 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Impact of Data and Model Scaling on High-Level Control for Humanoid Robots
Nov 12, 2025
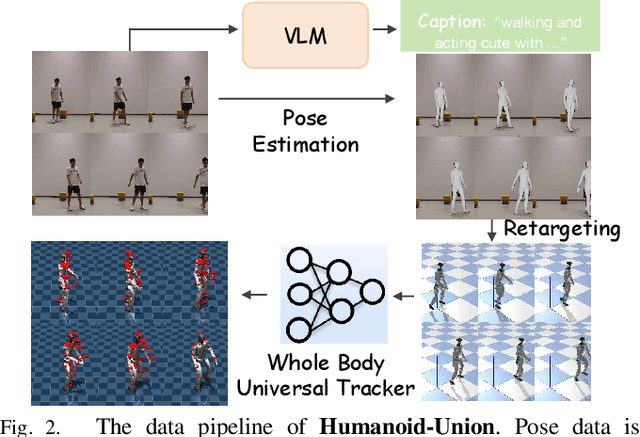
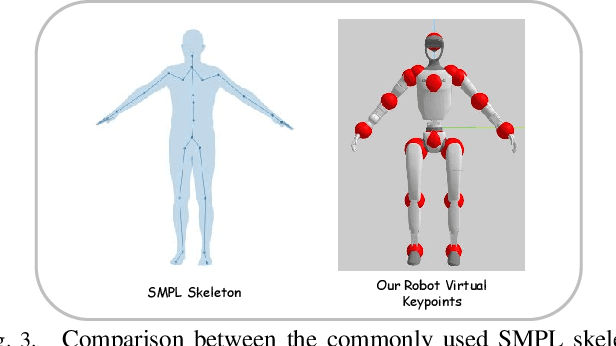
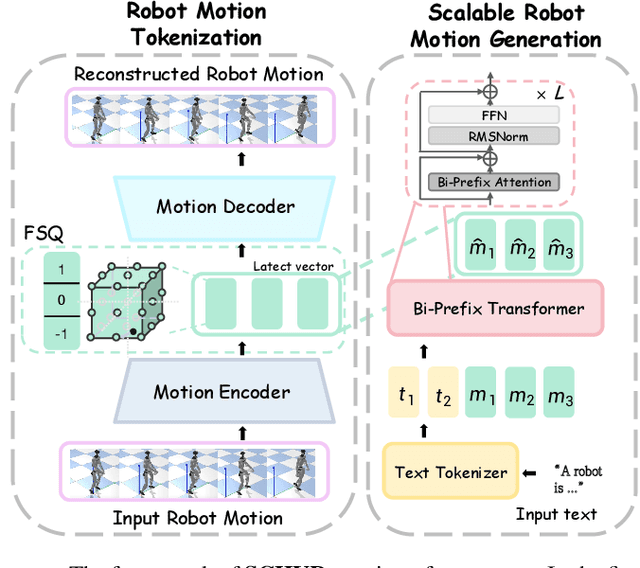
Data scaling has long remained a critical bottleneck in robot learning. For humanoid robots, human videos and motion data are abundant and widely available, offering a free and large-scale data source. Besides, the semantics related to the motions enable modality alignment and high-level robot control learning. However, how to effectively mine raw video, extract robot-learnable representations, and leverage them for scalable learning remains an open problem. To address this, we introduce Humanoid-Union, a large-scale dataset generated through an autonomous pipeline, comprising over 260 hours of diverse, high-quality humanoid robot motion data with semantic annotations derived from human motion videos. The dataset can be further expanded via the same pipeline. Building on this data resource, we propose SCHUR, a scalable learning framework designed to explore the impact of large-scale data on high-level control in humanoid robots. Experimental results demonstrate that SCHUR achieves high robot motion generation quality and strong text-motion alignment under data and model scaling, with 37\% reconstruction improvement under MPJPE and 25\% alignment improvement under FID comparing with previous methods. Its effectiveness is further validated through deployment in real-world humanoid robot.
ChatDyn: Language-Driven Multi-Actor Dynamics Generation in Street Scenes
Dec 11, 2024Generating realistic and interactive dynamics of traffic participants according to specific instruction is critical for street scene simulation. However, there is currently a lack of a comprehensive method that generates realistic dynamics of different types of participants including vehicles and pedestrians, with different kinds of interactions between them. In this paper, we introduce ChatDyn, the first system capable of generating interactive, controllable and realistic participant dynamics in street scenes based on language instructions. To achieve precise control through complex language, ChatDyn employs a multi-LLM-agent role-playing approach, which utilizes natural language inputs to plan the trajectories and behaviors for different traffic participants. To generate realistic fine-grained dynamics based on the planning, ChatDyn designs two novel executors: the PedExecutor, a unified multi-task executor that generates realistic pedestrian dynamics under different task plannings; and the VehExecutor, a physical transition-based policy that generates physically plausible vehicle dynamics. Extensive experiments show that ChatDyn can generate realistic driving scene dynamics with multiple vehicles and pedestrians, and significantly outperforms previous methods on subtasks. Code and model will be available at https://vfishc.github.io/chatdyn.
Ethical-Lens: Curbing Malicious Usages of Open-Source Text-to-Image Models
Apr 18, 2024



The burgeoning landscape of text-to-image models, exemplified by innovations such as Midjourney and DALLE 3, has revolutionized content creation across diverse sectors. However, these advancements bring forth critical ethical concerns, particularly with the misuse of open-source models to generate content that violates societal norms. Addressing this, we introduce Ethical-Lens, a framework designed to facilitate the value-aligned usage of text-to-image tools without necessitating internal model revision. Ethical-Lens ensures value alignment in text-to-image models across toxicity and bias dimensions by refining user commands and rectifying model outputs. Systematic evaluation metrics, combining GPT4-V, HEIM, and FairFace scores, assess alignment capability. Our experiments reveal that Ethical-Lens enhances alignment capabilities to levels comparable with or superior to commercial models like DALLE 3, ensuring user-generated content adheres to ethical standards while maintaining image quality. This study indicates the potential of Ethical-Lens to ensure the sustainable development of open-source text-to-image tools and their beneficial integration into society. Our code is available at https://github.com/yuzhu-cai/Ethical-Lens.
Editable Scene Simulation for Autonomous Driving via Collaborative LLM-Agents
Feb 08, 2024Scene simulation in autonomous driving has gained significant attention because of its huge potential for generating customized data. However, existing editable scene simulation approaches face limitations in terms of user interaction efficiency, multi-camera photo-realistic rendering and external digital assets integration. To address these challenges, this paper introduces ChatSim, the first system that enables editable photo-realistic 3D driving scene simulations via natural language commands with external digital assets. To enable editing with high command flexibility,~ChatSim leverages a large language model (LLM) agent collaboration framework. To generate photo-realistic outcomes, ChatSim employs a novel multi-camera neural radiance field method. Furthermore, to unleash the potential of extensive high-quality digital assets, ChatSim employs a novel multi-camera lighting estimation method to achieve scene-consistent assets' rendering. Our experiments on Waymo Open Dataset demonstrate that ChatSim can handle complex language commands and generate corresponding photo-realistic scene videos.
Compatible Transformer for Irregularly Sampled Multivariate Time Series
Oct 17, 2023



To analyze multivariate time series, most previous methods assume regular subsampling of time series, where the interval between adjacent measurements and the number of samples remain unchanged. Practically, data collection systems could produce irregularly sampled time series due to sensor failures and interventions. However, existing methods designed for regularly sampled multivariate time series cannot directly handle irregularity owing to misalignment along both temporal and variate dimensions. To fill this gap, we propose Compatible Transformer (CoFormer), a transformer-based encoder to achieve comprehensive temporal-interaction feature learning for each individual sample in irregular multivariate time series. In CoFormer, we view each sample as a unique variate-time point and leverage intra-variate/inter-variate attentions to learn sample-wise temporal/interaction features based on intra-variate/inter-variate neighbors. With CoFormer as the core, we can analyze irregularly sampled multivariate time series for many downstream tasks, including classification and prediction. We conduct extensive experiments on 3 real-world datasets and validate that the proposed CoFormer significantly and consistently outperforms existing methods.
Asynchrony-Robust Collaborative Perception via Bird's Eye View Flow
Oct 09, 2023



Collaborative perception can substantially boost each agent's perception ability by facilitating communication among multiple agents. However, temporal asynchrony among agents is inevitable in the real world due to communication delays, interruptions, and clock misalignments. This issue causes information mismatch during multi-agent fusion, seriously shaking the foundation of collaboration. To address this issue, we propose CoBEVFlow, an asynchrony-robust collaborative perception system based on bird's eye view (BEV) flow. The key intuition of CoBEVFlow is to compensate motions to align asynchronous collaboration messages sent by multiple agents. To model the motion in a scene, we propose BEV flow, which is a collection of the motion vector corresponding to each spatial location. Based on BEV flow, asynchronous perceptual features can be reassigned to appropriate positions, mitigating the impact of asynchrony. CoBEVFlow has two advantages: (i) CoBEVFlow can handle asynchronous collaboration messages sent at irregular, continuous time stamps without discretization; and (ii) with BEV flow, CoBEVFlow only transports the original perceptual features, instead of generating new perceptual features, avoiding additional noises. To validate CoBEVFlow's efficacy, we create IRregular V2V(IRV2V), the first synthetic collaborative perception dataset with various temporal asynchronies that simulate different real-world scenarios. Extensive experiments conducted on both IRV2V and the real-world dataset DAIR-V2X show that CoBEVFlow consistently outperforms other baselines and is robust in extremely asynchronous settings. The code is available at https://github.com/MediaBrain-SJTU/CoBEVFlow.
Dynamic-Group-Aware Networks for Multi-Agent Trajectory Prediction with Relational Reasoning
Jun 27, 2022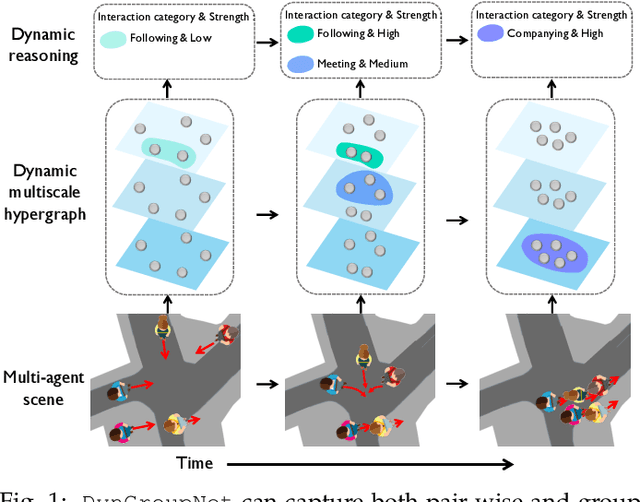

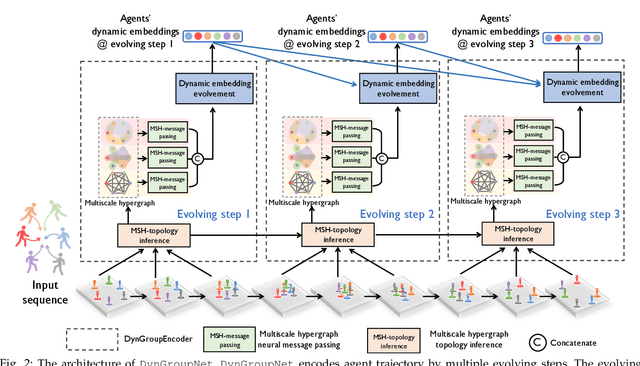

Demystifying the interactions among multiple agents from their past trajectories is fundamental to precise and interpretable trajectory prediction. However, previous works mainly consider static, pair-wise interactions with limited relational reasoning. To promote more comprehensive interaction modeling and relational reasoning, we propose DynGroupNet, a dynamic-group-aware network, which can i) model time-varying interactions in highly dynamic scenes; ii) capture both pair-wise and group-wise interactions; and iii) reason both interaction strength and category without direct supervision. Based on DynGroupNet, we further design a prediction system to forecast socially plausible trajectories with dynamic relational reasoning. The proposed prediction system leverages the Gaussian mixture model, multiple sampling and prediction refinement to promote prediction diversity, training stability and trajectory smoothness, respectively. Extensive experiments show that: 1)DynGroupNet can capture time-varying group behaviors, infer time-varying interaction category and interaction strength during trajectory prediction without any relation supervision on physical simulation datasets; 2)DynGroupNet outperforms the state-of-the-art trajectory prediction methods by a significant improvement of 22.6%/28.0%, 26.9%/34.9%, 5.1%/13.0% in ADE/FDE on the NBA, NFL Football and SDD datasets and achieve the state-of-the-art performance on the ETH-UCY dataset.