 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatDyn: Language-Driven Multi-Actor Dynamics Generation in Street Scenes
Dec 11, 2024Generating realistic and interactive dynamics of traffic participants according to specific instruction is critical for street scene simulation. However, there is currently a lack of a comprehensive method that generates realistic dynamics of different types of participants including vehicles and pedestrians, with different kinds of interactions between them. In this paper, we introduce ChatDyn, the first system capable of generating interactive, controllable and realistic participant dynamics in street scenes based on language instructions. To achieve precise control through complex language, ChatDyn employs a multi-LLM-agent role-playing approach, which utilizes natural language inputs to plan the trajectories and behaviors for different traffic participants. To generate realistic fine-grained dynamics based on the planning, ChatDyn designs two novel executors: the PedExecutor, a unified multi-task executor that generates realistic pedestrian dynamics under different task plannings; and the VehExecutor, a physical transition-based policy that generates physically plausible vehicle dynamics. Extensive experiments show that ChatDyn can generate realistic driving scene dynamics with multiple vehicles and pedestrians, and significantly outperforms previous methods on subtasks. Code and model will be available at https://vfishc.github.io/chatdyn.
Self-Localized Collaborative Perception
Jun 18, 2024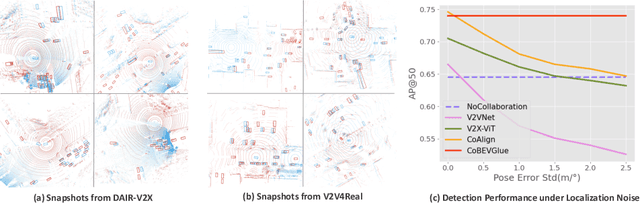
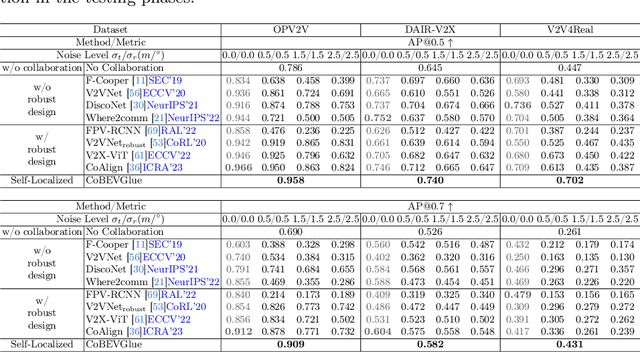


Collaborative perception has garnered considerable attention due to its capacity to address several inherent challenges in single-agent perception, including occlusion and out-of-range issues. However, existing collaborative perception systems heavily rely on precise localization systems to establish a consistent spatial coordinate system between agents. This reliance makes them susceptible to large pose errors or malicious attacks, resulting in substantial reductions in perception performance. To address this, we propose~$\mathtt{CoBEVGlue}$, a novel self-localized collaborative perception system, which achieves more holistic and robust collaboration without using an external localization system. The core of~$\mathtt{CoBEVGlue}$ is a novel spatial alignment module, which provides the relative poses between agents by effectively matching co-visible objects across agents. We validate our method on both real-world and simulated datasets. The results show that i) $\mathtt{CoBEVGlue}$ achieves state-of-the-art detection performance under arbitrary localization noises and attacks; and ii) the spatial alignment module can seamlessly integrate with a majority of previous methods, enhancing their performance by an average of $57.7\%$. Code is available at https://github.com/VincentNi0107/CoBEVGlue