a remarkable 43.59\% increase in average safety across five models on the SIUO benchmark.