 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffectiveness and predictability of in-network storage cache for scientific workflows
Paper and Code
Jul 20, 2023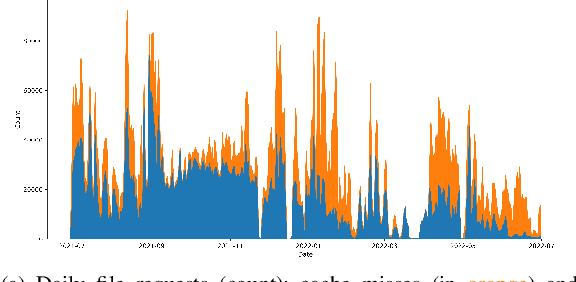
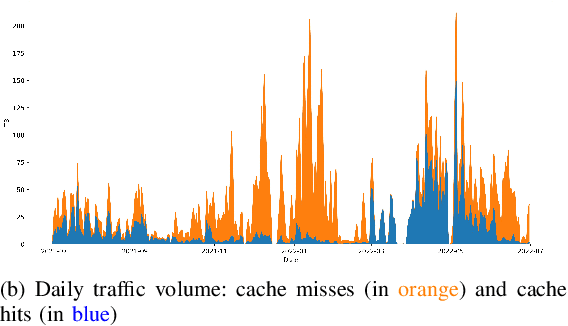
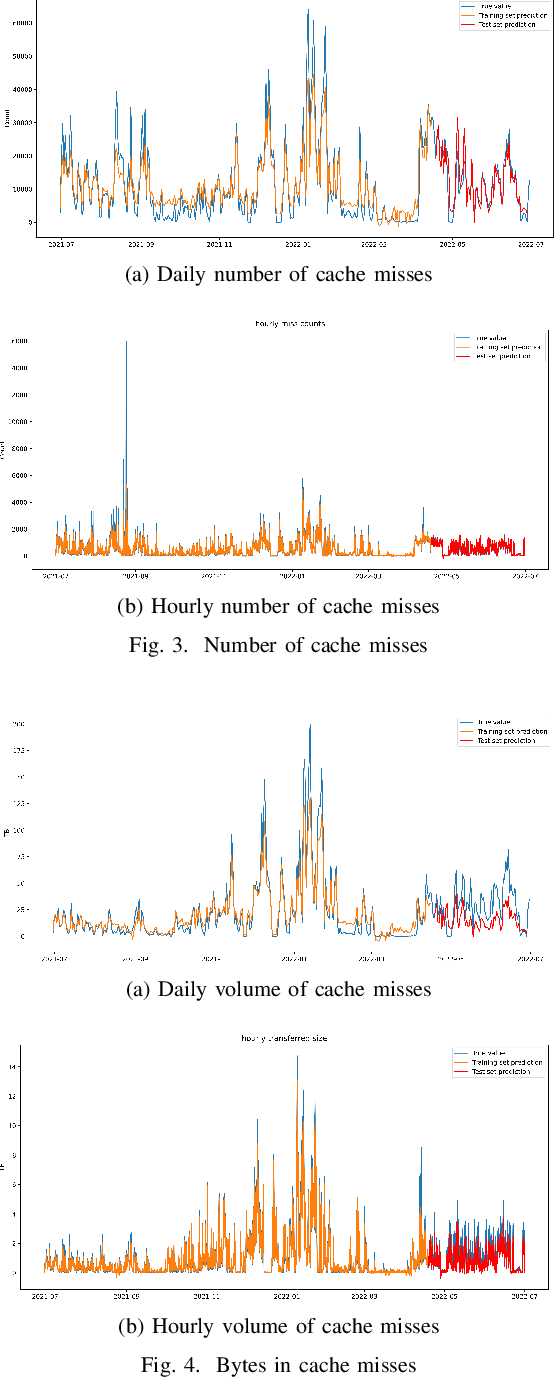
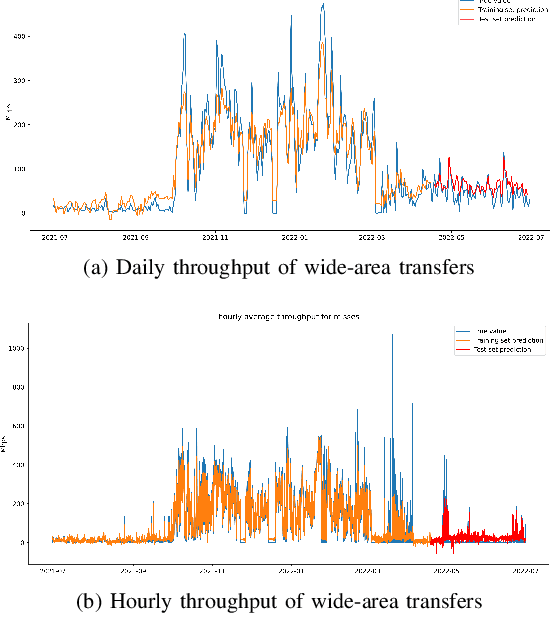
Large scientific collaborations often have multiple scientists accessing the same set of files while doing different analyses, which create repeated accesses to the large amounts of shared data located far away. These data accesses have long latency due to distance and occupy the limited bandwidth available over the wide-area network. To reduce the wide-area network traffic and the data access latency, regional data storage caches have been installed as a new networking service. To study the effectiveness of such a cache system in scientific applications, we examine the Southern California Petabyte Scale Cache for a high-energy physics experiment. By examining about 3TB of operational logs, we show that this cache removed 67.6% of file requests from the wide-area network and reduced the traffic volume on wide-area network by 12.3TB (or 35.4%) an average day. The reduction in the traffic volume (35.4%) is less than the reduction in file counts (67.6%) because the larger files are less likely to be reused. Due to this difference in data access patterns, the cache system has implemented a policy to avoid evicting smaller files when processing larger files. We also build a machine learning model to study the predictability of the cache behavior. Tests show that this model is able to accurately predict the cache accesses, cache misses, and network throughput, making the model useful for future studies on resource provisioning and planning.