 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Embedding is Not All You Need: Attention Control for Text-to-Image Semantic Alignment with Text Self-Attention Maps
Nov 21, 2024



In text-to-image diffusion models, the cross-attention map of each text token indicates the specific image regions attended. Comparing these maps of syntactically related tokens provides insights into how well the generated image reflects the text prompt. For example, in the prompt, "a black car and a white clock", the cross-attention maps for "black" and "car" should focus on overlapping regions to depict a black car, while "car" and "clock" should not. Incorrect overlapping in the maps generally produces generation flaws such as missing objects and incorrect attribute binding. Our study makes the key observations investigating this issue in the existing text-to-image models:(1) the similarity in text embeddings between different tokens -- used as conditioning inputs -- can cause their cross-attention maps to focus on the same image regions; and (2) text embeddings often fail to faithfully capture syntactic relations already within text attention maps. As a result, such syntactic relationships can be overlooked in cross-attention module, leading to inaccurate image generation. To address this, we propose a method that directly transfers syntactic relations from the text attention maps to the cross-attention module via a test-time optimization. Our approach leverages this inherent yet unexploited information within text attention maps to enhance image-text semantic alignment across diverse prompts, without relying on external guidance.
Constructing Concept-based Models to Mitigate Spurious Correlations with Minimal Human Effort
Jul 12, 2024
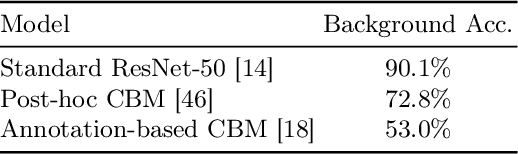


Enhancing model interpretability can address spurious correlations by revealing how models draw their predictions. Concept Bottleneck Models (CBMs) can provide a principled way of disclosing and guiding model behaviors through human-understandable concepts, albeit at a high cost of human efforts in data annotation. In this paper, we leverage a synergy of multiple foundation models to construct CBMs with nearly no human effort. We discover undesirable biases in CBMs built on pre-trained models and propose a novel framework designed to exploit pre-trained models while being immune to these biases, thereby reducing vulnerability to spurious correlations. Specifically, our method offers a seamless pipeline that adopts foundation models for assessing potential spurious correlations in datasets, annotating concepts for images, and refining the annotations for improved robustness. We evaluate the proposed method on multiple datasets, and the results demonstrate its effectiveness in reducing model reliance on spurious correlations while preserving its interpretability.
Model-Agnostic Human Preference Inversion in Diffusion Models
Apr 01, 2024Efficient text-to-image generation remains a challenging task due to the high computational costs associated with the multi-step sampling in diffusion models. Although distillation of pre-trained diffusion models has been successful in reducing sampling steps, low-step image generation often falls short in terms of quality. In this study, we propose a novel sampling design to achieve high-quality one-step image generation aligning with human preferences, particularly focusing on exploring the impact of the prior noise distribution. Our approach, Prompt Adaptive Human Preference Inversion (PAHI), optimizes the noise distributions for each prompt based on human preferences without the need for fine-tuning diffusion models. Our experiments showcase that the tailored noise distributions significantly improve image quality with only a marginal increase in computational cost. Our findings underscore the importance of noise optimization and pave the way for efficient and high-quality text-to-image synthesis.
Extract Dynamic Information To Improve Time Series Modeling: a Case Study with Scientific Workflow
May 19, 2022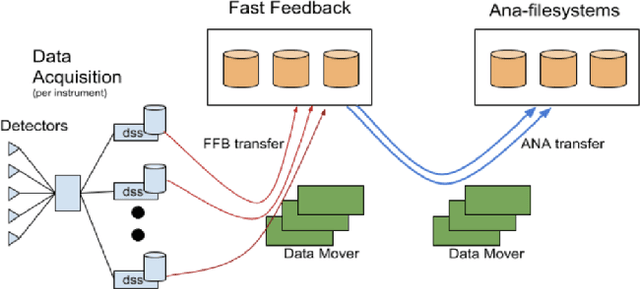
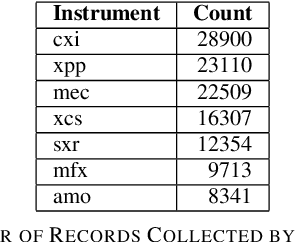
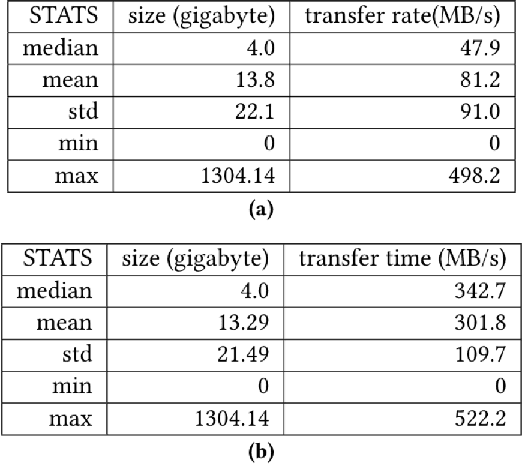

In modeling time series data, we often need to augment the existing data records to increase the modeling accuracy. In this work, we describe a number of techniques to extract dynamic information about the current state of a large scientific workflow, which could be generalized to other types of applications. The specific task to be modeled is the time needed for transferring a file from an experimental facility to a data center. The key idea of our approach is to find recent past data transfer events that match the current event in some ways. Tests showed that we could identify recent events matching some recorded properties and reduce the prediction error by about 12% compared to the similar models with only static features. We additionally explored an application specific technique to extract information about the data production process, and was able to reduce the average prediction error by 44%.
Improving Botnet Detection with Recurrent Neural Network and Transfer Learning
Apr 26, 2021
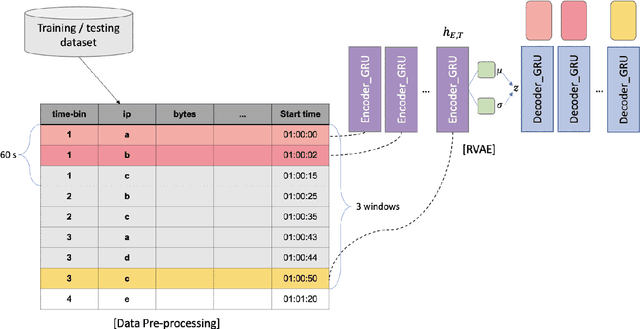
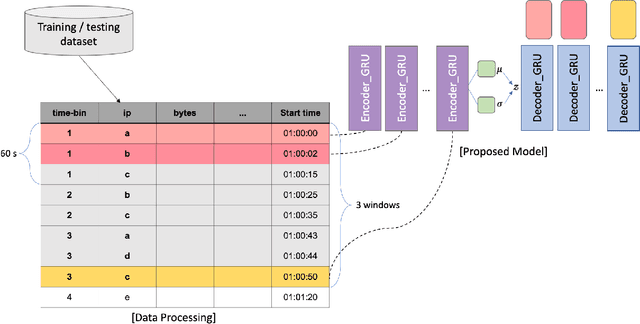
Botnet detection is a critical step in stopping the spread of botnets and preventing malicious activities. However, reliable detection is still a challenging task, due to a wide variety of botnets involving ever-increasing types of devices and attack vectors. Recent approaches employing machine learning (ML) showed improved performance than earlier ones, but these ML- based approaches still have significant limitations. For example, most ML approaches can not incorporate sequential pattern analysis techniques key to detect some classes of botnets. Another common shortcoming of ML-based approaches is the need to retrain neural networks in order to detect the evolving botnets; however, the training process is time-consuming and requires significant efforts to label the training data. For fast-evolving botnets, it might take too long to create sufficient training samples before the botnets have changed again. To address these challenges, we propose a novel botnet detection method, built upon Recurrent Variational Autoencoder (RVAE) that effectively captures sequential characteristics of botnet activities. In the experiment, this semi-supervised learning method achieves better detection accuracy than similar learning methods, especially on hard to detect classes. Additionally, we devise a transfer learning framework to learn from a well-curated source data set and transfer the knowledge to a target problem domain not seen before. Tests show that the true-positive rate (TPR) with transfer learning is higher than the RVAE semi-supervised learning method trained using the target data set (91.8% vs. 68.3%).
Botnet Detection Using Recurrent Variational Autoencoder
Apr 01, 2020

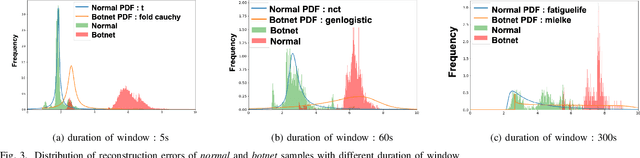
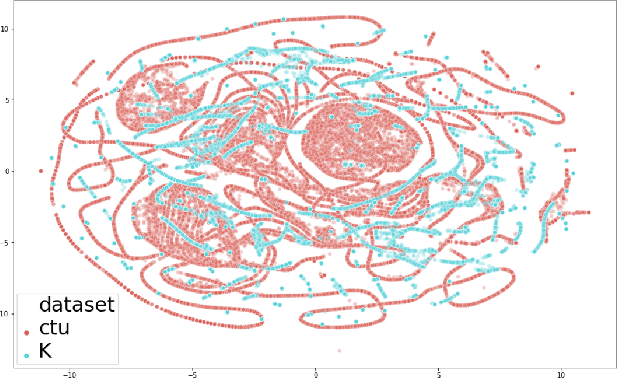
Botnets are increasingly used by malicious actors, creating increasing threat to a large number of internet users. To address this growing danger, we propose to study methods to detect botnets, especially those that are hard to capture with the commonly used methods, such as the signature based ones and the existing anomaly-based ones. More specifically, we propose a novel machine learning based method, named Recurrent Variational Autoencoder (RVAE), for detecting botnets through sequential characteristics of network traffic flow data including attacks by botnets. We validate robustness of our method with the CTU-13 dataset, where we have chosen the testing dataset to have different types of botnets than those of training dataset. Tests show that RVAE is able to detect botnets with the same accuracy as the best known results published in literature. In addition, we propose an approach to assign anomaly score based on probability distributions, which allows us to detect botnets in streaming mode as the new networking statistics becomes available. This on-line detection capability would enable real-time detection of unknown botnets.