 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Ultra-Long-Horizon Agentic Science: Cognitive Accumulation for Machine Learning Engineering
Jan 15, 2026The advancement of artificial intelligence toward agentic science is currently bottlenecked by the challenge of ultra-long-horizon autonomy, the ability to sustain strategic coherence and iterative correction over experimental cycles spanning days or weeks. While Large Language Models (LLMs) have demonstrated prowess in short-horizon reasoning, they are easily overwhelmed by execution details in the high-dimensional, delayed-feedback environments of real-world research, failing to consolidate sparse feedback into coherent long-term guidance. Here, we present ML-Master 2.0, an autonomous agent that masters ultra-long-horizon machine learning engineering (MLE) which is a representative microcosm of scientific discovery. By reframing context management as a process of cognitive accumulation, our approach introduces Hierarchical Cognitive Caching (HCC), a multi-tiered architecture inspired by computer systems that enables the structural differentiation of experience over time. By dynamically distilling transient execution traces into stable knowledge and cross-task wisdom, HCC allows agents to decouple immediate execution from long-term experimental strategy, effectively overcoming the scaling limits of static context windows. In evaluations on OpenAI's MLE-Bench under 24-hour budgets, ML-Master 2.0 achieves a state-of-the-art medal rate of 56.44%. Our findings demonstrate that ultra-long-horizon autonomy provides a scalable blueprint for AI capable of autonomous exploration beyond human-precedent complexities.
Bohrium + SciMaster: Building the Infrastructure and Ecosystem for Agentic Science at Scale
Dec 23, 2025



AI agents are emerging as a practical way to run multi-step scientific workflows that interleave reasoning with tool use and verification, pointing to a shift from isolated AI-assisted steps toward \emph{agentic science at scale}. This shift is increasingly feasible, as scientific tools and models can be invoked through stable interfaces and verified with recorded execution traces, and increasingly necessary, as AI accelerates scientific output and stresses the peer-review and publication pipeline, raising the bar for traceability and credible evaluation. However, scaling agentic science remains difficult: workflows are hard to observe and reproduce; many tools and laboratory systems are not agent-ready; execution is hard to trace and govern; and prototype AI Scientist systems are often bespoke, limiting reuse and systematic improvement from real workflow signals. We argue that scaling agentic science requires an infrastructure-and-ecosystem approach, instantiated in Bohrium+SciMaster. Bohrium acts as a managed, traceable hub for AI4S assets -- akin to a HuggingFace of AI for Science -- that turns diverse scientific data, software, compute, and laboratory systems into agent-ready capabilities. SciMaster orchestrates these capabilities into long-horizon scientific workflows, on which scientific agents can be composed and executed. Between infrastructure and orchestration, a \emph{scientific intelligence substrate} organizes reusable models, knowledge, and components into executable building blocks for workflow reasoning and action, enabling composition, auditability, and improvement through use. We demonstrate this stack with eleven representative master agents in real workflows, achieving orders-of-magnitude reductions in end-to-end scientific cycle time and generating execution-grounded signals from real workloads at multi-million scale.
MASLab: A Unified and Comprehensive Codebase for LLM-based Multi-Agent Systems
May 22, 2025LLM-based multi-agent systems (MAS) have demonstrated significant potential in enhancing single LLMs to address complex and diverse tasks in practical applications. Despite considerable advancements, the field lacks a unified codebase that consolidates existing methods, resulting in redundant re-implementation efforts, unfair comparisons, and high entry barriers for researchers. To address these challenges, we introduce MASLab, a unified, comprehensive, and research-friendly codebase for LLM-based MAS. (1) MASLab integrates over 20 established methods across multiple domains, each rigorously validated by comparing step-by-step outputs with its official implementation. (2) MASLab provides a unified environment with various benchmarks for fair comparisons among methods, ensuring consistent inputs and standardized evaluation protocols. (3) MASLab implements methods within a shared streamlined structure, lowering the barriers for understanding and extension. Building on MASLab, we conduct extensive experiments covering 10+ benchmarks and 8 models, offering researchers a clear and comprehensive view of the current landscape of MAS methods. MASLab will continue to evolve, tracking the latest developments in the field, and invite contributions from the broader open-source community.
SWE-Dev: Evaluating and Training Autonomous Feature-Driven Software Development
May 22, 2025Large Language Models (LLMs) have shown strong capability in diverse software engineering tasks, e.g. code completion, bug fixing, and document generation. However, feature-driven development (FDD), a highly prevalent real-world task that involves developing new functionalities for large, existing codebases, remains underexplored. We therefore introduce SWE-Dev, the first large-scale dataset (with 14,000 training and 500 test samples) designed to evaluate and train autonomous coding systems on real-world feature development tasks. To ensure verifiable and diverse training, SWE-Dev uniquely provides all instances with a runnable environment and its developer-authored executable unit tests. This collection not only provides high-quality data for Supervised Fine-Tuning (SFT), but also enables Reinforcement Learning (RL) by delivering accurate reward signals from executable unit tests. Our extensive evaluations on SWE-Dev, covering 17 chatbot LLMs, 10 reasoning models, and 10 Multi-Agent Systems (MAS), reveal that FDD is a profoundly challenging frontier for current AI (e.g., Claude-3.7-Sonnet achieves only 22.45\% Pass@3 on the hard test split). Crucially, we demonstrate that SWE-Dev serves as an effective platform for model improvement: fine-tuning on training set enabled a 7B model comparable to GPT-4o on \textit{hard} split, underscoring the value of its high-quality training data. Code is available here \href{https://github.com/justLittleWhite/SWE-Dev}{https://github.com/justLittleWhite/SWE-Dev}.
Self-Evolving Multi-Agent Collaboration Networks for Software Development
Oct 22, 2024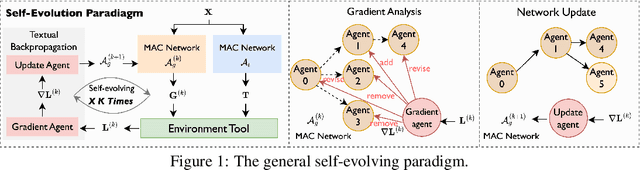


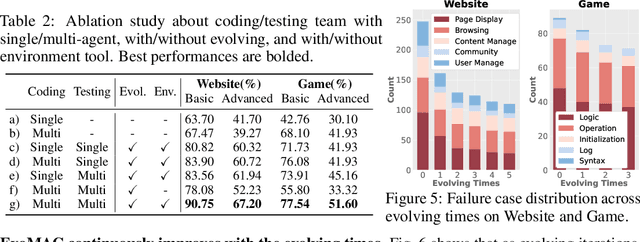
LLM-driven multi-agent collaboration (MAC) systems have demonstrated impressive capabilities in automatic software development at the function level. However, their heavy reliance on human design limits their adaptability to the diverse demands of real-world software development. To address this limitation, we introduce EvoMAC, a novel self-evolving paradigm for MAC networks. Inspired by traditional neural network training, EvoMAC obtains text-based environmental feedback by verifying the MAC network's output against a target proxy and leverages a novel textual backpropagation to update the network. To extend coding capabilities beyond function-level tasks to more challenging software-level development, we further propose rSDE-Bench, a requirement-oriented software development benchmark, which features complex and diverse software requirements along with automatic evaluation of requirement correctness. Our experiments show that: i) The automatic requirement-aware evaluation in rSDE-Bench closely aligns with human evaluations, validating its reliability as a software-level coding benchmark. ii) EvoMAC outperforms previous SOTA methods on both the software-level rSDE-Bench and the function-level HumanEval benchmarks, reflecting its superior coding capabilities. The benchmark can be downloaded at https://yuzhu-cai.github.io/rSDE-Bench/.
Ethical-Lens: Curbing Malicious Usages of Open-Source Text-to-Image Models
Apr 18, 2024



The burgeoning landscape of text-to-image models, exemplified by innovations such as Midjourney and DALLE 3, has revolutionized content creation across diverse sectors. However, these advancements bring forth critical ethical concerns, particularly with the misuse of open-source models to generate content that violates societal norms. Addressing this, we introduce Ethical-Lens, a framework designed to facilitate the value-aligned usage of text-to-image tools without necessitating internal model revision. Ethical-Lens ensures value alignment in text-to-image models across toxicity and bias dimensions by refining user commands and rectifying model outputs. Systematic evaluation metrics, combining GPT4-V, HEIM, and FairFace scores, assess alignment capability. Our experiments reveal that Ethical-Lens enhances alignment capabilities to levels comparable with or superior to commercial models like DALLE 3, ensuring user-generated content adheres to ethical standards while maintaining image quality. This study indicates the potential of Ethical-Lens to ensure the sustainable development of open-source text-to-image tools and their beneficial integration into society. Our code is available at https://github.com/yuzhu-cai/Ethical-Lens.