 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning in High Energy Physics Community White Paper
Jul 08, 2018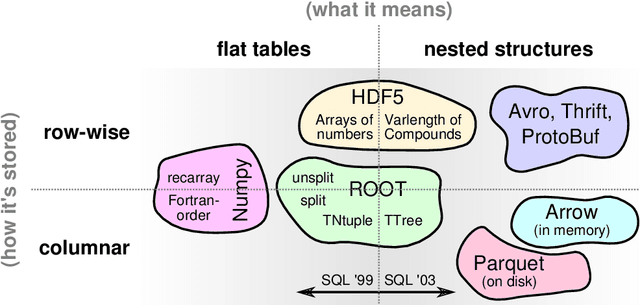
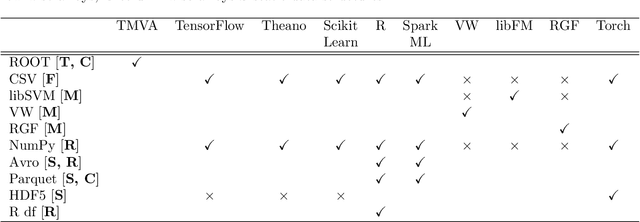

Machine learning is an important research area in particle physics, beginning with applications to high-level physics analysis in the 1990s and 2000s, followed by an explosion of applications in particle and event identification and reconstruction in the 2010s. In this document we discuss promising future research and development areas in machine learning in particle physics with a roadmap for their implementation, software and hardware resource requirements, collaborative initiatives with the data science community, academia and industry, and training the particle physics community in data science. The main objective of the document is to connect and motivate these areas of research and development with the physics drivers of the High-Luminosity Large Hadron Collider and future neutrino experiments and identify the resource needs for their implementation. Additionally we identify areas where collaboration with external communities will be of great benefit.
Support Vector Machines and generalisation in HEP
Feb 15, 2017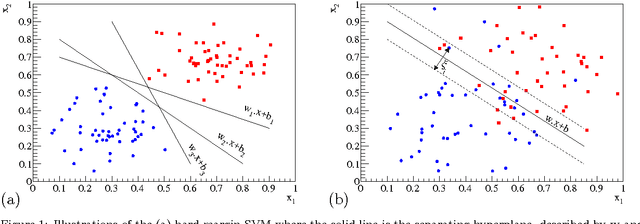
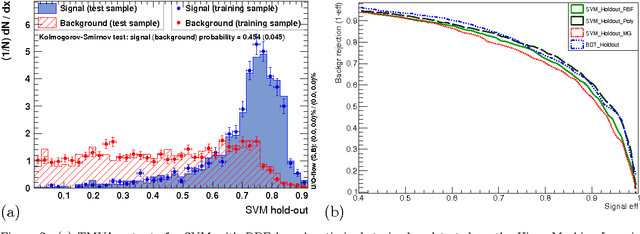
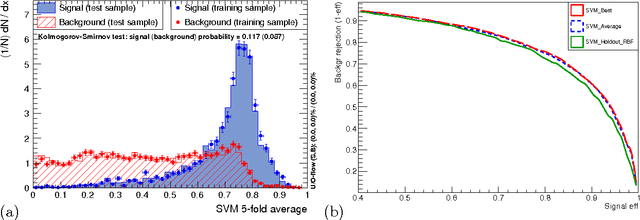
We review the concept of Support Vector Machines (SVMs) and discuss examples of their use in a number of scenarios. Several SVM implementations have been used in HEP and we exemplify this algorithm using the Toolkit for Multivariate Analysis (TMVA) implementation. We discuss examples relevant to HEP including background suppression for $H\to\tau^+\tau^-$ at the LHC with several different kernel functions. Performance benchmarking leads to the issue of generalisation of hyper-parameter selection. The avoidance of fine tuning (over training or over fitting) in MVA hyper-parameter optimisation, i.e. the ability to ensure generalised performance of an MVA that is independent of the training, validation and test samples, is of utmost importance. We discuss this issue and compare and contrast performance of hold-out and k-fold cross-validation. We have extended the SVM functionality and introduced tools to facilitate cross validation in TMVA and present results based on these improvements.