 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancements in Chinese font generation since deep learning era: A survey
Aug 09, 2025



Chinese font generation aims to create a new Chinese font library based on some reference samples. It is a topic of great concern to many font designers and typographers. Over the past years, with the rapid development of deep learning algorithms, various new techniques have achieved flourishing and thriving progress. Nevertheless, how to improve the overall quality of generated Chinese character images remains a tough issue. In this paper, we conduct a holistic survey of the recent Chinese font generation approaches based on deep learning. To be specific, we first illustrate the research background of the task. Then, we outline our literature selection and analysis methodology, and review a series of related fundamentals, including classical deep learning architectures, font representation formats, public datasets, and frequently-used evaluation metrics. After that, relying on the number of reference samples required to generate a new font, we categorize the existing methods into two major groups: many-shot font generation and few-shot font generation methods. Within each category, representative approaches are summarized, and their strengths and limitations are also discussed in detail. Finally, we conclude our paper with the challenges and future directions, with the expectation to provide some valuable illuminations for the researchers in this field.
Defending Spiking Neural Networks against Adversarial Attacks through Image Purification
Apr 26, 2024

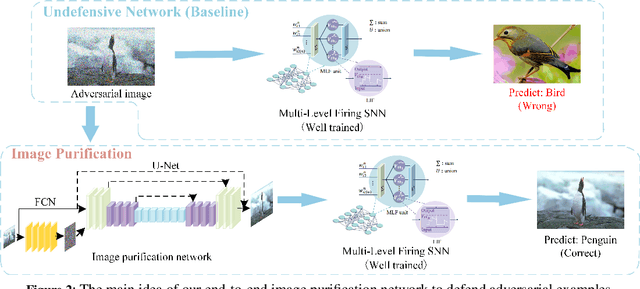
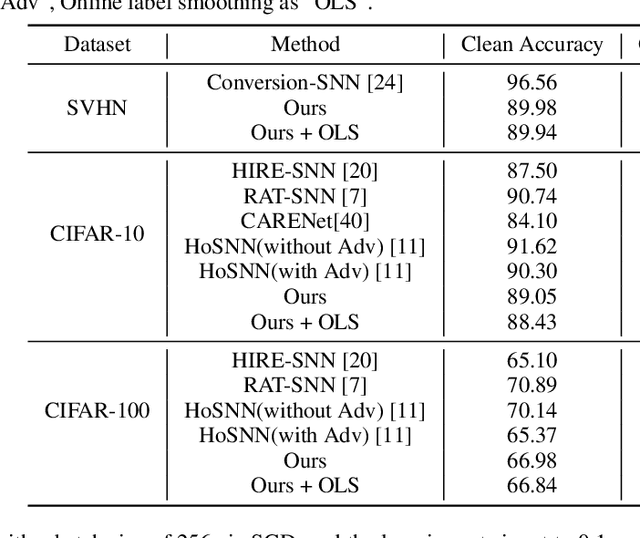
Spiking Neural Networks (SNNs) aim to bridge the gap between neuroscience and machine learning by emulating the structure of the human nervous system. However, like convolutional neural networks, SNNs are vulnerable to adversarial attacks. To tackle the challenge, we propose a biologically inspired methodology to enhance the robustness of SNNs, drawing insights from the visual masking effect and filtering theory. First, an end-to-end SNN-based image purification model is proposed to defend against adversarial attacks, including a noise extraction network and a non-blind denoising network. The former network extracts noise features from noisy images, while the latter component employs a residual U-Net structure to reconstruct high-quality noisy images and generate clean images. Simultaneously, a multi-level firing SNN based on Squeeze-and-Excitation Network is introduced to improve the robustness of the classifier. Crucially, the proposed image purification network serves as a pre-processing module, avoiding modifications to classifiers. Unlike adversarial training, our method is highly flexible and can be seamlessly integrated with other defense strategies. Experimental results on various datasets demonstrate that the proposed methodology outperforms state-of-the-art baselines in terms of defense effectiveness, training time, and resource consumption.
TARN-VIST: Topic Aware Reinforcement Network for Visual Storytelling
Mar 18, 2024



As a cross-modal task, visual storytelling aims to generate a story for an ordered image sequence automatically. Different from the image captioning task, visual storytelling requires not only modeling the relationships between objects in the image but also mining the connections between adjacent images. Recent approaches primarily utilize either end-to-end frameworks or multi-stage frameworks to generate relevant stories, but they usually overlook latent topic information. In this paper, in order to generate a more coherent and relevant story, we propose a novel method, Topic Aware Reinforcement Network for VIsual StoryTelling (TARN-VIST). In particular, we pre-extracted the topic information of stories from both visual and linguistic perspectives. Then we apply two topic-consistent reinforcement learning rewards to identify the discrepancy between the generated story and the human-labeled story so as to refine the whole generation process. Extensive experimental results on the VIST dataset and human evaluation demonstrate that our proposed model outperforms most of the competitive models across multiple evaluation metrics.