 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology classification with deep learning to improve real-time event selection at the LHC
Aug 01, 2018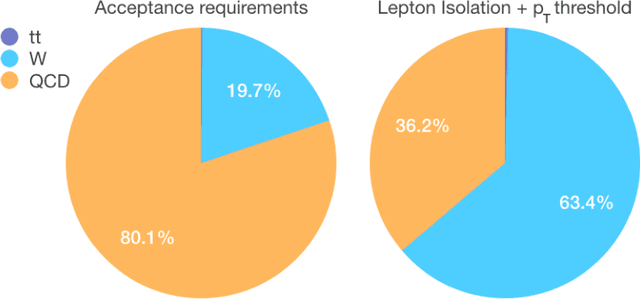
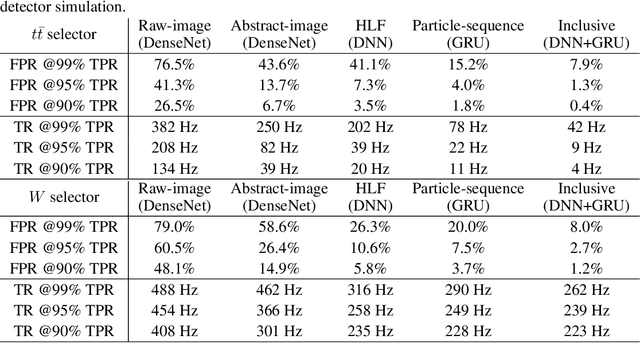
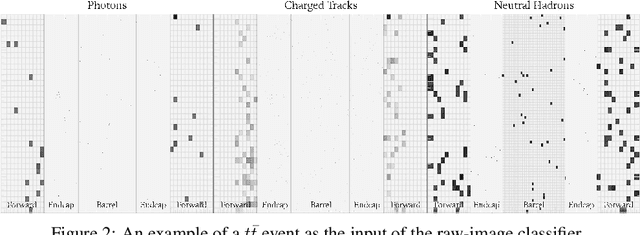
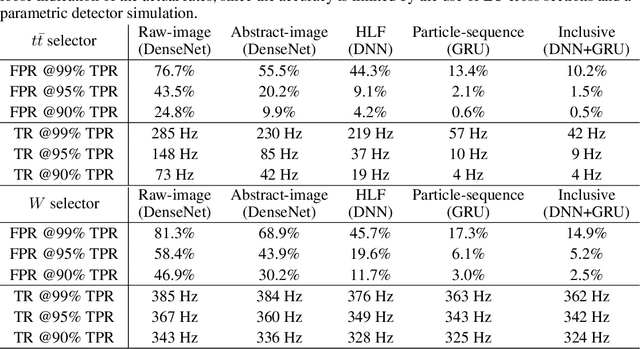
We show how event topology classification based on deep learning could be used to improve the purity of data samples selected in real time at at the Large Hadron Collider. We consider different data representations, on which different kinds of multi-class classifiers are trained. Both raw data and high-level features are utilized. In the considered examples, a filter based on the classifier's score can be trained to retain ~99% of the interesting events and reduce the false-positive rate by as much as one order of magnitude for certain background processes. By operating such a filter as part of the online event selection infrastructure of the LHC experiments, one could benefit from a more flexible and inclusive selection strategy while reducing the amount of downstream resources wasted in processing false positives. The saved resources could be translated into a reduction of the detector operation cost or into an effective increase of storage and processing capabilities, which could be reinvested to extend the physics reach of the LHC experiments.
Machine Learning in High Energy Physics Community White Paper
Jul 08, 2018

Machine learning is an important research area in particle physics, beginning with applications to high-level physics analysis in the 1990s and 2000s, followed by an explosion of applications in particle and event identification and reconstruction in the 2010s. In this document we discuss promising future research and development areas in machine learning in particle physics with a roadmap for their implementation, software and hardware resource requirements, collaborative initiatives with the data science community, academia and industry, and training the particle physics community in data science. The main objective of the document is to connect and motivate these areas of research and development with the physics drivers of the High-Luminosity Large Hadron Collider and future neutrino experiments and identify the resource needs for their implementation. Additionally we identify areas where collaboration with external communities will be of great benefit.
An MPI-Based Python Framework for Distributed Training with Keras
Dec 16, 2017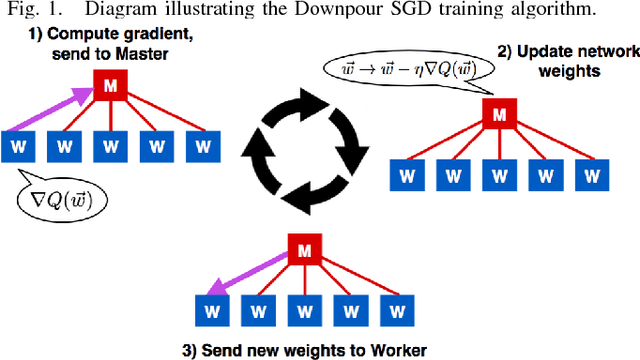
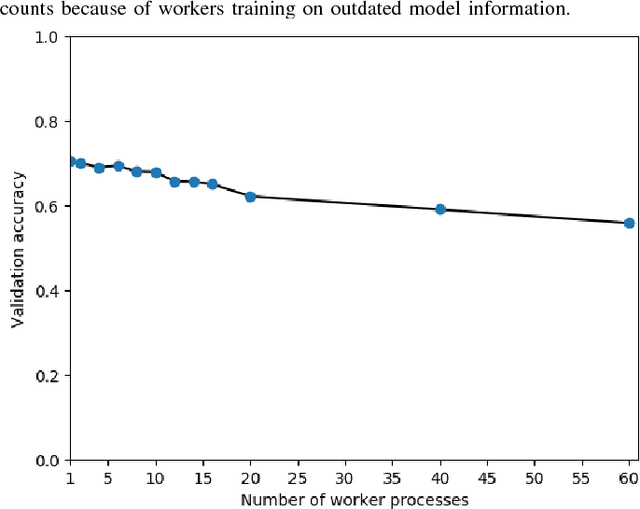
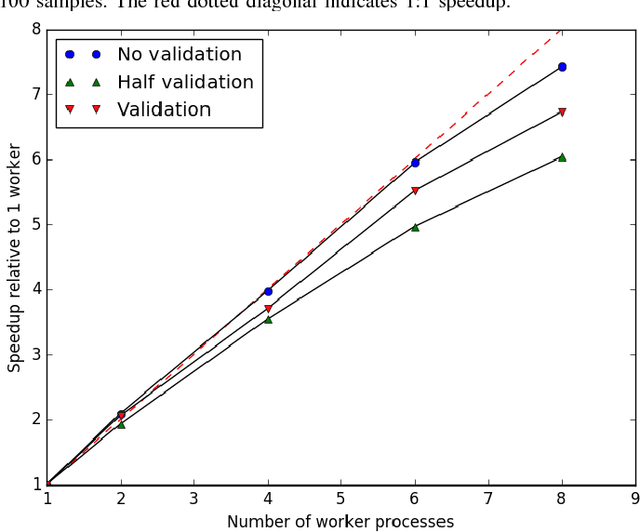
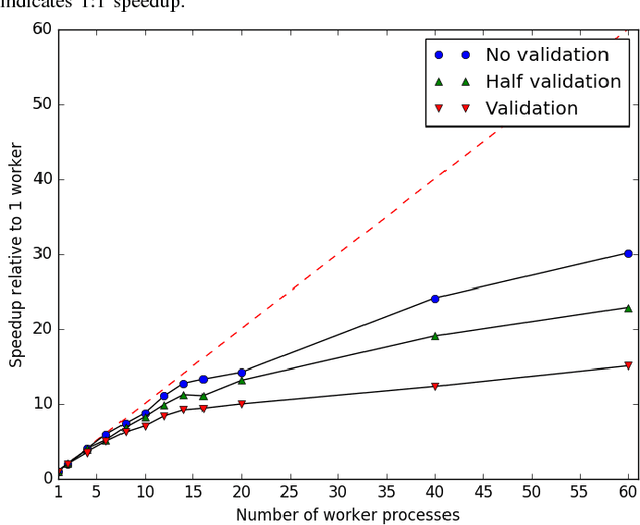
We present a lightweight Python framework for distributed training of neural networks on multiple GPUs or CPUs. The framework is built on the popular Keras machine learning library. The Message Passing Interface (MPI) protocol is used to coordinate the training process, and the system is well suited for job submission at supercomputing sites. We detail the software's features, describe its use, and demonstrate its performance on systems of varying sizes on a benchmark problem drawn from high-energy physics research.