 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushupBench: Your VLM is not good at counting pushups
Apr 25, 2026Large vision-language models (VLMs) can recognize \textit{what} happens in video but fail to count \textit{how many} times. We introduce \textbf{PushupBench}, 446 long-form clips (avg. 36.7s) for evaluating repetition counting. The best frontier model achieves 42.1\% exact accuracy; open-source 4B models score $\sim$6\%, matching supervised baselines. We show that accuracy alone misleads -- weaker models exploit the modal count rather than reason temporally. Fine-tuning on counting with 1k samples transfers to general video understanding: MVBench (+2.15), PerceptionTest (+1.88), TVBench (+4.54), suggesting counting is a proxy for broader temporal reasoning.PushupBench incorporated in \texttt{lmms-eval} (https://github.com/EvolvingLMMs-Lab/lmms-eval/pull/1262) and hosted on (pushupbench.com/)
Gencho: Room Impulse Response Generation from Reverberant Speech and Text via Diffusion Transformers
Feb 09, 2026Blind room impulse response (RIR) estimation is a core task for capturing and transferring acoustic properties; yet existing methods often suffer from limited modeling capability and degraded performance under unseen conditions. Moreover, emerging generative audio applications call for more flexible impulse response generation methods. We propose Gencho, a diffusion-transformer-based model that predicts complex spectrogram RIRs from reverberant speech. A structure-aware encoder leverages isolation between early and late reflections to encode the input audio into a robust representation for conditioning, while the diffusion decoder generates diverse and perceptually realistic impulse responses from it. Gencho integrates modularly with standard speech processing pipelines for acoustic matching. Results show richer generated RIRs than non-generative baselines while maintaining strong performance in standard RIR metrics. We further demonstrate its application to text-conditioned RIR generation, highlighting Gencho's versatility for controllable acoustic simulation and generative audio tasks.
PromptSep: Generative Audio Separation via Multimodal Prompting
Nov 06, 2025Recent breakthroughs in language-queried audio source separation (LASS) have shown that generative models can achieve higher separation audio quality than traditional masking-based approaches. However, two key limitations restrict their practical use: (1) users often require operations beyond separation, such as sound removal; and (2) relying solely on text prompts can be unintuitive for specifying sound sources. In this paper, we propose PromptSep to extend LASS into a broader framework for general-purpose sound separation. PromptSep leverages a conditional diffusion model enhanced with elaborated data simulation to enable both audio extraction and sound removal. To move beyond text-only queries, we incorporate vocal imitation as an additional and more intuitive conditioning modality for our model, by incorporating Sketch2Sound as a data augmentation strategy. Both objective and subjective evaluations on multiple benchmarks demonstrate that PromptSep achieves state-of-the-art performance in sound removal and vocal-imitation-guided source separation, while maintaining competitive results on language-queried source separation.
MASLab: A Unified and Comprehensive Codebase for LLM-based Multi-Agent Systems
May 22, 2025LLM-based multi-agent systems (MAS) have demonstrated significant potential in enhancing single LLMs to address complex and diverse tasks in practical applications. Despite considerable advancements, the field lacks a unified codebase that consolidates existing methods, resulting in redundant re-implementation efforts, unfair comparisons, and high entry barriers for researchers. To address these challenges, we introduce MASLab, a unified, comprehensive, and research-friendly codebase for LLM-based MAS. (1) MASLab integrates over 20 established methods across multiple domains, each rigorously validated by comparing step-by-step outputs with its official implementation. (2) MASLab provides a unified environment with various benchmarks for fair comparisons among methods, ensuring consistent inputs and standardized evaluation protocols. (3) MASLab implements methods within a shared streamlined structure, lowering the barriers for understanding and extension. Building on MASLab, we conduct extensive experiments covering 10+ benchmarks and 8 models, offering researchers a clear and comprehensive view of the current landscape of MAS methods. MASLab will continue to evolve, tracking the latest developments in the field, and invite contributions from the broader open-source community.
Deep Audio Watermarks are Shallow: Limitations of Post-Hoc Watermarking Techniques for Speech
Apr 15, 2025In the audio modality, state-of-the-art watermarking methods leverage deep neural networks to allow the embedding of human-imperceptible signatures in generated audio. The ideal is to embed signatures that can be detected with high accuracy when the watermarked audio is altered via compression, filtering, or other transformations. Existing audio watermarking techniques operate in a post-hoc manner, manipulating "low-level" features of audio recordings after generation (e.g. through the addition of a low-magnitude watermark signal). We show that this post-hoc formulation makes existing audio watermarks vulnerable to transformation-based removal attacks. Focusing on speech audio, we (1) unify and extend existing evaluations of the effect of audio transformations on watermark detectability, and (2) demonstrate that state-of-the-art post-hoc audio watermarks can be removed with no knowledge of the watermarking scheme and minimal degradation in audio quality.
DiTSE: High-Fidelity Generative Speech Enhancement via Latent Diffusion Transformers
Apr 13, 2025Real-world speech recordings suffer from degradations such as background noise and reverberation. Speech enhancement aims to mitigate these issues by generating clean high-fidelity signals. While recent generative approaches for speech enhancement have shown promising results, they still face two major challenges: (1) content hallucination, where plausible phonemes generated differ from the original utterance; and (2) inconsistency, failing to preserve speaker's identity and paralinguistic features from the input speech. In this work, we introduce DiTSE (Diffusion Transformer for Speech Enhancement), which addresses quality issues of degraded speech in full bandwidth. Our approach employs a latent diffusion transformer model together with robust conditioning features, effectively addressing these challenges while remaining computationally efficient. Experimental results from both subjective and objective evaluations demonstrate that DiTSE achieves state-of-the-art audio quality that, for the first time, matches real studio-quality audio from the DAPS dataset. Furthermore, DiTSE significantly improves the preservation of speaker identity and content fidelity, reducing hallucinations across datasets compared to state-of-the-art enhancers. Audio samples are available at: http://hguimaraes.me/DiTSE
Code Drift: Towards Idempotent Neural Audio Codecs
Oct 14, 2024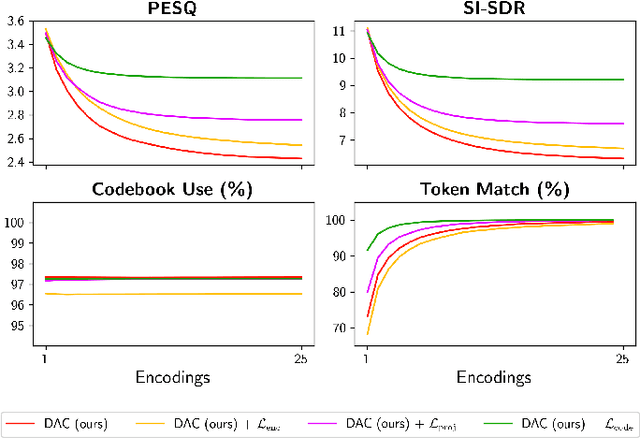
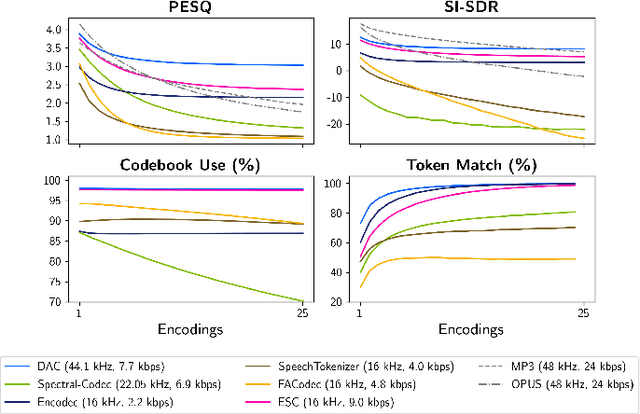
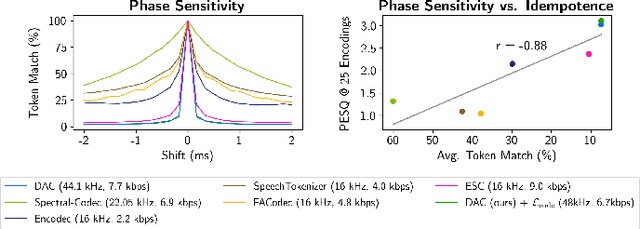
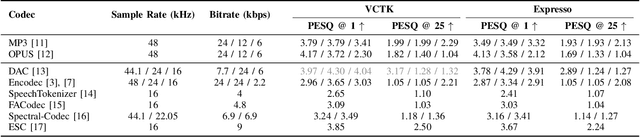
Neural codecs have demonstrated strong performance in high-fidelity compression of audio signals at low bitrates. The token-based representations produced by these codecs have proven particularly useful for generative modeling. While much research has focused on improvements in compression ratio and perceptual transparency, recent works have largely overlooked another desirable codec property -- idempotence, the stability of compressed outputs under multiple rounds of encoding. We find that state-of-the-art neural codecs exhibit varied degrees of idempotence, with some degrading audio outputs significantly after as few as three encodings. We investigate possible causes of low idempotence and devise a method for improving idempotence through fine-tuning a codec model. We then examine the effect of idempotence on a simple conditional generative modeling task, and find that increased idempotence can be achieved without negatively impacting downstream modeling performance -- potentially extending the usefulness of neural codecs for practical file compression and iterative generative modeling workflows.
Improving Generalization of Speech Separation in Real-World Scenarios: Strategies in Simulation, Optimization, and Evaluation
Aug 28, 2024



Achieving robust speech separation for overlapping speakers in various acoustic environments with noise and reverberation remains an open challenge. Although existing datasets are available to train separators for specific scenarios, they do not effectively generalize across diverse real-world scenarios. In this paper, we present a novel data simulation pipeline that produces diverse training data from a range of acoustic environments and content, and propose new training paradigms to improve quality of a general speech separation model. Specifically, we first introduce AC-SIM, a data simulation pipeline that incorporates broad variations in both content and acoustics. Then we integrate multiple training objectives into the permutation invariant training (PIT) to enhance separation quality and generalization of the trained model. Finally, we conduct comprehensive objective and human listening experiments across separation architectures and benchmarks to validate our methods, demonstrating substantial improvement of generalization on both non-homologous and real-world test sets.
TARN-VIST: Topic Aware Reinforcement Network for Visual Storytelling
Mar 18, 2024



As a cross-modal task, visual storytelling aims to generate a story for an ordered image sequence automatically. Different from the image captioning task, visual storytelling requires not only modeling the relationships between objects in the image but also mining the connections between adjacent images. Recent approaches primarily utilize either end-to-end frameworks or multi-stage frameworks to generate relevant stories, but they usually overlook latent topic information. In this paper, in order to generate a more coherent and relevant story, we propose a novel method, Topic Aware Reinforcement Network for VIsual StoryTelling (TARN-VIST). In particular, we pre-extracted the topic information of stories from both visual and linguistic perspectives. Then we apply two topic-consistent reinforcement learning rewards to identify the discrepancy between the generated story and the human-labeled story so as to refine the whole generation process. Extensive experimental results on the VIST dataset and human evaluation demonstrate that our proposed model outperforms most of the competitive models across multiple evaluation metrics.
HiFi-GAN: High-Fidelity Denoising and Dereverberation Based on Speech Deep Features in Adversarial Networks
Jun 10, 2020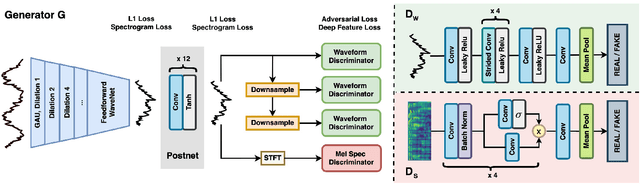
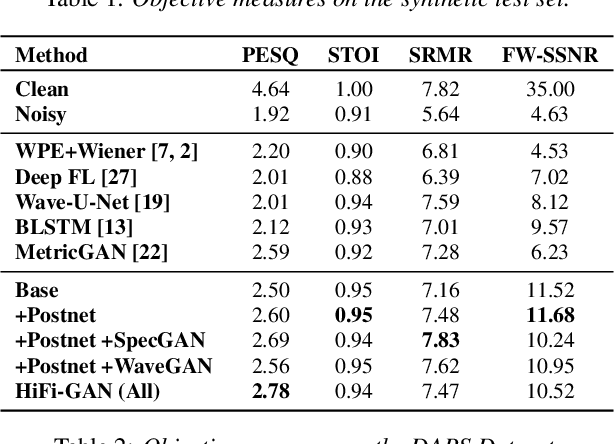
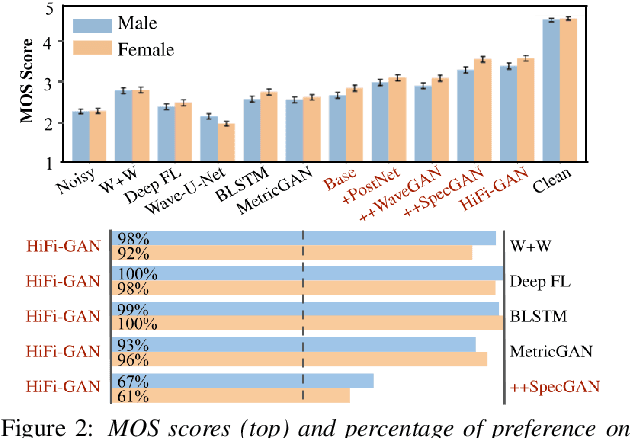
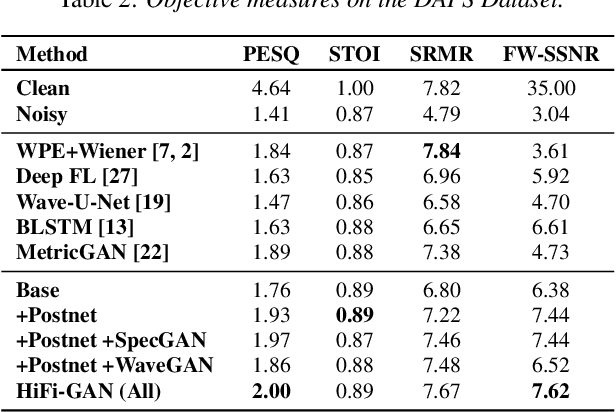
Real-world audio recordings are often degraded by factors such as noise, reverberation, and equalization distortion. This paper introduces HiFi-GAN, a deep learning method to transform recorded speech to sound as though it had been recorded in a studio. We use an end-to-end feed-forward WaveNet architecture, trained with multi-scale adversarial discriminators in both the time domain and the time-frequency domain. It relies on the deep feature matching losses of the discriminators to improve the perceptual quality of enhanced speech. The proposed model generalizes well to new speakers, new speech content, and new environments. It significantly outperforms state-of-the-art baseline methods in both objective and subjective experiments.