 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
May 28, 2026Embodied intelligence is often studied through specialized models for individual tasks such as manipulation or navigation, resulting in fragmented capabilities and limited generalization across tasks, environments, and robot embodiments. In this work, we study whether heterogeneous embodied decision-making problems can be unified within a single vision-language-action model. We present Qwen-VLA, a unified embodied foundation model that extends Qwen's vision-language modeling stack from perception, understanding, and reasoning to continuous action and trajectory generation through a DiT-based action decoder. Qwen-VLA is trained with a large-scale joint pretraining recipe over diverse data sources, including robotics manipulation trajectories, human egocentric demonstrations, synthetic simulation data, vision-and-language navigation data, trajectory-centric supervision, and auxiliary vision-language data. To support multiple robot platforms, we introduce embodiment-aware prompt conditioning, where robot-specific textual descriptions specify the current embodiment and control convention. We further cast manipulation, navigation, and trajectory prediction into a unified action-and-trajectory prediction framework, enabling transferable visual grounding, spatial reasoning, and continuous action generation across robot morphologies, task families, and environments. Experiments on manipulation, navigation, and trajectory-centric benchmarks show consistent multi-task performance and out-of-distribution generalization under variations in scene layout, background, lighting, object configuration, and robot embodiment. Qwen-VLA-Instruct achieves 97.9% on LIBERO, 73.7% on Simpler-WidowX, 86.1%/87.2% on RoboTwin-Easy/Hard, 69.0% OSR on R2R, 59.6% SR on RxR, 76.9% average OOD success in real-world ALOHA experiments, and 26.6% zero-shot success on DOMINO dynamic manipulation.
Towards Long-horizon Embodied Agents with Tool-Aligned Vision-Language-Action Models
May 13, 2026Vision-language-action (VLA) models are effective robot action executors, but they remain limited on long-horizon tasks due to the dual burden of extended closed-loop planning and diverse physical operations. We therefore propose VLAs-as-Tools, a strategy that distributes this burden across a high-level vision language model (VLM) agent for temporal reasoning and a family of specialized VLA tools for diverse local physical operations. The VLM handles scene analysis, global planning, and recovery, while each VLA tool executes a bounded subtask. To tightly couple agent planning with VLA tool execution in long-horizon tasks, we introduce a VLA tool-family interface that exposes explicit tool selection and in-execution progress feedback, enabling efficient event-triggered agent replanning without continuous agent polling. To obtain diverse specialized VLA tools that faithfully follow agent invocations, we further propose Tool-Aligned Post-Training (TAPT), which constructs invocation-aligned training units for instruction following and adopts tool-family residual adapters for efficient tool specialization. Experiments show that VLAs-as-Tools improves the success rate of $π_{0.5}$ by 4.8 points on LIBERO-Long and 23.1 points on RoboTwin, and further enhances invocation fidelity by 15.0 points as measured by Non-biased Rate. Code will be released.
DataMaster: Towards Autonomous Data Engineering for Machine Learning
May 11, 2026As model families, training recipes, and compute budgets become increasingly standardized, further gains in machine learning systems depend increasingly on data. Yet data engineering remains largely manual and ad hoc: practitioners repeatedly search for external datasets, adapt them to existing pipelines, validate candidate data through downstream training, and carry forward lessons from prior attempts. We study task-conditioned autonomous data engineering, where an autonomous agent improves a fixed learning algorithm by optimizing only the data side, including external data discovery, data selection and composition, cleaning and transformation. The goal is to obtain a stronger downstream solution while leaving the learning algorithm unchanged. To address the open-ended search space, branch-dependent refinement, and delayed validation inherent in autonomous data engineering, we propose DataMaster, a data-agent framework that integrates tree-structured search, shared candidate data, and cumulative memory. DataMaster consists of three key components: a DataTree that organizes alternative data-engineering branches, a shared Data Pool that stores discovered external data sources for reuse, and a Global Memory that records node outcomes, artifacts, and reusable findings. Together, these components allow the agent to discover candidate data, construct executable training inputs, evaluate them through downstream feedback, and carry useful evidence across branches. We evaluate DataMaster on two types of benchmarks, MLE-Bench Lite and PostTrainBench. On MLE-Bench Lite, it improves medal rate by 32.27% over the initial score; on PostTrainBench, it surpasses the instruct model on GPQA (31.02% vs 30.35%).
EmboCoach-Bench: Benchmarking AI Agents on Developing Embodied Robots
Jan 29, 2026The field of Embodied AI is witnessing a rapid evolution toward general-purpose robotic systems, fueled by high-fidelity simulation and large-scale data collection. However, this scaling capability remains severely bottlenecked by a reliance on labor-intensive manual oversight from intricate reward shaping to hyperparameter tuning across heterogeneous backends. Inspired by LLMs' success in software automation and science discovery, we introduce \textsc{EmboCoach-Bench}, a benchmark evaluating the capacity of LLM agents to autonomously engineer embodied policies. Spanning 32 expert-curated RL and IL tasks, our framework posits executable code as the universal interface. We move beyond static generation to assess a dynamic closed-loop workflow, where agents leverage environment feedback to iteratively draft, debug, and optimize solutions, spanning improvements from physics-informed reward design to policy architectures such as diffusion policies. Extensive evaluations yield three critical insights: (1) autonomous agents can qualitatively surpass human-engineered baselines by 26.5\% in average success rate; (2) agentic workflow with environment feedback effectively strengthens policy development and substantially narrows the performance gap between open-source and proprietary models; and (3) agents exhibit self-correction capabilities for pathological engineering cases, successfully resurrecting task performance from near-total failures through iterative simulation-in-the-loop debugging. Ultimately, this work establishes a foundation for self-evolving embodied intelligence, accelerating the paradigm shift from labor-intensive manual tuning to scalable, autonomous engineering in embodied AI field.
Bohrium + SciMaster: Building the Infrastructure and Ecosystem for Agentic Science at Scale
Dec 23, 2025



AI agents are emerging as a practical way to run multi-step scientific workflows that interleave reasoning with tool use and verification, pointing to a shift from isolated AI-assisted steps toward \emph{agentic science at scale}. This shift is increasingly feasible, as scientific tools and models can be invoked through stable interfaces and verified with recorded execution traces, and increasingly necessary, as AI accelerates scientific output and stresses the peer-review and publication pipeline, raising the bar for traceability and credible evaluation. However, scaling agentic science remains difficult: workflows are hard to observe and reproduce; many tools and laboratory systems are not agent-ready; execution is hard to trace and govern; and prototype AI Scientist systems are often bespoke, limiting reuse and systematic improvement from real workflow signals. We argue that scaling agentic science requires an infrastructure-and-ecosystem approach, instantiated in Bohrium+SciMaster. Bohrium acts as a managed, traceable hub for AI4S assets -- akin to a HuggingFace of AI for Science -- that turns diverse scientific data, software, compute, and laboratory systems into agent-ready capabilities. SciMaster orchestrates these capabilities into long-horizon scientific workflows, on which scientific agents can be composed and executed. Between infrastructure and orchestration, a \emph{scientific intelligence substrate} organizes reusable models, knowledge, and components into executable building blocks for workflow reasoning and action, enabling composition, auditability, and improvement through use. We demonstrate this stack with eleven representative master agents in real workflows, achieving orders-of-magnitude reductions in end-to-end scientific cycle time and generating execution-grounded signals from real workloads at multi-million scale.
PolySim: Bridging the Sim-to-Real Gap for Humanoid Control via Multi-Simulator Dynamics Randomization
Oct 02, 2025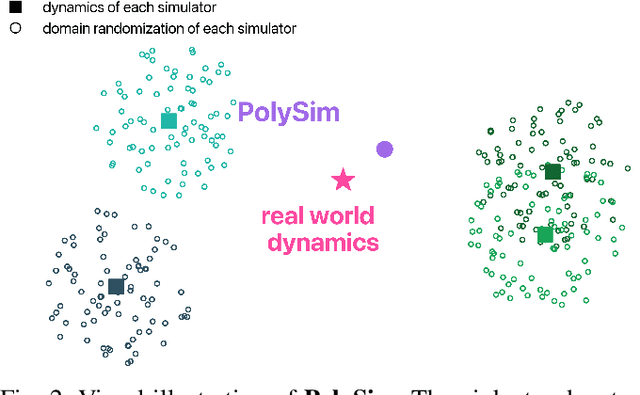
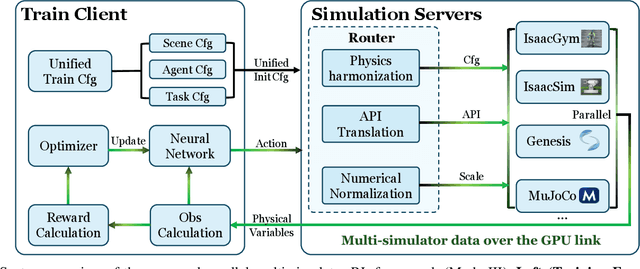
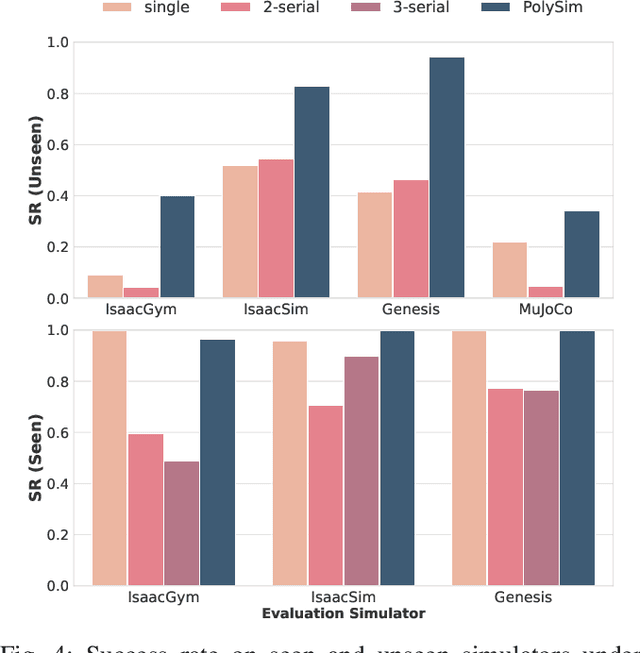

Humanoid whole-body control (WBC) policies trained in simulation often suffer from the sim-to-real gap, which fundamentally arises from simulator inductive bias, the inherent assumptions and limitations of any single simulator. These biases lead to nontrivial discrepancies both across simulators and between simulation and the real world. To mitigate the effect of simulator inductive bias, the key idea is to train policies jointly across multiple simulators, encouraging the learned controller to capture dynamics that generalize beyond any single simulator's assumptions. We thus introduce PolySim, a WBC training platform that integrates multiple heterogeneous simulators. PolySim can launch parallel environments from different engines simultaneously within a single training run, thereby realizing dynamics-level domain randomization. Theoretically, we show that PolySim yields a tighter upper bound on simulator inductive bias than single-simulator training. In experiments, PolySim substantially reduces motion-tracking error in sim-to-sim evaluations; for example, on MuJoCo, it improves execution success by 52.8 over an IsaacSim baseline. PolySim further enables zero-shot deployment on a real Unitree G1 without additional fine-tuning, showing effective transfer from simulation to the real world. We will release the PolySim code upon acceptance of this work.
Self-Localized Collaborative Perception
Jun 18, 2024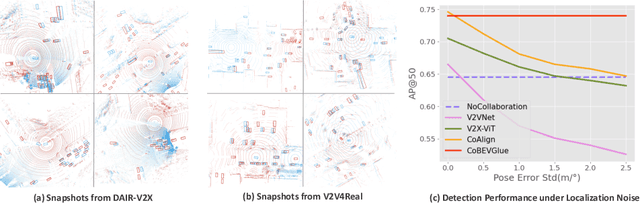
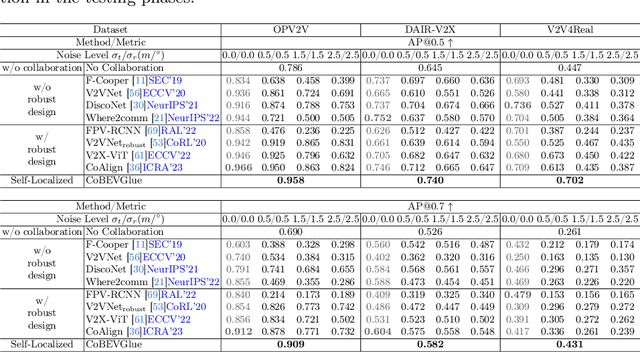


Collaborative perception has garnered considerable attention due to its capacity to address several inherent challenges in single-agent perception, including occlusion and out-of-range issues. However, existing collaborative perception systems heavily rely on precise localization systems to establish a consistent spatial coordinate system between agents. This reliance makes them susceptible to large pose errors or malicious attacks, resulting in substantial reductions in perception performance. To address this, we propose~$\mathtt{CoBEVGlue}$, a novel self-localized collaborative perception system, which achieves more holistic and robust collaboration without using an external localization system. The core of~$\mathtt{CoBEVGlue}$ is a novel spatial alignment module, which provides the relative poses between agents by effectively matching co-visible objects across agents. We validate our method on both real-world and simulated datasets. The results show that i) $\mathtt{CoBEVGlue}$ achieves state-of-the-art detection performance under arbitrary localization noises and attacks; and ii) the spatial alignment module can seamlessly integrate with a majority of previous methods, enhancing their performance by an average of $57.7\%$. Code is available at https://github.com/VincentNi0107/CoBEVGlue
Robust Collaborative Perception without External Localization and Clock Devices
May 05, 2024



A consistent spatial-temporal coordination across multiple agents is fundamental for collaborative perception, which seeks to improve perception abilities through information exchange among agents. To achieve this spatial-temporal alignment, traditional methods depend on external devices to provide localization and clock signals. However, hardware-generated signals could be vulnerable to noise and potentially malicious attack, jeopardizing the precision of spatial-temporal alignment. Rather than relying on external hardwares, this work proposes a novel approach: aligning by recognizing the inherent geometric patterns within the perceptual data of various agents. Following this spirit, we propose a robust collaborative perception system that operates independently of external localization and clock devices. The key module of our system,~\emph{FreeAlign}, constructs a salient object graph for each agent based on its detected boxes and uses a graph neural network to identify common subgraphs between agents, leading to accurate relative pose and time. We validate \emph{FreeAlign} on both real-world and simulated datasets. The results show that, the ~\emph{FreeAlign} empowered robust collaborative perception system perform comparably to systems relying on precise localization and clock devices.
Emergent Communication in Interactive Sketch Question Answering
Oct 24, 2023
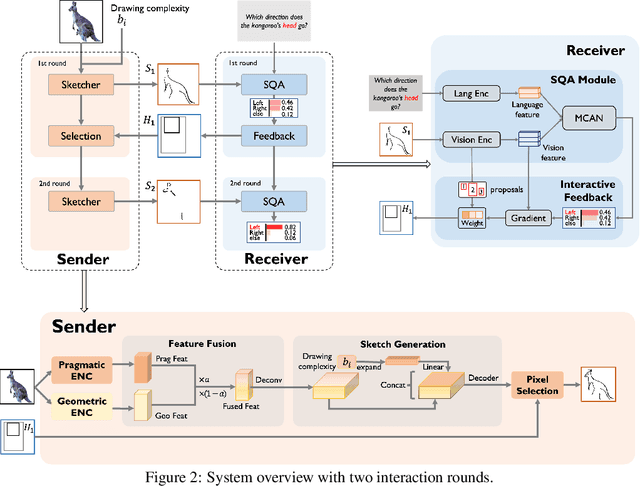

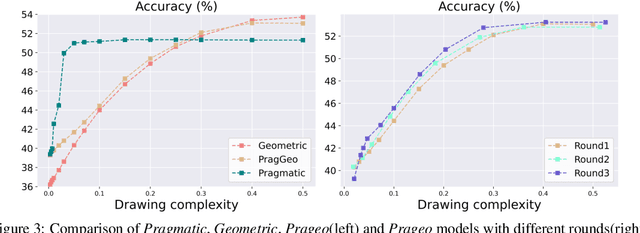
Vision-based emergent communication (EC) aims to learn to communicate through sketches and demystify the evolution of human communication. Ironically, previous works neglect multi-round interaction, which is indispensable in human communication. To fill this gap, we first introduce a novel Interactive Sketch Question Answering (ISQA) task, where two collaborative players are interacting through sketches to answer a question about an image in a multi-round manner. To accomplish this task, we design a new and efficient interactive EC system, which can achieve an effective balance among three evaluation factors, including the question answering accuracy, drawing complexity and human interpretability. Our experimental results including human evaluation demonstrate that multi-round interactive mechanism facilitates targeted and efficient communication between intelligent agents with decent human interpretability.
Interruption-Aware Cooperative Perception for V2X Communication-Aided Autonomous Driving
Apr 24, 2023Cooperative perception enabled by V2X Communication technologies can significantly improve the perception performance of autonomous vehicles beyond the limited perception ability of the individual vehicles, therefore, improving the safety and efficiency of autonomous driving in intelligent transportation systems. However, in order to fully reap the benefits of cooperative perception in practice, the impacts of imperfect V2X communication, i.e., communication errors and disruptions, need to be understood and effective remedies need to be developed to alleviate their adverse impacts. Motivated by this need, we propose a novel INterruption-aware robust COoperative Perception (V2X-INCOP) solution for V2X communication-aided autonomous driving, which leverages historical information to recover missing information due to interruption. To achieve comprehensive recovery, we design a communication adaptive multi-scale spatial-temporal prediction model to extract multi-scale spatial-temporal features based on V2X communication conditions and capture the most significant information for the prediction of the missing information. To further improve recovery performance, we adopt a knowledge distillation framework to give direct supervision to the prediction model and a curriculum learning strategy to stabilize the training of the model. Our experiments on three public cooperative perception datasets demonstrate that our proposed method is effective in alleviating the impacts of communication interruption on cooperative perception.