 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinking Modality Isolation in Heterogeneous Collaborative Perception
Feb 28, 2026Collaborative perception leverages data exchange among multiple agents to enhance overall perception capabilities. However, heterogeneity across agents introduces domain gaps that hinder collaboration, and this is further exacerbated by an underexplored issue: modality isolation. It arises when multiple agents with different modalities never co-occur in any training data frame, enlarging cross-modal domain gaps. Existing alignment methods rely on supervision from spatially overlapping observations, thus fail to handle modality isolation. To address this challenge, we propose CodeAlign, the first efficient, co-occurrence-free alignment framework that smoothly aligns modalities via cross-modal feature-code-feature(FCF) translation. The key idea is to explicitly identify the representation consistency through codebook, and directly learn mappings between modality-specific feature spaces, thereby eliminating the need for spatial correspondence. Codebooks regularize feature spaces into code spaces, providing compact yet expressive representations. With a prepared code space for each modality, CodeAlign learns FCF translations that map features to the corresponding codes of other modalities, which are then decoded back into features in the target code space, enabling effective alignment. Experiments show that, when integrating three modalities, CodeAlign requires only 8% of the training parameters of prior alignment methods, reduces communication load by 1024x, and achieves state-of-the-art perception performance on both OPV2V and DAIR-V2X dataset. Code will be released on https://github.com/cxliu0314/CodeAlign.
CoLMDriver: LLM-based Negotiation Benefits Cooperative Autonomous Driving
Mar 11, 2025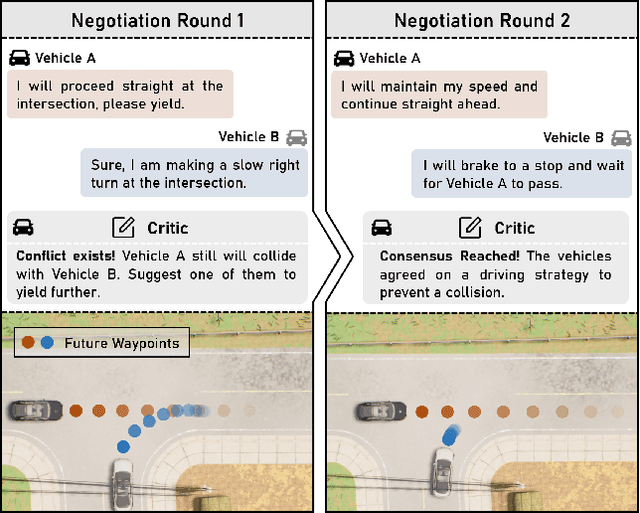
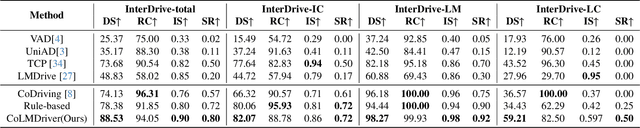
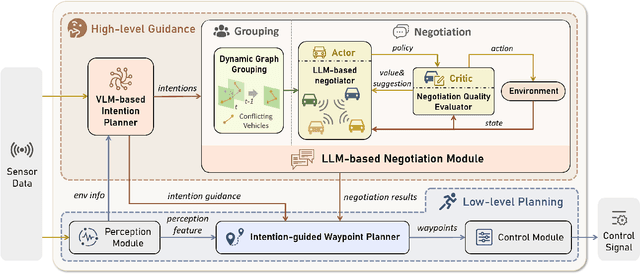
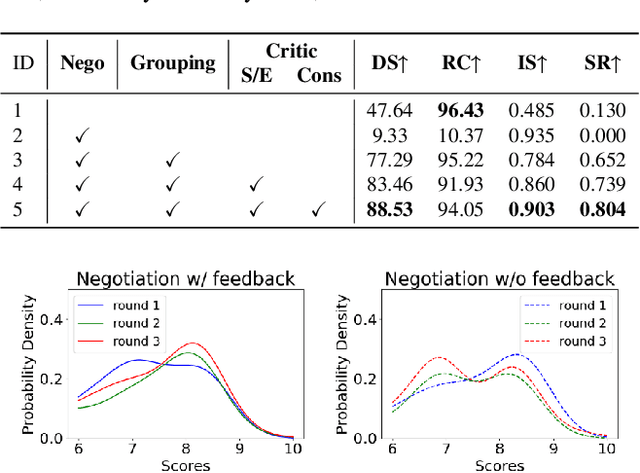
Vehicle-to-vehicle (V2V) cooperative autonomous driving holds great promise for improving safety by addressing the perception and prediction uncertainties inherent in single-agent systems. However, traditional cooperative methods are constrained by rigid collaboration protocols and limited generalization to unseen interactive scenarios. While LLM-based approaches offer generalized reasoning capabilities, their challenges in spatial planning and unstable inference latency hinder their direct application in cooperative driving. To address these limitations, we propose CoLMDriver, the first full-pipeline LLM-based cooperative driving system, enabling effective language-based negotiation and real-time driving control. CoLMDriver features a parallel driving pipeline with two key components: (i) an LLM-based negotiation module under an actor-critic paradigm, which continuously refines cooperation policies through feedback from previous decisions of all vehicles; and (ii) an intention-guided waypoint generator, which translates negotiation outcomes into executable waypoints. Additionally, we introduce InterDrive, a CARLA-based simulation benchmark comprising 10 challenging interactive driving scenarios for evaluating V2V cooperation. Experimental results demonstrate that CoLMDriver significantly outperforms existing approaches, achieving an 11% higher success rate across diverse highly interactive V2V driving scenarios. Code will be released on https://github.com/cxliu0314/CoLMDriver.
Editable Scene Simulation for Autonomous Driving via Collaborative LLM-Agents
Feb 08, 2024



Scene simulation in autonomous driving has gained significant attention because of its huge potential for generating customized data. However, existing editable scene simulation approaches face limitations in terms of user interaction efficiency, multi-camera photo-realistic rendering and external digital assets integration. To address these challenges, this paper introduces ChatSim, the first system that enables editable photo-realistic 3D driving scene simulations via natural language commands with external digital assets. To enable editing with high command flexibility,~ChatSim leverages a large language model (LLM) agent collaboration framework. To generate photo-realistic outcomes, ChatSim employs a novel multi-camera neural radiance field method. Furthermore, to unleash the potential of extensive high-quality digital assets, ChatSim employs a novel multi-camera lighting estimation method to achieve scene-consistent assets' rendering. Our experiments on Waymo Open Dataset demonstrate that ChatSim can handle complex language commands and generate corresponding photo-realistic scene videos.