 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstruction of boosted and resolved multi-Higgs-boson events with symmetry-preserving attention networks
Dec 05, 2024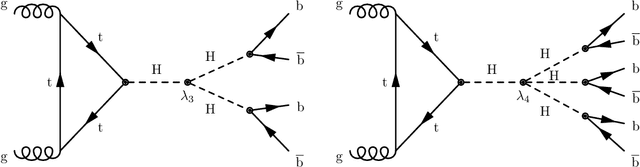



The production of multiple Higgs bosons at the CERN LHC provides a direct way to measure the trilinear and quartic Higgs self-interaction strengths as well as potential access to beyond the standard model effects that can enhance production at large transverse momentum $p_{\mathrm{T}}$. The largest event fraction arises from the fully hadronic final state in which every Higgs boson decays to a bottom quark-antiquark pair ($b\bar{b}$). This introduces a combinatorial challenge known as the \emph{jet assignment problem}: assigning jets to sets representing Higgs boson candidates. Symmetry-preserving attention networks (SPA-Nets) have been been developed to address this challenge. However, the complexity of jet assignment increases when simultaneously considering both $H\rightarrow b\bar{b}$ reconstruction possibilities, i.e., two "resolved" small-radius jets each containing a shower initiated by a $b$-quark or one "boosted" large-radius jet containing a merged shower initiated by a $b\bar{b}$ pair. The latter improves the reconstruction efficiency at high $p_{\mathrm{T}}$. In this work, we introduce a generalization to the SPA-Net approach to simultaneously consider both boosted and resolved reconstruction possibilities and unambiguously interpret an event as "fully resolved'', "fully boosted", or in between. We report the performance of baseline methods, the original SPA-Net approach, and our generalized version on nonresonant $HH$ and $HHH$ production at the LHC. Considering both boosted and resolved topologies, our SPA-Net approach increases the Higgs boson reconstruction purity by 57--62\% and the efficiency by 23--38\% compared to the baseline method depending on the final state.
Effectiveness and predictability of in-network storage cache for scientific workflows
Jul 20, 2023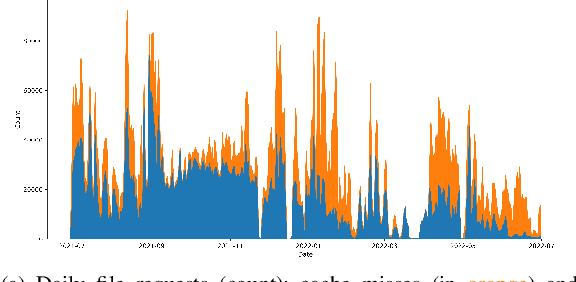
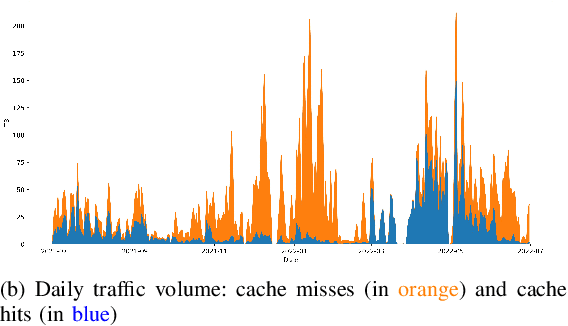
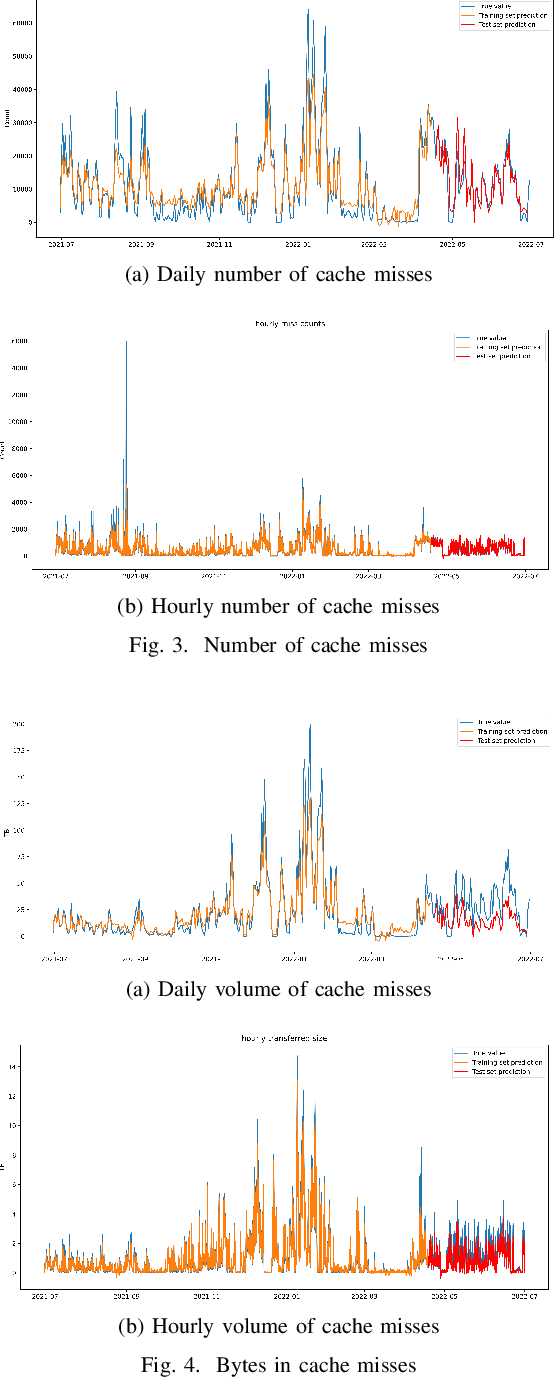
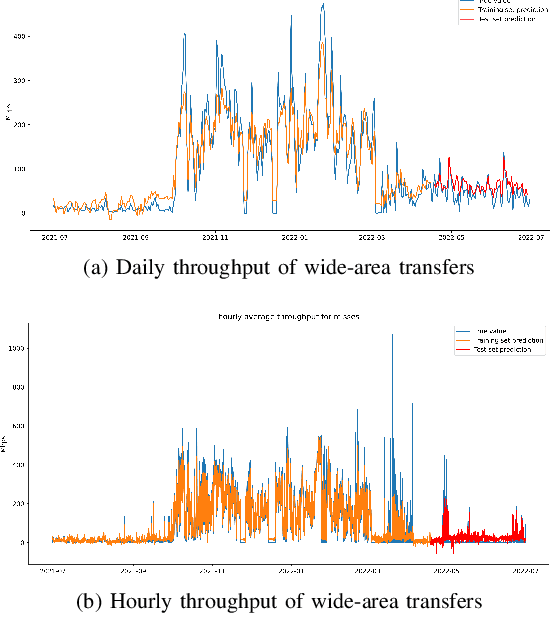
Large scientific collaborations often have multiple scientists accessing the same set of files while doing different analyses, which create repeated accesses to the large amounts of shared data located far away. These data accesses have long latency due to distance and occupy the limited bandwidth available over the wide-area network. To reduce the wide-area network traffic and the data access latency, regional data storage caches have been installed as a new networking service. To study the effectiveness of such a cache system in scientific applications, we examine the Southern California Petabyte Scale Cache for a high-energy physics experiment. By examining about 3TB of operational logs, we show that this cache removed 67.6% of file requests from the wide-area network and reduced the traffic volume on wide-area network by 12.3TB (or 35.4%) an average day. The reduction in the traffic volume (35.4%) is less than the reduction in file counts (67.6%) because the larger files are less likely to be reused. Due to this difference in data access patterns, the cache system has implemented a policy to avoid evicting smaller files when processing larger files. We also build a machine learning model to study the predictability of the cache behavior. Tests show that this model is able to accurately predict the cache accesses, cache misses, and network throughput, making the model useful for future studies on resource provisioning and planning.
Access Trends of In-network Cache for Scientific Data
May 11, 2022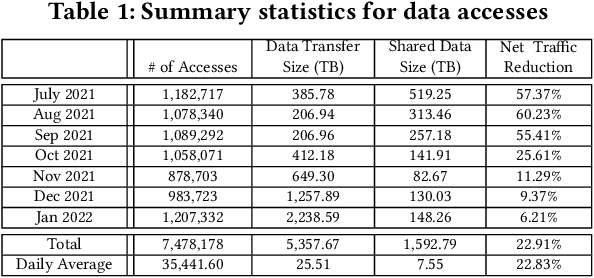
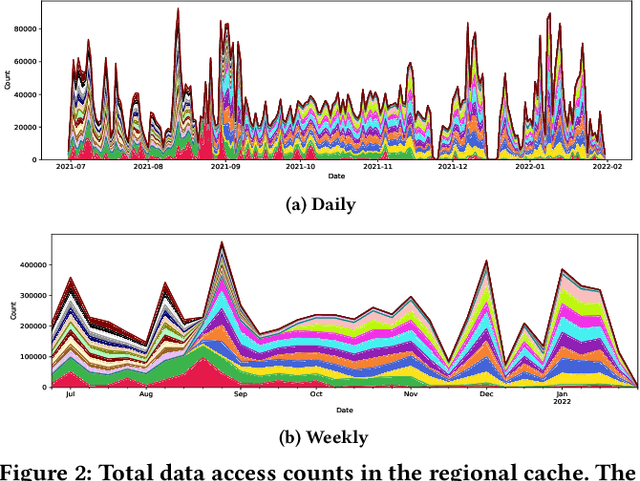
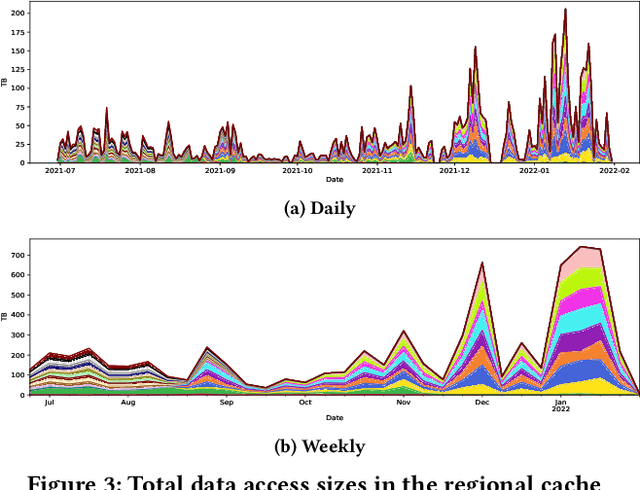
Scientific collaborations are increasingly relying on large volumes of data for their work and many of them employ tiered systems to replicate the data to their worldwide user communities. Each user in the community often selects a different subset of data for their analysis tasks; however, members of a research group often are working on related research topics that require similar data objects. Thus, there is a significant amount of data sharing possible. In this work, we study the access traces of a federated storage cache known as the Southern California Petabyte Scale Cache. By studying the access patterns and potential for network traffic reduction by this caching system, we aim to explore the predictability of the cache uses and the potential for a more general in-network data caching. Our study shows that this distributed storage cache is able to reduce the network traffic volume by a factor of 2.35 during a part of the study period. We further show that machine learning models could predict cache utilization with an accuracy of 0.88. This demonstrates that such cache usage is predictable, which could be useful for managing complex networking resources such as in-network caching.
Machine Learning in High Energy Physics Community White Paper
Jul 08, 2018

Machine learning is an important research area in particle physics, beginning with applications to high-level physics analysis in the 1990s and 2000s, followed by an explosion of applications in particle and event identification and reconstruction in the 2010s. In this document we discuss promising future research and development areas in machine learning in particle physics with a roadmap for their implementation, software and hardware resource requirements, collaborative initiatives with the data science community, academia and industry, and training the particle physics community in data science. The main objective of the document is to connect and motivate these areas of research and development with the physics drivers of the High-Luminosity Large Hadron Collider and future neutrino experiments and identify the resource needs for their implementation. Additionally we identify areas where collaboration with external communities will be of great benefit.