 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Slow Transfer Predictions: Generative Methods Compared
Dec 16, 2025Monitoring data transfer performance is a crucial task in scientific computing networks. By predicting performance early in the communication phase, potentially sluggish transfers can be identified and selectively monitored, optimizing network usage and overall performance. A key bottleneck to improving the predictive power of machine learning (ML) models in this context is the issue of class imbalance. This project focuses on addressing the class imbalance problem to enhance the accuracy of performance predictions. In this study, we analyze and compare various augmentation strategies, including traditional oversampling methods and generative techniques. Additionally, we adjust the class imbalance ratios in training datasets to evaluate their impact on model performance. While augmentation may improve performance, as the imbalance ratio increases, the performance does not significantly improve. We conclude that even the most advanced technique, such as CTGAN, does not significantly improve over simple stratified sampling.
Serving Deep Learning Model in Relational Databases
Oct 10, 2023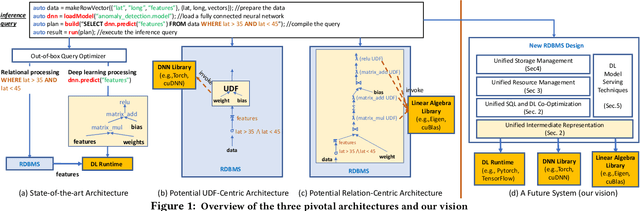

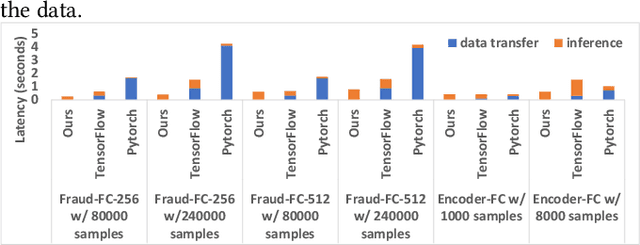

Serving deep learning (DL) models on relational data has become a critical requirement across diverse commercial and scientific domains, sparking growing interest recently. In this visionary paper, we embark on a comprehensive exploration of representative architectures to address the requirement. We highlight three pivotal paradigms: The state-of-the-artDL-Centricarchitecture offloadsDL computations to dedicated DL frameworks. The potential UDF-Centric architecture encapsulates one or more tensor computations into User Defined Functions (UDFs) within the database system. The potentialRelation-Centricarchitecture aims to represent a large-scale tensor computation through relational operators. While each of these architectures demonstrates promise in specific use scenarios, we identify urgent requirements for seamless integration of these architectures and the middle ground between these architectures. We delve into the gaps that impede the integration and explore innovative strategies to close them. We present a pathway to establish a novel database system for enabling a broad class of data-intensive DL inference applications.
Effectiveness and predictability of in-network storage cache for scientific workflows
Jul 20, 2023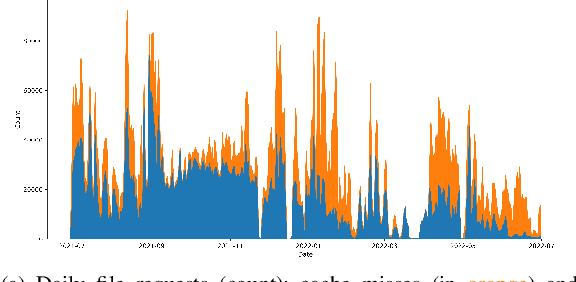
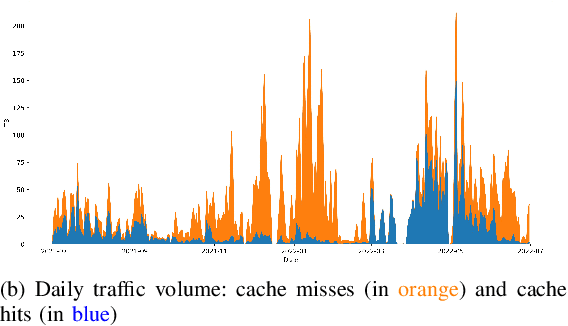
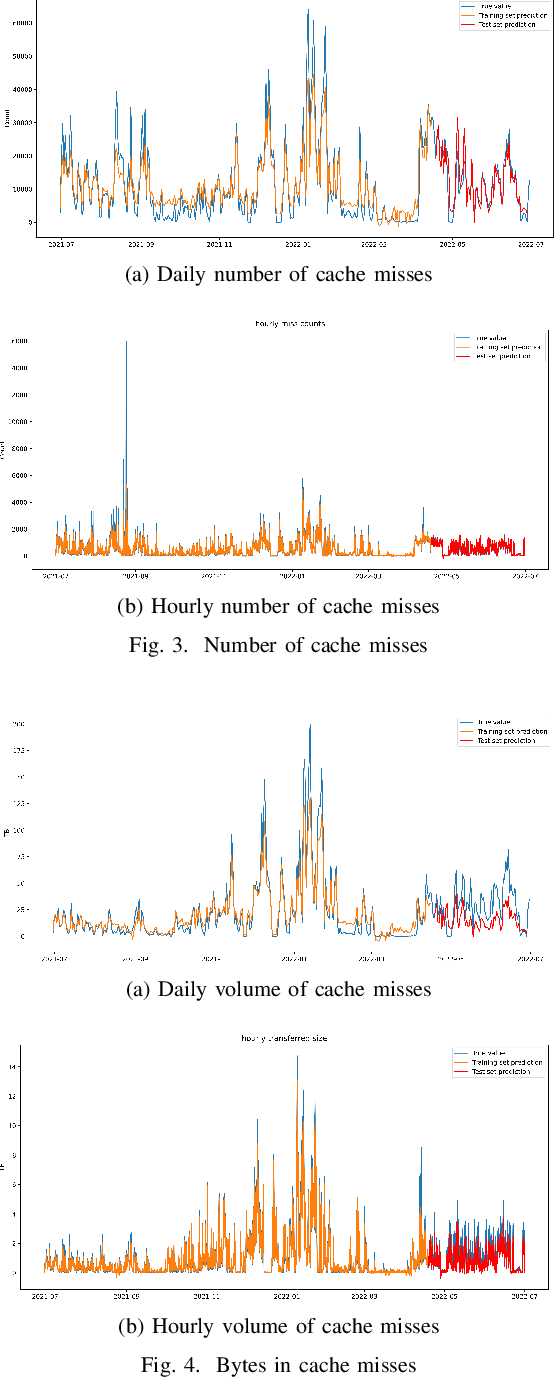
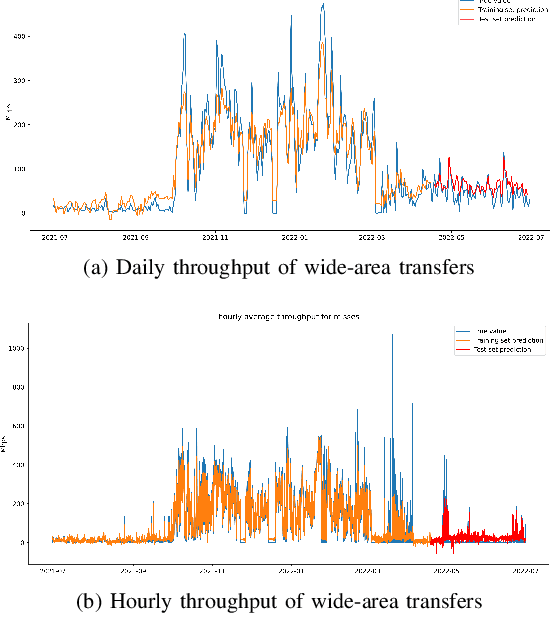
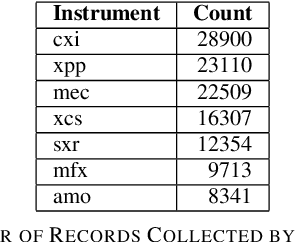
Large scientific collaborations often have multiple scientists accessing the same set of files while doing different analyses, which create repeated accesses to the large amounts of shared data located far away. These data accesses have long latency due to distance and occupy the limited bandwidth available over the wide-area network. To reduce the wide-area network traffic and the data access latency, regional data storage caches have been installed as a new networking service. To study the effectiveness of such a cache system in scientific applications, we examine the Southern California Petabyte Scale Cache for a high-energy physics experiment. By examining about 3TB of operational logs, we show that this cache removed 67.6% of file requests from the wide-area network and reduced the traffic volume on wide-area network by 12.3TB (or 35.4%) an average day. The reduction in the traffic volume (35.4%) is less than the reduction in file counts (67.6%) because the larger files are less likely to be reused. Due to this difference in data access patterns, the cache system has implemented a policy to avoid evicting smaller files when processing larger files. We also build a machine learning model to study the predictability of the cache behavior. Tests show that this model is able to accurately predict the cache accesses, cache misses, and network throughput, making the model useful for future studies on resource provisioning and planning.
Extract Dynamic Information To Improve Time Series Modeling: a Case Study with Scientific Workflow
May 19, 2022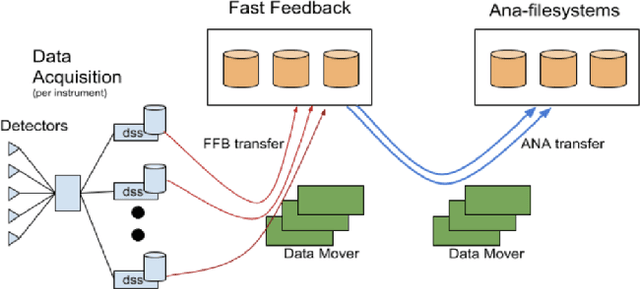
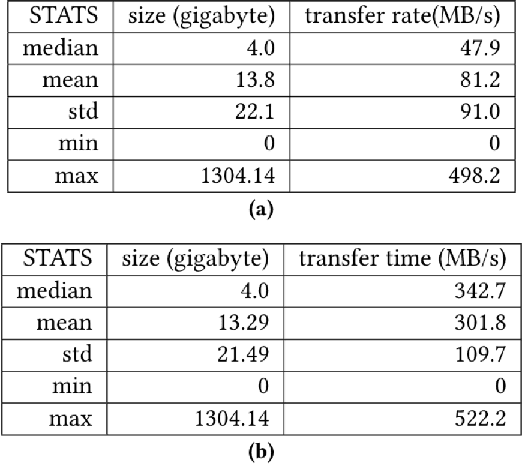

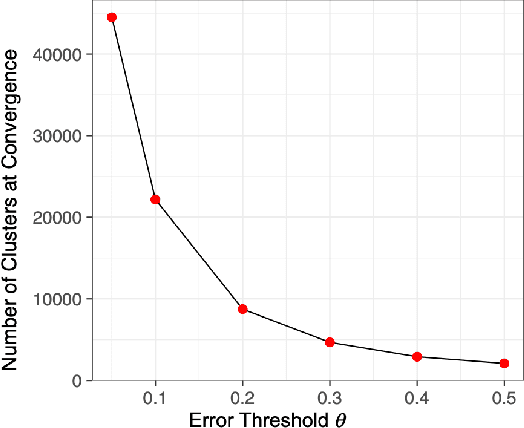
In modeling time series data, we often need to augment the existing data records to increase the modeling accuracy. In this work, we describe a number of techniques to extract dynamic information about the current state of a large scientific workflow, which could be generalized to other types of applications. The specific task to be modeled is the time needed for transferring a file from an experimental facility to a data center. The key idea of our approach is to find recent past data transfer events that match the current event in some ways. Tests showed that we could identify recent events matching some recorded properties and reduce the prediction error by about 12% compared to the similar models with only static features. We additionally explored an application specific technique to extract information about the data production process, and was able to reduce the average prediction error by 44%.
Access Trends of In-network Cache for Scientific Data
May 11, 2022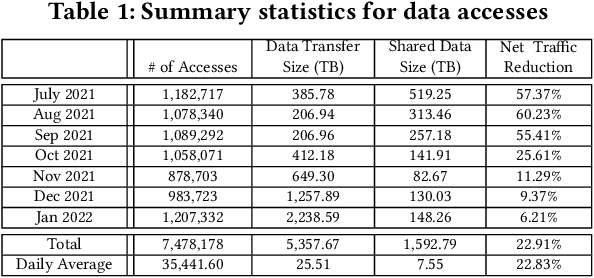
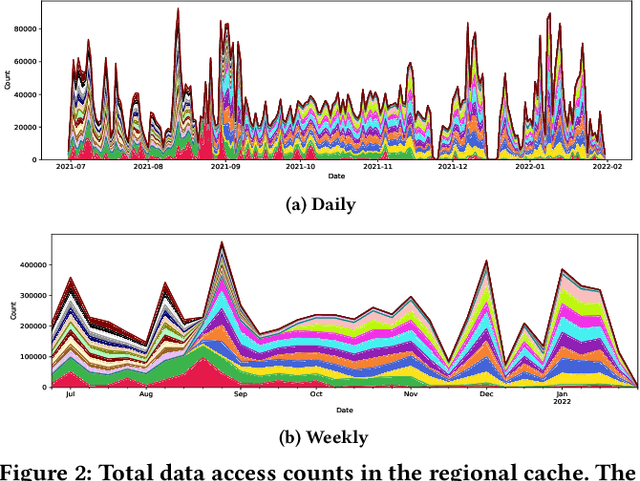
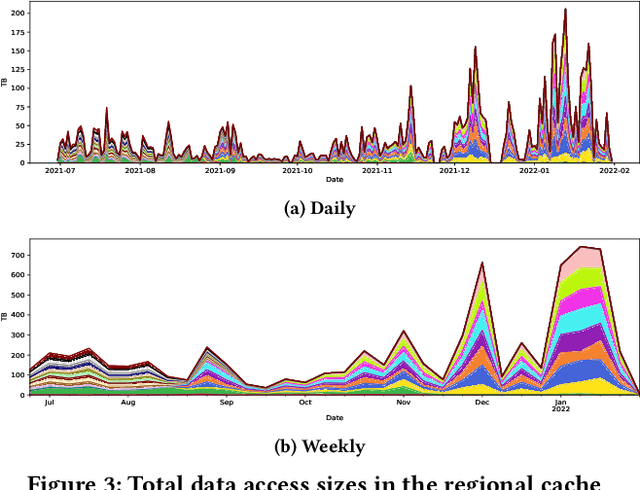
Scientific collaborations are increasingly relying on large volumes of data for their work and many of them employ tiered systems to replicate the data to their worldwide user communities. Each user in the community often selects a different subset of data for their analysis tasks; however, members of a research group often are working on related research topics that require similar data objects. Thus, there is a significant amount of data sharing possible. In this work, we study the access traces of a federated storage cache known as the Southern California Petabyte Scale Cache. By studying the access patterns and potential for network traffic reduction by this caching system, we aim to explore the predictability of the cache uses and the potential for a more general in-network data caching. Our study shows that this distributed storage cache is able to reduce the network traffic volume by a factor of 2.35 during a part of the study period. We further show that machine learning models could predict cache utilization with an accuracy of 0.88. This demonstrates that such cache usage is predictable, which could be useful for managing complex networking resources such as in-network caching.
Adaptive Elastic Training for Sparse Deep Learning on Heterogeneous Multi-GPU Servers
Oct 13, 2021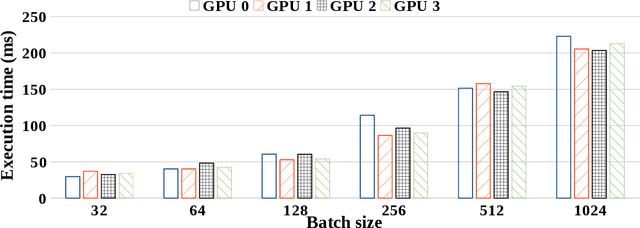

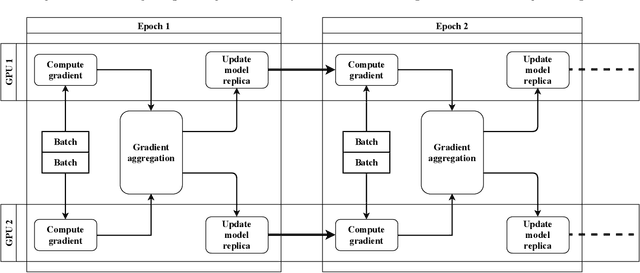
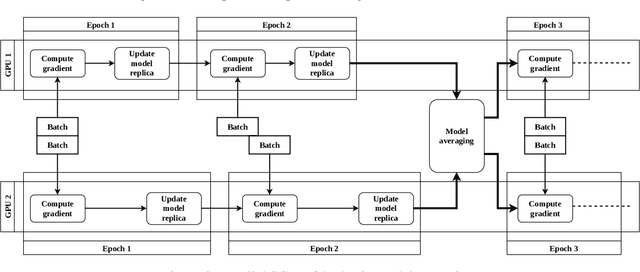
Motivated by extreme multi-label classification applications, we consider training deep learning models over sparse data in multi-GPU servers. The variance in the number of non-zero features across training batches and the intrinsic GPU heterogeneity combine to limit accuracy and increase the time to convergence. We address these challenges with Adaptive SGD, an adaptive elastic model averaging stochastic gradient descent algorithm for heterogeneous multi-GPUs that is characterized by dynamic scheduling, adaptive batch size scaling, and normalized model merging. Instead of statically partitioning batches to GPUs, batches are routed based on the relative processing speed. Batch size scaling assigns larger batches to the faster GPUs and smaller batches to the slower ones, with the goal to arrive at a steady state in which all the GPUs perform the same number of model updates. Normalized model merging computes optimal weights for every GPU based on the assigned batches such that the combined model achieves better accuracy. We show experimentally that Adaptive SGD outperforms four state-of-the-art solutions in time-to-accuracy and is scalable with the number of GPUs.
Improving Botnet Detection with Recurrent Neural Network and Transfer Learning
Apr 26, 2021
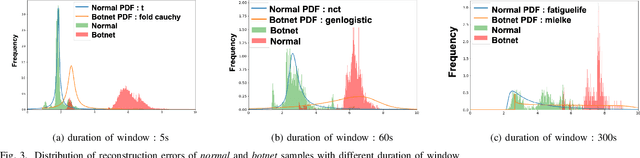
Botnet detection is a critical step in stopping the spread of botnets and preventing malicious activities. However, reliable detection is still a challenging task, due to a wide variety of botnets involving ever-increasing types of devices and attack vectors. Recent approaches employing machine learning (ML) showed improved performance than earlier ones, but these ML- based approaches still have significant limitations. For example, most ML approaches can not incorporate sequential pattern analysis techniques key to detect some classes of botnets. Another common shortcoming of ML-based approaches is the need to retrain neural networks in order to detect the evolving botnets; however, the training process is time-consuming and requires significant efforts to label the training data. For fast-evolving botnets, it might take too long to create sufficient training samples before the botnets have changed again. To address these challenges, we propose a novel botnet detection method, built upon Recurrent Variational Autoencoder (RVAE) that effectively captures sequential characteristics of botnet activities. In the experiment, this semi-supervised learning method achieves better detection accuracy than similar learning methods, especially on hard to detect classes. Additionally, we devise a transfer learning framework to learn from a well-curated source data set and transfer the knowledge to a target problem domain not seen before. Tests show that the true-positive rate (TPR) with transfer learning is higher than the RVAE semi-supervised learning method trained using the target data set (91.8% vs. 68.3%).
Investigating Underlying Drivers of Variability in Residential Energy Usage Patterns with Daily Load Shape Clustering of Smart Meter Data
Feb 16, 2021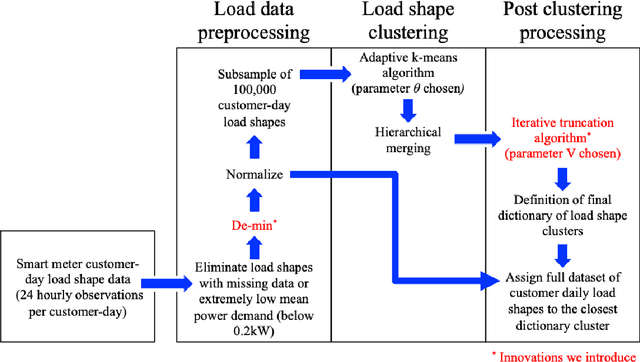

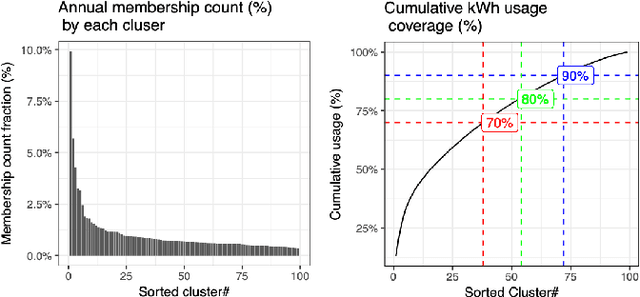
Residential customers have traditionally not been treated as individual entities due to the high volatility in residential consumption patterns as well as a historic focus on aggregated loads from the utility and system feeder perspective. Large-scale deployment of smart meters has motivated increasing studies to explore disaggregated daily load patterns, which can reveal important heterogeneity across different time scales, weather conditions, as well as within and across individual households. This paper aims to shed light on the mechanisms by which electricity consumption patterns exhibit variability and the different constraints that may affect demand-response (DR) flexibility. We systematically evaluate the relationship between daily time-of-use patterns and their variability to external and internal influencing factors, including time scales of interest, meteorological conditions, and household characteristics by application of an improved version of the adaptive K-means clustering method to profile "household-days" of a summer peaking utility. We find that for this summer-peaking utility, outdoor temperature is the most important external driver of the load shape variability relative to seasonality and day-of-week. The top three consumption patterns represent approximately 50% of usage on the highest temperature days. The variability in summer load shapes across customers can be explained by the responsiveness of the households to outside temperature. Our results suggest that depending on the influencing factors, not all the consumption variability can be readily translated to consumption flexibility. Such information needs to be further explored in segmenting customers for better program targeting and tailoring to meet the needs of the rapidly evolving electricity grid.
Deep Learning on Real Geophysical Data: A Case Study for Distributed Acoustic Sensing Research
Oct 15, 2020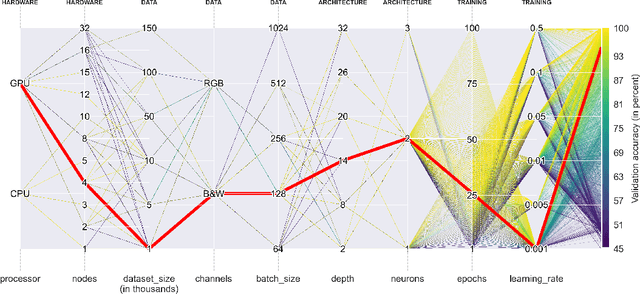
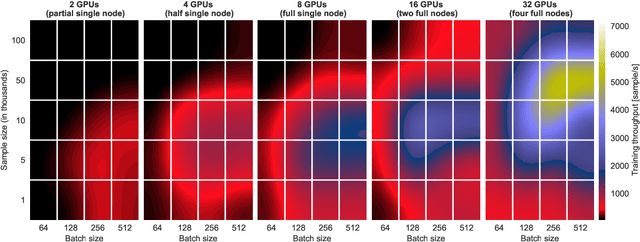
Deep Learning approaches for real, large, and complex scientific data sets can be very challenging to design. In this work, we present a complete search for a finely-tuned and efficiently scaled deep learning classifier to identify usable energy from seismic data acquired using Distributed Acoustic Sensing (DAS). While using only a subset of labeled images during training, we were able to identify suitable models that can be accurately generalized to unknown signal patterns. We show that by using 16 times more GPUs, we can increase the training speed by more than two orders of magnitude on a 50,000-image data set.
Deep Learning for Surface Wave Identification in Distributed Acoustic Sensing Data
Oct 15, 2020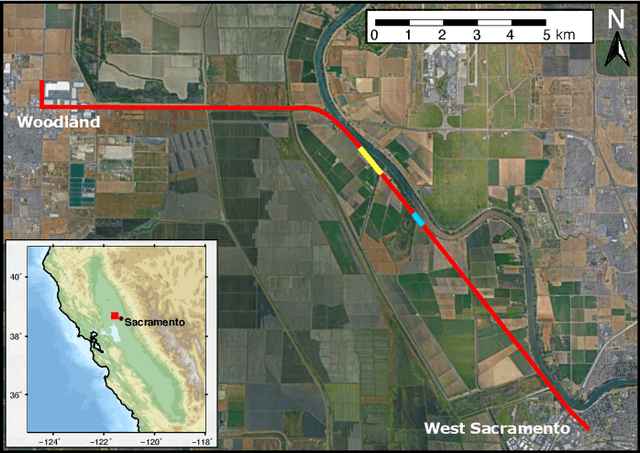
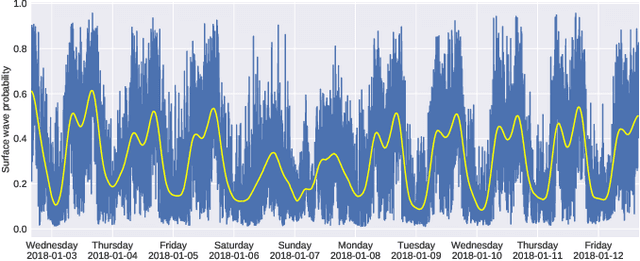
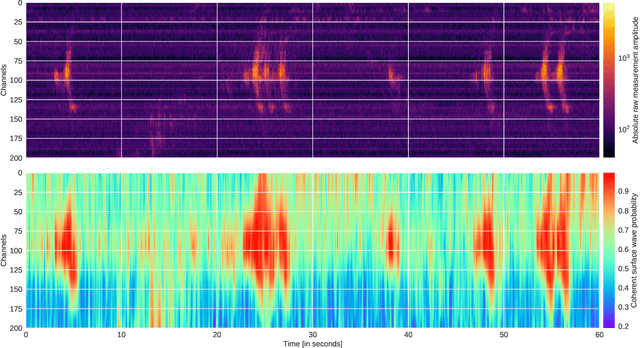
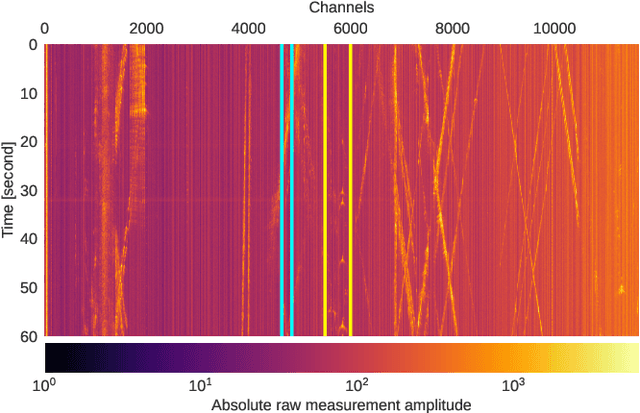
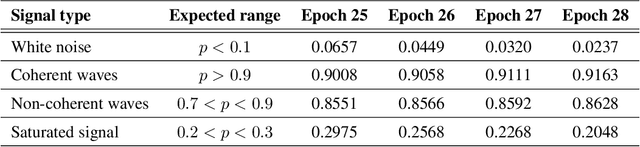
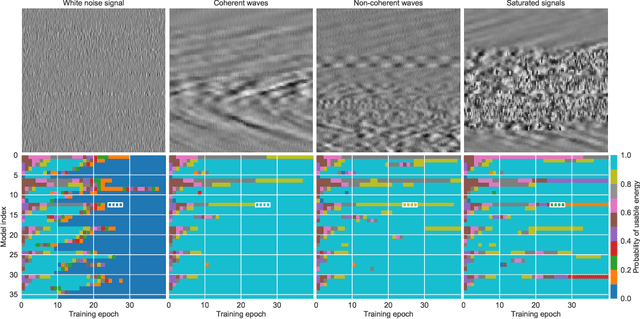
Moving loads such as cars and trains are very useful sources of seismic waves, which can be analyzed to retrieve information on the seismic velocity of subsurface materials using the techniques of ambient noise seismology. This information is valuable for a variety of applications such as geotechnical characterization of the near-surface, seismic hazard evaluation, and groundwater monitoring. However, for such processes to converge quickly, data segments with appropriate noise energy should be selected. Distributed Acoustic Sensing (DAS) is a novel sensing technique that enables acquisition of these data at very high spatial and temporal resolution for tens of kilometers. One major challenge when utilizing the DAS technology is the large volume of data that is produced, thereby presenting a significant Big Data challenge to find regions of useful energy. In this work, we present a highly scalable and efficient approach to process real, complex DAS data by integrating physics knowledge acquired during a data exploration phase followed by deep supervised learning to identify "useful" coherent surface waves generated by anthropogenic activity, a class of seismic waves that is abundant on these recordings and is useful for geophysical imaging. Data exploration and training were done on 130~Gigabytes (GB) of DAS measurements. Using parallel computing, we were able to do inference on an additional 170~GB of data (or the equivalent of 10 days' worth of recordings) in less than 30 minutes. Our method provides interpretable patterns describing the interaction of ground-based human activities with the buried sensors.