 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIPVehicle: A Unified Framework for Vision-based Vehicle Search
Aug 06, 2025



Vehicles, as one of the most common and significant objects in the real world, the researches on which using computer vision technologies have made remarkable progress, such as vehicle detection, vehicle re-identification, etc. To search an interested vehicle from the surveillance videos, existing methods first pre-detect and store all vehicle patches, and then apply vehicle re-identification models, which is resource-intensive and not very practical. In this work, we aim to achieve the joint detection and re-identification for vehicle search. However, the conflicting objectives between detection that focuses on shared vehicle commonness and re-identification that focuses on individual vehicle uniqueness make it challenging for a model to learn in an end-to-end system. For this problem, we propose a new unified framework, namely CLIPVehicle, which contains a dual-granularity semantic-region alignment module to leverage the VLMs (Vision-Language Models) for vehicle discrimination modeling, and a multi-level vehicle identification learning strategy to learn the identity representation from global, instance and feature levels. We also construct a new benchmark, including a real-world dataset CityFlowVS, and two synthetic datasets SynVS-Day and SynVS-All, for vehicle search. Extensive experimental results demonstrate that our method outperforms the state-of-the-art methods of both vehicle Re-ID and person search tasks.
OVT-B: A New Large-Scale Benchmark for Open-Vocabulary Multi-Object Tracking
Oct 23, 2024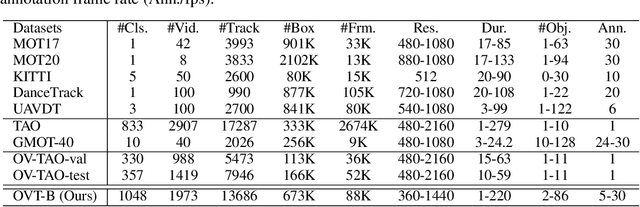



Open-vocabulary object perception has become an important topic in artificial intelligence, which aims to identify objects with novel classes that have not been seen during training. Under this setting, open-vocabulary object detection (OVD) in a single image has been studied in many literature. However, open-vocabulary object tracking (OVT) from a video has been studied less, and one reason is the shortage of benchmarks. In this work, we have built a new large-scale benchmark for open-vocabulary multi-object tracking namely OVT-B. OVT-B contains 1,048 categories of objects and 1,973 videos with 637,608 bounding box annotations, which is much larger than the sole open-vocabulary tracking dataset, i.e., OVTAO-val dataset (200+ categories, 900+ videos). The proposed OVT-B can be used as a new benchmark to pave the way for OVT research. We also develop a simple yet effective baseline method for OVT. It integrates the motion features for object tracking, which is an important feature for MOT but is ignored in previous OVT methods. Experimental results have verified the usefulness of the proposed benchmark and the effectiveness of our method. We have released the benchmark to the public at https://github.com/Coo1Sea/OVT-B-Dataset.
VOVTrack: Exploring the Potentiality in Videos for Open-Vocabulary Object Tracking
Oct 11, 2024



Open-vocabulary multi-object tracking (OVMOT) represents a critical new challenge involving the detection and tracking of diverse object categories in videos, encompassing both seen categories (base classes) and unseen categories (novel classes). This issue amalgamates the complexities of open-vocabulary object detection (OVD) and multi-object tracking (MOT). Existing approaches to OVMOT often merge OVD and MOT methodologies as separate modules, predominantly focusing on the problem through an image-centric lens. In this paper, we propose VOVTrack, a novel method that integrates object states relevant to MOT and video-centric training to address this challenge from a video object tracking standpoint. First, we consider the tracking-related state of the objects during tracking and propose a new prompt-guided attention mechanism for more accurate localization and classification (detection) of the time-varying objects. Subsequently, we leverage raw video data without annotations for training by formulating a self-supervised object similarity learning technique to facilitate temporal object association (tracking). Experimental results underscore that VOVTrack outperforms existing methods, establishing itself as a state-of-the-art solution for open-vocabulary tracking task.
OCTrack: Benchmarking the Open-Corpus Multi-Object Tracking
Jul 19, 2024
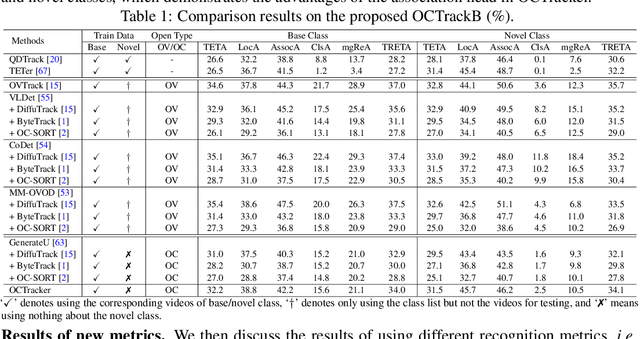
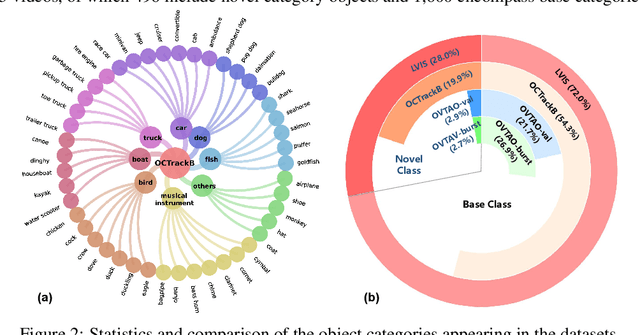

We study a novel yet practical problem of open-corpus multi-object tracking (OCMOT), which extends the MOT into localizing, associating, and recognizing generic-category objects of both seen (base) and unseen (novel) classes, but without the category text list as prompt. To study this problem, the top priority is to build a benchmark. In this work, we build OCTrackB, a large-scale and comprehensive benchmark, to provide a standard evaluation platform for the OCMOT problem. Compared to previous datasets, OCTrackB has more abundant and balanced base/novel classes and the corresponding samples for evaluation with less bias. We also propose a new multi-granularity recognition metric to better evaluate the generative object recognition in OCMOT. By conducting the extensive benchmark evaluation, we report and analyze the results of various state-of-the-art methods, which demonstrate the rationale of OCMOT, as well as the usefulness and advantages of OCTrackB.
Robust Collaborative Perception without External Localization and Clock Devices
May 05, 2024



A consistent spatial-temporal coordination across multiple agents is fundamental for collaborative perception, which seeks to improve perception abilities through information exchange among agents. To achieve this spatial-temporal alignment, traditional methods depend on external devices to provide localization and clock signals. However, hardware-generated signals could be vulnerable to noise and potentially malicious attack, jeopardizing the precision of spatial-temporal alignment. Rather than relying on external hardwares, this work proposes a novel approach: aligning by recognizing the inherent geometric patterns within the perceptual data of various agents. Following this spirit, we propose a robust collaborative perception system that operates independently of external localization and clock devices. The key module of our system,~\emph{FreeAlign}, constructs a salient object graph for each agent based on its detected boxes and uses a graph neural network to identify common subgraphs between agents, leading to accurate relative pose and time. We validate \emph{FreeAlign} on both real-world and simulated datasets. The results show that, the ~\emph{FreeAlign} empowered robust collaborative perception system perform comparably to systems relying on precise localization and clock devices.
From Synthetic to Real: Unveiling the Power of Synthetic Data for Video Person Re-ID
Feb 03, 2024
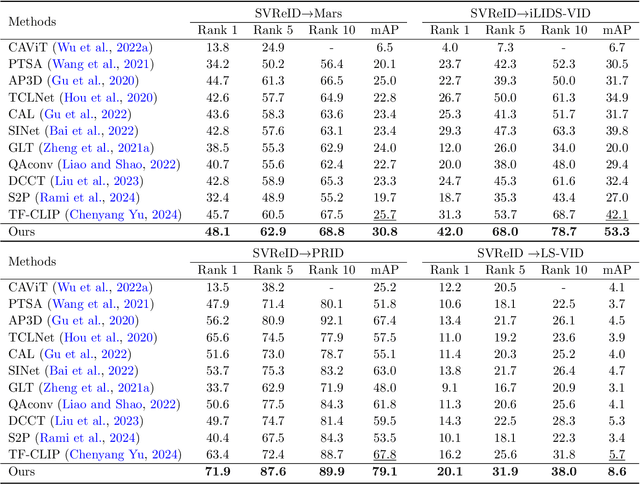
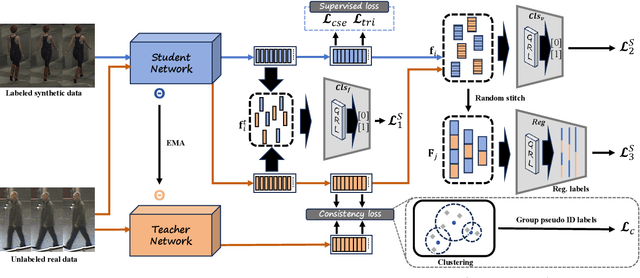
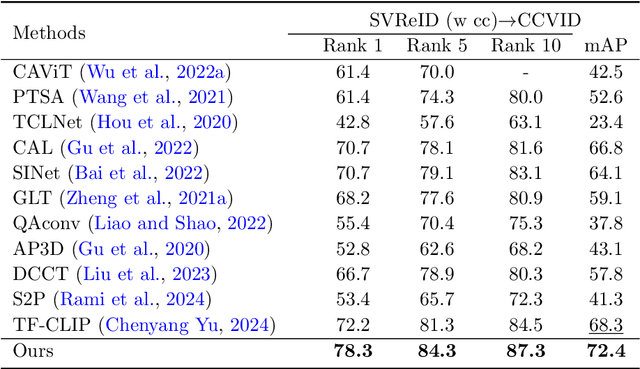
In this paper, we study a new problem of cross-domain video based person re-identification (Re-ID). Specifically, we take the synthetic video dataset as the source domain for training and use the real-world videos for testing, which significantly reduces the dependence on real training data collection and annotation. To unveil the power of synthetic data for video person Re-ID, we first propose a self-supervised domain invariant feature learning strategy for both static and temporal features. Then, to further improve the person identification ability in the target domain, we develop a mean-teacher scheme with the self-supervised ID consistency loss. Experimental results on four real datasets verify the rationality of cross-synthetic-real domain adaption and the effectiveness of our method. We are also surprised to find that the synthetic data performs even better than the real data in the cross-domain setting.
Unveiling the Power of Self-supervision for Multi-view Multi-human Association and Tracking
Jan 31, 2024Multi-view multi-human association and tracking (MvMHAT), is a new but important problem for multi-person scene video surveillance, aiming to track a group of people over time in each view, as well as to identify the same person across different views at the same time, which is different from previous MOT and multi-camera MOT tasks only considering the over-time human tracking. This way, the videos for MvMHAT require more complex annotations while containing more information for self learning. In this work, we tackle this problem with a self-supervised learning aware end-to-end network. Specifically, we propose to take advantage of the spatial-temporal self-consistency rationale by considering three properties of reflexivity, symmetry and transitivity. Besides the reflexivity property that naturally holds, we design the self-supervised learning losses based on the properties of symmetry and transitivity, for both appearance feature learning and assignment matrix optimization, to associate the multiple humans over time and across views. Furthermore, to promote the research on MvMHAT, we build two new large-scale benchmarks for the network training and testing of different algorithms. Extensive experiments on the proposed benchmarks verify the effectiveness of our method. We have released the benchmark and code to the public.
From a Bird's Eye View to See: Joint Camera and Subject Registration without the Camera Calibration
Dec 19, 2022



We tackle a new problem of multi-view camera and subject registration in the bird's eye view (BEV) without pre-given camera calibration. This is a very challenging problem since its only input is several RGB images from different first-person views (FPVs) for a multi-person scene, without the BEV image and the calibration of the FPVs, while the output is a unified plane with the localization and orientation of both the subjects and cameras in a BEV. We propose an end-to-end framework solving this problem, whose main idea can be divided into following parts: i) creating a view-transform subject detection module to transform the FPV to a virtual BEV including localization and orientation of each pedestrian, ii) deriving a geometric transformation based method to estimate camera localization and view direction, i.e., the camera registration in a unified BEV, iii) making use of spatial and appearance information to aggregate the subjects into the unified BEV. We collect a new large-scale synthetic dataset with rich annotations for evaluation. The experimental results show the remarkable effectiveness of our proposed method.
From Indoor To Outdoor: Unsupervised Domain Adaptive Gait Recognition
Nov 21, 2022Gait recognition is an important AI task, which has been progressed rapidly with the development of deep learning. However, existing learning based gait recognition methods mainly focus on the single domain, especially the constrained laboratory environment. In this paper, we study a new problem of unsupervised domain adaptive gait recognition (UDA-GR), that learns a gait identifier with supervised labels from the indoor scenes (source domain), and is applied to the outdoor wild scenes (target domain). For this purpose, we develop an uncertainty estimation and regularization based UDA-GR method. Specifically, we investigate the characteristic of gaits in the indoor and outdoor scenes, for estimating the gait sample uncertainty, which is used in the unsupervised fine-tuning on the target domain to alleviate the noises of the pseudo labels. We also establish a new benchmark for the proposed problem, experimental results on which show the effectiveness of the proposed method. We will release the benchmark and source code in this work to the public.
A Benchmark of Video-Based Clothes-Changing Person Re-Identification
Nov 21, 2022



Person re-identification (Re-ID) is a classical computer vision task and has achieved great progress so far. Recently, long-term Re-ID with clothes-changing has attracted increasing attention. However, existing methods mainly focus on image-based setting, where richer temporal information is overlooked. In this paper, we focus on the relatively new yet practical problem of clothes-changing video-based person re-identification (CCVReID), which is less studied. We systematically study this problem by simultaneously considering the challenge of the clothes inconsistency issue and the temporal information contained in the video sequence for the person Re-ID problem. Based on this, we develop a two-branch confidence-aware re-ranking framework for handling the CCVReID problem. The proposed framework integrates two branches that consider both the classical appearance features and cloth-free gait features through a confidence-guided re-ranking strategy. This method provides the baseline method for further studies. Also, we build two new benchmark datasets for CCVReID problem, including a large-scale synthetic video dataset and a real-world one, both containing human sequences with various clothing changes. We will release the benchmark and code in this work to the public.